SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR

0
Sign in to get full access
Overview
- This paper introduces SAML, a Speaker Adaptive Mixture of LoRA Experts for End-to-End Automatic Speech Recognition (ASR).
- SAML combines the benefits of Mixture of LoRA Experts and Adaptive LoRA to create a speaker-adaptive ASR model.
- The key idea is to use a mixture of speaker-specific LoRA experts to adapt the base ASR model to different speakers, improving performance.
Plain English Explanation
The paper describes a new approach for automatic speech recognition (ASR) that can adapt to different speakers. ASR is the technology that allows computers to transcribe spoken language into text.
The researchers developed a model called SAML, which stands for Speaker Adaptive Mixture of LoRA Experts. LoRA is a technique for efficiently fine-tuning large language models like the one used for ASR. SAML combines LoRA with the idea of having a "mixture of experts" - multiple specialized models that work together.
The key innovation is that SAML has multiple LoRA expert models, each tailored to a specific speaker. When processing speech from a new speaker, SAML can dynamically select the appropriate expert model to use, allowing it to adapt to that speaker's voice and speaking style. This helps improve the accuracy of the speech transcription.
By combining speaker adaptation with the efficiency of LoRA, SAML can achieve high-quality ASR performance while using relatively little additional training data or compute resources compared to a one-size-fits-all model.
Technical Explanation
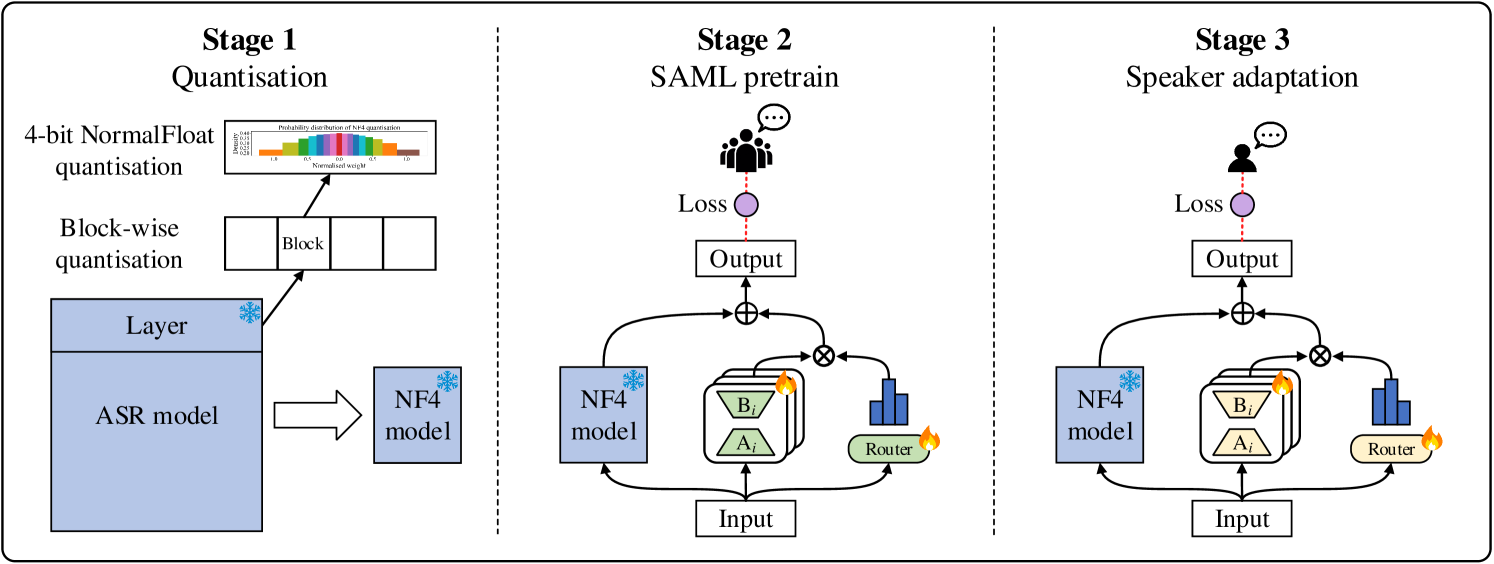
The paper proposes the SAML architecture, which builds on two recent advancements in efficient model fine-tuning: Mixture of LoRA Experts and Adaptive LoRA.
The key idea is to have a base ASR model that is then adapted to different speakers using a mixture of speaker-specific LoRA experts. Each LoRA expert learns the specific acoustic and linguistic patterns of a particular speaker, and the mixture mechanism dynamically selects the appropriate expert(s) when processing a new speech sample.
The researchers evaluate SAML on several benchmark ASR datasets, comparing it to prior state-of-the-art approaches like LoRA-Whisper and MALA-ASR. They show that SAML can achieve higher accuracy while using fewer parameters and less training data than these baselines.
Critical Analysis
The paper provides a thorough evaluation of SAML and demonstrates its effectiveness, but there are a few areas that could be explored further:
- The authors mention that SAML may not be as effective for speakers with very limited training data. Investigating ways to better handle low-resource speakers would be an interesting direction.
- The paper focuses on English ASR, but it would be valuable to see how well SAML generalizes to other languages and accents.
- While the mixture of experts approach is novel, the authors do not provide much insight into the inner workings of this mechanism. A deeper analysis of how the experts collaborate and what types of speaker variations they each specialize in could lead to further improvements.
