Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations

0

Sign in to get full access
Overview
- This paper presents a comprehensive architectural framework for ensuring the trustworthiness, responsibility, and safety of artificial intelligence (AI) systems.
- It outlines key challenges in achieving trustworthy, responsible, and safe AI, and proposes mitigation strategies to address these challenges.
- The framework aims to guide the development of AI systems that are reliable, aligned with human values, and safe for deployment in real-world applications.
Plain English Explanation
The paper discusses the importance of developing [object Object],, ,[object Object],, and ,[object Object], AI systems. It recognizes that as AI becomes more advanced and ubiquitous, there are significant challenges in ensuring these systems behave reliably and in alignment with human values.
The authors propose a comprehensive architectural framework to address these challenges. This framework outlines key requirements and considerations for building AI systems that are trustworthy, responsible, and safe. For example, the system should be transparent in how it makes decisions, be aligned with human values, and have robust safeguards to prevent unintended or harmful behavior.
The paper also identifies specific challenges that must be addressed, such as ensuring the reliability of AI systems, maintaining human control and oversight, and mitigating the risks of advanced AI capabilities. It then proposes various mitigation strategies to tackle these challenges, such as implementing rigorous testing and validation procedures, incorporating ethical principles into the system design, and developing mechanisms for human-AI collaboration and oversight.
The goal of this framework is to guide the development of AI systems that are reliable, aligned with human values, and safe for real-world deployment, ultimately contributing to the responsible advancement of AI technology.
Technical Explanation
The paper presents a comprehensive architectural framework for ensuring the trustworthiness, responsibility, and safety of AI systems. The framework outlines key requirements and considerations for building AI systems that are reliable, aligned with human values, and have robust safeguards to prevent unintended or harmful behavior.
The authors identify several key challenges in achieving trustworthy, responsible, and safe AI, including:
- Reliability: Ensuring the consistency and predictability of AI system behavior, even in the face of complex or dynamic environments.
- Value Alignment: Ensuring that AI systems are aligned with human values and goals, and do not pursue objectives that are harmful or undesirable from a human perspective.
- Human Control and Oversight: Maintaining appropriate human control and oversight over AI systems, particularly as their capabilities become more advanced.
- Robustness and Resilience: Ensuring that AI systems are resilient to various types of failures, attacks, or unexpected inputs, and can gracefully degrade or recover in the face of such challenges.
To address these challenges, the framework proposes several mitigation strategies, including:
- Rigorous Testing and Validation: Implementing comprehensive testing and validation procedures to assess the reliability, safety, and robustness of AI systems before deployment.
- Ethical Principles and Value Alignment: Incorporating ethical principles and value alignment mechanisms into the system design, such as reward modeling, inverse reward design, and value learning.
- Human-AI Collaboration and Oversight: Developing mechanisms for human-AI collaboration and oversight, such as human-in-the-loop decision-making, interpretability, and explainability features.
- Adversarial Robustness and Failure Handling: Implementing techniques to improve the robustness of AI systems to adversarial attacks, edge cases, and unexpected inputs, as well as mechanisms for graceful degradation and recovery.
The authors emphasize that achieving trustworthy, responsible, and safe AI is a complex and multifaceted challenge, requiring a comprehensive and holistic approach. The proposed framework aims to provide a structured way to address these challenges and guide the development of AI systems that are reliable, aligned with human values, and safe for real-world deployment.
Critical Analysis
The paper presents a well-structured and comprehensive framework for addressing the important challenge of ensuring the trustworthiness, responsibility, and safety of AI systems. The authors have identified key issues that must be addressed, such as reliability, value alignment, human control, and robustness, and have proposed a range of mitigation strategies to tackle these challenges.
One potential limitation of the framework is that it may not fully capture the breadth and complexity of the challenges involved in achieving truly trustworthy and safe AI. As AI systems become more advanced and autonomous, the task of maintaining human control and oversight becomes increasingly difficult, and there may be unforeseen challenges that arise.
Additionally, the paper does not delve deeply into the specific technical details and implementation challenges associated with some of the proposed mitigation strategies, such as value alignment and adversarial robustness. Further research and exploration may be needed to fully understand the practical implications and feasibility of these approaches.
That said, the framework presented in this paper represents a valuable contribution to the ongoing efforts to ensure the responsible development and deployment of AI technology. By highlighting key considerations and providing a structured approach, the authors have laid the groundwork for continued research and innovation in this critical area.
