SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
2406.10118
1
0

Abstract
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
Create account to get full access
Overview
• SEACrowd is a multilingual and multimodal data hub and benchmark suite for Southeast Asian languages. • It provides a diverse dataset and standardized evaluation tasks to advance natural language processing (NLP) and multimodal research in this underrepresented region. • The dataset covers a range of modalities, including text, images, and speech, across 11 Southeast Asian languages. • The benchmark suite includes tasks like language identification, machine translation, and visual question answering, designed to assess model capabilities in real-world applications.
Plain English Explanation
SEACrowd is a new resource that aims to help researchers and developers create better artificial intelligence (AI) systems for Southeast Asian languages. This region is often overlooked in AI development, so SEACrowd provides a large, diverse dataset and a set of standardized tests to evaluate how well AI models can handle tasks in these languages.
The dataset includes text, images, and speech data across 11 different Southeast Asian languages, like Thai, Vietnamese, and Indonesian. Researchers can use this data to train AI models to do things like translate between languages, answer questions about images, or identify which language is being used.
The benchmark suite includes a variety of tasks that test different capabilities of AI models, like being able to accurately translate text or answer questions about visual information. These tests are designed to mimic real-world applications, so developers can see how their models would perform in practical situations.
By providing this comprehensive dataset and set of benchmarks, SEACrowd hopes to spur more research and development of AI systems that work well for Southeast Asian languages. This could lead to better digital tools and services for the hundreds of millions of people who speak these languages.
Technical Explanation
The SEACrowd dataset and benchmark suite is organized around 11 Southeast Asian languages: Bahasa Indonesia, Bahasa Malaysia, Burmese, Khmer, Lao, Maranao, Pangasinan, Tagalog, Thai, Tausug, and Vietnamese. It contains text data from web pages, social media, and other online sources, as well as images and speech recordings.
The benchmark suite includes the following tasks:
- Language identification: Classify the language of a given text sample.
- Machine translation: Translate text between pairs of Southeast Asian languages.
- Visual question answering: Answer questions about the content of images.
- Socioeconomic estimation: Predict socioeconomic indicators for a geographic region based on text and image data.
The dataset and benchmark suite were developed by researchers from institutions across Southeast Asia, in collaboration with partners from Europe and the United States. They used a range of techniques, including web crawling, crowdsourcing, and expert annotations, to collect and curate the data.
Critical Analysis
One potential limitation of the SEACrowd dataset is the representativeness of the text data, which is primarily drawn from online sources. This may not fully capture the linguistic diversity and real-world usage of these languages. The researchers acknowledge this and suggest incorporating more ethnographic data collection methods in the future.
Additionally, the benchmark tasks, while designed to be realistic, may not fully reflect the nuanced requirements of practical applications. For example, the visual question answering task focuses on factual questions, but real-world use cases may involve more open-ended or subjective queries.