Overall, SAML represents an exciting advance in speaker-adaptive ASR that balances performance, efficiency, and flexibility. The critical analysis suggests opportunities for future research to build upon this work.
Conclusion
The SAML paper introduces a novel approach for end-to-end automatic speech recognition that can adapt to different speakers. By combining the efficiency of LoRA fine-tuning with a mixture of speaker-specific expert models, SAML achieves state-of-the-art ASR performance while using fewer parameters and less training data than previous methods.
This work demonstrates the power of speaker adaptation in ASR and highlights the potential for similar techniques to enhance the personalization and robustness of other language models and AI assistants. As the demand for high-quality, customizable voice interfaces continues to grow, innovations like SAML will play a crucial role in making this technology more accessible and useful for diverse users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR
Qiuming Zhao, Guangzhi Sun, Chao Zhang, Mingxing Xu, Thomas Fang Zheng
Mixture-of-experts (MoE) models have achieved excellent results in many tasks. However, conventional MoE models are often very large, making them challenging to deploy on resource-constrained edge devices. In this paper, we propose a novel speaker adaptive mixture of LoRA experts (SAML) approach, which uses low-rank adaptation (LoRA) modules as experts to reduce the number of trainable parameters in MoE. Specifically, SAML is applied to the quantised and personalised end-to-end automatic speech recognition models, which combines test-time speaker adaptation to improve the performance of heavily compressed models in speaker-specific scenarios. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size, 29.1% and 31.1% relative word error rate reductions were achieved on the quantised Whisper model and Conformer-based attention-based encoder-decoder ASR model respectively, comparing to the original full precision models.
Read more7/1/2024

0
Retrieval-Augmented Mixture of LoRA Experts for Uploadable Machine Learning
Ziyu Zhao, Leilei Gan, Guoyin Wang, Yuwei Hu, Tao Shen, Hongxia Yang, Kun Kuang, Fei Wu
Low-Rank Adaptation (LoRA) offers an efficient way to fine-tune large language models (LLMs). Its modular and plug-and-play nature allows the integration of various domain-specific LoRAs, enhancing LLM capabilities. Open-source platforms like Huggingface and Modelscope have introduced a new computational paradigm, Uploadable Machine Learning (UML). In UML, contributors use decentralized data to train specialized adapters, which are then uploaded to a central platform to improve LLMs. This platform uses these domain-specific adapters to handle mixed-task requests requiring personalized service. Previous research on LoRA composition either focuses on specific tasks or fixes the LoRA selection during training. However, in UML, the pool of LoRAs is dynamically updated with new uploads, requiring a generalizable selection mechanism for unseen LoRAs. Additionally, the mixed-task nature of downstream requests necessitates personalized services. To address these challenges, we propose Retrieval-Augmented Mixture of LoRA Experts (RAMoLE), a framework that adaptively retrieves and composes multiple LoRAs based on input prompts. RAMoLE has three main components: LoraRetriever for identifying and retrieving relevant LoRAs, an on-the-fly MoLE mechanism for coordinating the retrieved LoRAs, and efficient batch inference for handling heterogeneous requests. Experimental results show that RAMoLE consistently outperforms baselines, highlighting its effectiveness and scalability.
Read more7/17/2024
💬
0
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, Mingjie Tang
Fine-tuning Large Language Models (LLMs) is a common practice to adapt pre-trained models for specific applications. While methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multi-task scenarios. In contrast, Mixture-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance in multi-task learning scenarios while maintaining a reduced parameter count. However, the resource requirements of these MoEs remain challenging, particularly for consumer-grade GPUs with less than 24GB memory. To tackle these challenges, we propose MixLoRA, an approach to construct a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model and employs a commonly used top-k router. Unlike other LoRA-based MoE methods, MixLoRA enhances model performance by utilizing independent attention-layer LoRA adapters. Additionally, an auxiliary load balance loss is employed to address the imbalance problem of the router. Our evaluations show that MixLoRA improves about 9% accuracy compared to state-of-the-art PEFT methods in multi-task learning scenarios. We also propose a new high-throughput framework to alleviate the computation and memory bottlenecks during the training and inference of MOE models. This framework reduces GPU memory consumption by 40% and token computation latency by 30% during both training and inference.
Read more7/23/2024
💬
0
AdaMoLE: Fine-Tuning Large Language Models with Adaptive Mixture of Low-Rank Adaptation Experts
Zefang Liu, Jiahua Luo
We introduce AdaMoLE, a novel method for fine-tuning large language models (LLMs) through an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts. Moving beyond conventional methods that employ a static top-k strategy for activating experts, AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network, adaptively responding to the varying complexities of different tasks. By replacing a single LoRA in a layer with multiple LoRA experts and integrating a gating function with the threshold mechanism, AdaMoLE effectively selects and activates the most appropriate experts based on the input context. Our extensive evaluations across a variety of commonsense reasoning and natural language processing tasks show that AdaMoLE exceeds baseline performance. This enhancement highlights the advantages of AdaMoLE's adaptive selection of LoRA experts, improving model effectiveness without a corresponding increase in the expert count. The experimental validation not only confirms AdaMoLE as a robust approach for enhancing LLMs but also suggests valuable directions for future research in adaptive expert selection mechanisms, potentially broadening the scope for optimizing model performance across diverse language processing tasks.
Read more8/13/2024