Conclusion
This paper presents a comprehensive architectural framework for ensuring the trustworthiness, responsibility, and safety of AI systems. The framework outlines key challenges, such as reliability, value alignment, human control, and robustness, and proposes mitigation strategies to address these challenges.
The goal of this framework is to guide the development of AI systems that are reliable, aligned with human values, and safe for real-world deployment. By addressing these critical issues, the authors aim to contribute to the responsible advancement of AI technology and its safe integration into various domains.
While the framework may not capture the full breadth and complexity of the challenges involved, it represents an important step forward in the ongoing effort to ensure the trustworthiness and safety of AI systems. Continued research and exploration in this area will be crucial as AI technology continues to evolve and become more ubiquitous in our lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations
Chen Chen, Ziyao Liu, Weifeng Jiang, Si Qi Goh, Kwok-Yan Lam
AI Safety is an emerging area of critical importance to the safe adoption and deployment of AI systems. With the rapid proliferation of AI and especially with the recent advancement of Generative AI (or GAI), the technology ecosystem behind the design, development, adoption, and deployment of AI systems has drastically changed, broadening the scope of AI Safety to address impacts on public safety and national security. In this paper, we propose a novel architectural framework for understanding and analyzing AI Safety; defining its characteristics from three perspectives: Trustworthy AI, Responsible AI, and Safe AI. We provide an extensive review of current research and advancements in AI safety from these perspectives, highlighting their key challenges and mitigation approaches. Through examples from state-of-the-art technologies, particularly Large Language Models (LLMs), we present innovative mechanism, methodologies, and techniques for designing and testing AI safety. Our goal is to promote advancement in AI safety research, and ultimately enhance people's trust in digital transformation.
Read more9/14/2024
2
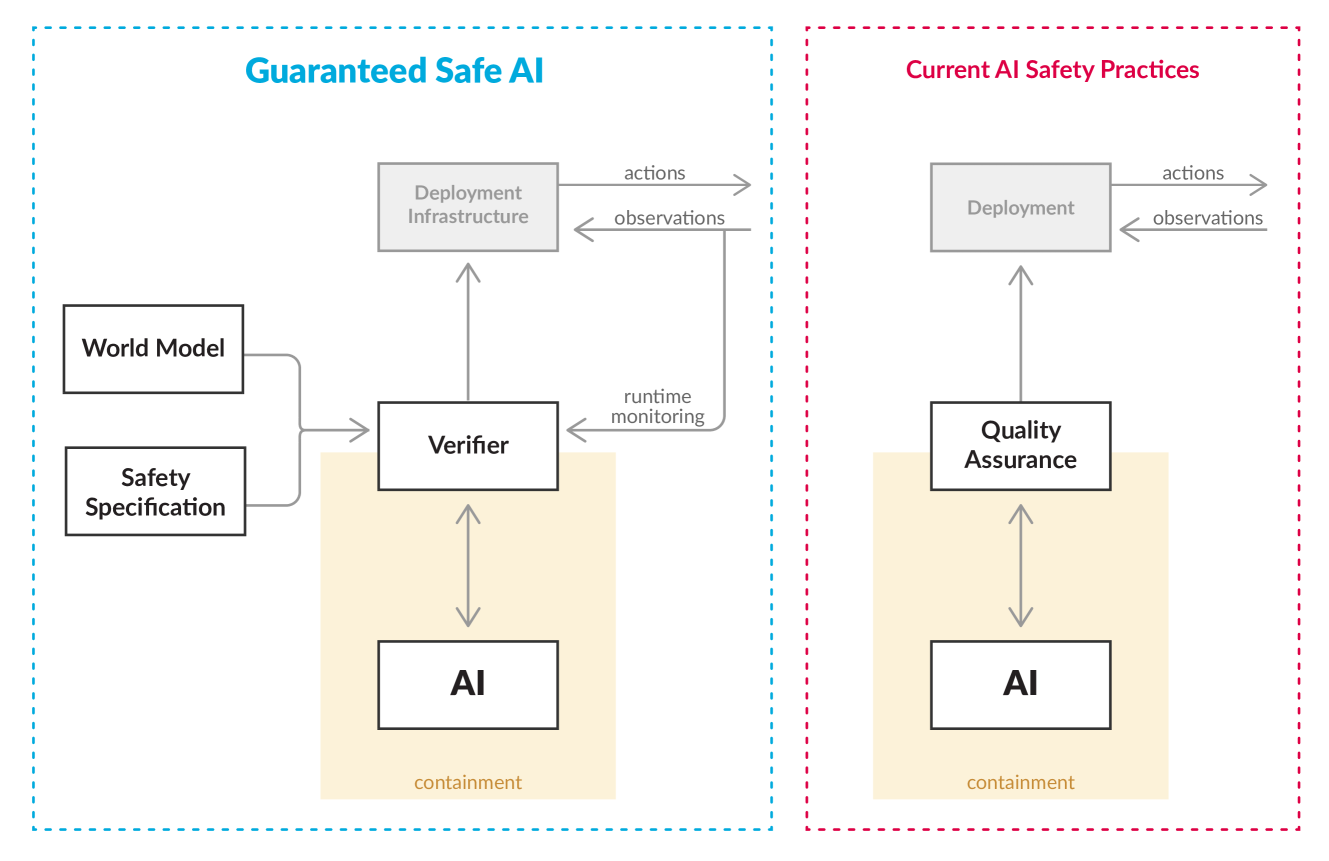
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Read more7/9/2024
🤖
0
Safeguarding AI Agents: Developing and Analyzing Safety Architectures
Ishaan Domkundwar, Mukunda N S, Ishaan Bhola
AI agents, specifically powered by large language models, have demonstrated exceptional capabilities in various applications where precision and efficacy are necessary. However, these agents come with inherent risks, including the potential for unsafe or biased actions, vulnerability to adversarial attacks, lack of transparency, and tendency to generate hallucinations. As AI agents become more prevalent in critical sectors of the industry, the implementation of effective safety protocols becomes increasingly important. This paper addresses the critical need for