Further research could also explore the robustness and generalizability of models trained on the SEACrowd data, particularly in the face of speech enhancement challenges or cross-lingual transfer tasks.
Conclusion
The SEACrowd dataset and benchmark suite represent an important step towards advancing natural language processing and multimodal AI research in Southeast Asia. By providing a comprehensive, standardized resource, the project aims to catalyze more work in this underserved region and contribute to the development of culturally-aware and linguistically-inclusive AI systems.
The dataset and benchmark tasks cover a wide range of modalities and applications, offering researchers and developers valuable tools to test the capabilities of their models. As the project continues to evolve, incorporating feedback and expanding its scope, it has the potential to drive significant progress in making AI more accessible and beneficial for Southeast Asian communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
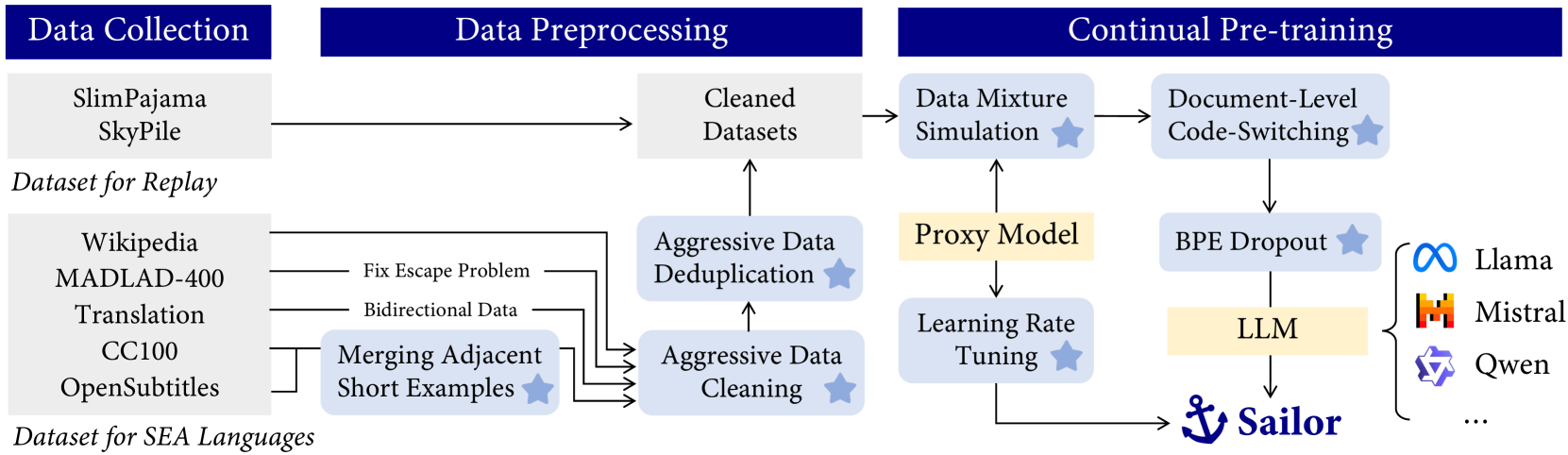
Sailor: Open Language Models for South-East Asia
Longxu Dou, Qian Liu, Guangtao Zeng, Jia Guo, Jiahui Zhou, Wei Lu, Min Lin
0
0
We present Sailor, a family of open language models ranging from 0.5B to 7B parameters, tailored for South-East Asian (SEA) languages. These models are continually pre-trained from Qwen1.5, a great language model for multilingual use cases. From Qwen1.5, Sailor models accept 200B to 400B tokens, primarily covering the languages of English, Chinese, Vietnamese, Thai, Indonesian, Malay, and Lao. The training leverages several techniques, including BPE dropout for improving the model robustness, aggressive data cleaning and deduplication, and small proxy models to optimize data mixture. Experimental results on four typical tasks indicate that Sailor models demonstrate strong performance across different benchmarks, including commonsense reasoning, question answering, reading comprehension and examination. Embracing the open-source spirit, we share our insights through this report to spark a wider interest in developing large language models for multilingual use cases.
4/5/2024

Compass: Large Multilingual Language Model for South-east Asia
Sophia Maria
0
0
Large language models have exhibited significant proficiency in languages endowed with extensive linguistic resources, such as English and Chinese. Nevertheless, their effectiveness notably diminishes when applied to languages characterized by limited linguistic resources, particularly within the Southeast Asian linguistic landscape, such as Indonesian. The scarcity of linguistic resources for these languages presents challenges associated with inadequate training, restricted vocabulary coverage, and challenging evaluation processes. In response to these exigencies, we have introduced CompassLLM, a large multilingual model specifically tailored for Southeast Asian languages, with the primary aim of supporting the developmental requirements of Shopee. Our methodology encompasses several key strategies. To progressively enhance multilingual proficiencies, we implemented a multi-stage pre-training strategy integrated with curriculum learning, gradually intensifying the focus on low-resource languages. Concurrently, to better accommodate low-resource human instructions, we curated and generated a repository of high-quality multilingual human instructions, culminating the CompassLLM-SFT model through supervised instruction fine-tuning. Finally, to reinforce the model's alignment with human preference behaviors, we have embraced the principle of Direct Preference Optimization (DPO) to obtain CompassLLM-DPO model. Preliminary evaluation of the CompassLLM model yields promising results, with our model surpassing benchmark models like Vicuna-7b-v1.5, Sealion, Falcon and SeaLLM, across diverse evaluation tasks, as verified through both automated and human-driven assessments. Notably, our model exhibits its superior performance in South-east Asia languages, such as Indonesian language.