safety measures in AI systems, especially ones that collaborate with human teams. We propose and evaluate three frameworks to enhance safety protocols in AI agent systems: an LLM-powered input-output filter, a safety agent integrated within the system, and a hierarchical delegation-based system with embedded safety checks. Our methodology involves implementing these frameworks and testing them against a set of unsafe agentic use cases, providing a comprehensive evaluation of their effectiveness in mitigating risks associated with AI agent deployment. We conclude that these frameworks can significantly strengthen the safety and security of AI agent systems, minimizing potential harmful actions or outputs. Our work contributes to the ongoing effort to create safe and reliable AI applications, particularly in automated operations, and provides a foundation for developing robust guardrails to ensure the responsible use of AI agents in real-world applications.
Read more9/16/2024
0
The Journey to Trustworthy AI- Part 1: Pursuit of Pragmatic Frameworks
Mohamad M Nasr-Azadani, Jean-Luc Chatelain
This paper reviews Trustworthy Artificial Intelligence (TAI) and its various definitions. Considering the principles respected in any society, TAI is often characterized by a few attributes, some of which have led to confusion in regulatory or engineering contexts. We argue against using terms such as Responsible or Ethical AI as substitutes for TAI. And to help clarify any confusion, we suggest leaving them behind. Given the subjectivity and complexity inherent in TAI, developing a universal framework is deemed infeasible. Instead, we advocate for approaches centered on addressing key attributes and properties such as fairness, bias, risk, security, explainability, and reliability. We examine the ongoing regulatory landscape, with a focus on initiatives in the EU, China, and the USA. We recognize that differences in AI regulations based on geopolitical and geographical reasons pose an additional challenge for multinational companies. We identify risk as a core factor in AI regulation and TAI. For example, as outlined in the EU-AI Act, organizations must gauge the risk level of their AI products to act accordingly (or risk hefty fines). We compare modalities of TAI implementation and how multiple cross-functional teams are engaged in the overall process. Thus, a brute force approach for enacting TAI renders its efficiency and agility, moot. To address this, we introduce our framework Set-Formalize-Measure-Act (SFMA). Our solution highlights the importance of transforming TAI-aware metrics, drivers of TAI, stakeholders, and business/legal requirements into actual benchmarks or tests. Finally, over-regulation driven by panic of powerful AI models can, in fact, harm TAI too. Based on GitHub user-activity data, in 2023, AI open-source projects rose to top projects by contributor account. Enabling innovation in TAI hinges on the independent contributions of the open-source community.
Read more4/9/2024