4/16/2024
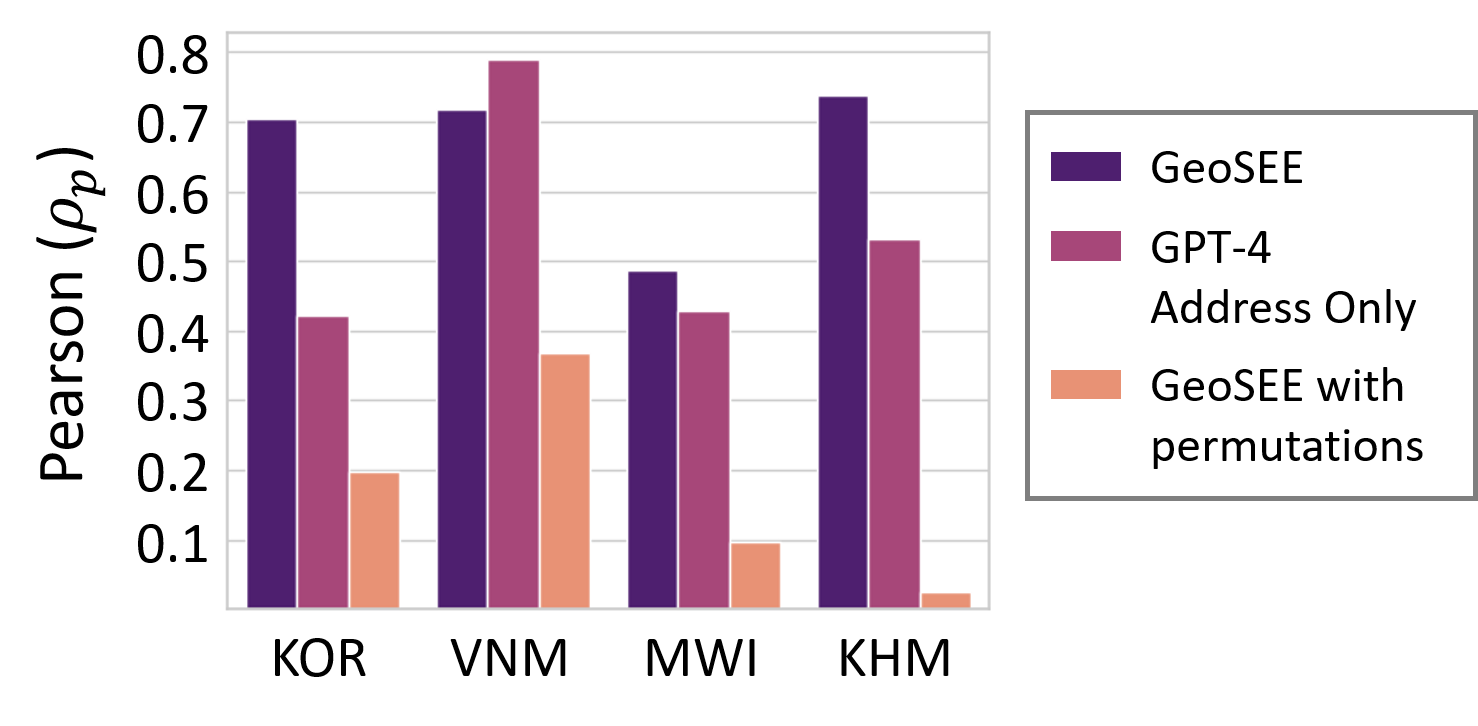
GeoSEE: Regional Socio-Economic Estimation With a Large Language Model
Sungwon Han, Donghyun Ahn, Seungeon Lee, Minhyuk Song, Sungwon Park, Sangyoon Park, Jihee Kim, Meeyoung Cha
0
0
Moving beyond traditional surveys, combining heterogeneous data sources with AI-driven inference models brings new opportunities to measure socio-economic conditions, such as poverty and population, over expansive geographic areas. The current research presents GeoSEE, a method that can estimate various socio-economic indicators using a unified pipeline powered by a large language model (LLM). Presented with a diverse set of information modules, including those pre-constructed from satellite imagery, GeoSEE selects which modules to use in estimation, for each indicator and country. This selection is guided by the LLM's prior socio-geographic knowledge, which functions similarly to the insights of a domain expert. The system then computes target indicators via in-context learning after aggregating results from selected modules in the format of natural language-based texts. Comprehensive evaluation across countries at various stages of development reveals that our method outperforms other predictive models in both unsupervised and low-shot contexts. This reliable performance under data-scarce setting in under-developed or developing countries, combined with its cost-effectiveness, underscores its potential to continuously support and monitor the progress of Sustainable Development Goals, such as poverty alleviation and equitable growth, on a global scale.
6/17/2024

CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
David Romero, Chenyang Lyu, Haryo Akbarianto Wibowo, Teresa Lynn, Injy Hamed, Aditya Nanda Kishore, Aishik Mandal, Alina Dragonetti, Artem Abzaliev, Atnafu Lambebo Tonja, Bontu Fufa Balcha, Chenxi Whitehouse, Christian Salamea, Dan John Velasco, David Ifeoluwa Adelani, David Le Meur, Emilio Villa-Cueva, Fajri Koto, Fauzan Farooqui, Frederico Belcavello, Ganzorig Batnasan, Gisela Vallejo, Grainne Caulfield, Guido Ivetta, Haiyue Song, Henok Biadglign Ademtew, Hern'an Maina, Holy Lovenia, Israel Abebe Azime, Jan Christian Blaise Cruz, Jay Gala, Jiahui Geng, Jesus-German Ortiz-Barajas, Jinheon Baek, Jocelyn Dunstan, Laura Alonso Alemany, Kumaranage Ravindu Yasas Nagasinghe, Luciana Benotti, Luis Fernando D'Haro, Marcelo Viridiano, Marcos Estecha-Garitagoitia, Maria Camila Buitrago Cabrera, Mario Rodr'iguez-Cantelar, M'elanie Jouitteau, Mihail Mihaylov, Mohamed Fazli Mohamed Imam, Muhammad Farid Adilazuarda, Munkhjargal Gochoo, Munkh-Erdene Otgonbold, Naome Etori, Olivier Niyomugisha, Paula M'onica Silva, Pranjal Chitale, Raj Dabre, Rendi Chevi, Ruochen Zhang, Ryandito Diandaru, Samuel Cahyawijaya, Santiago G'ongora, Soyeong Jeong, Sukannya Purkayastha, Tatsuki Kuribayashi, Thanmay Jayakumar, Tiago Timponi Torrent, Toqeer Ehsan, Vladimir Araujo, Yova Kementchedjhieva, Zara Burzo, Zheng Wei Lim, Zheng Xin Yong, Oana Ignat, Joan Nwatu, Rada Mihalcea, Thamar Solorio, Alham Fikri Aji
0
0
Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
6/11/2024