Sample Complexity of Variance-reduced Distributionally Robust Q-learning

0
🚀
Sign in to get full access
Overview
- Reinforcement learning models can be affected by shifts in the distribution of the environment during deployment compared to training.
- This paper presents two novel model-free algorithms to learn a robust policy despite such distributional shifts.
- The algorithms efficiently approximate a robust Q-function for an infinite-horizon, gamma-discounted Markov decision process with a Kullback-Leibler ambiguity set.
- The variance-reduced version combines Q-learning with variance reduction techniques for enhanced performance.
- The paper establishes a minimax sample complexity bound that is independent of the ambiguity size, providing new theoretical insights.
- Numerical experiments confirm the algorithms' effectiveness in handling distributional shifts.
Plain English Explanation
Reinforcement learning (RL) models are trained on data from a particular environment, but they may need to operate in a different environment when deployed. This can cause issues, as the distribution of the new environment may differ from the training environment.
To address this problem, the researchers developed two new RL algorithms that can learn a "robust" policy - one that performs well even when the environment changes. These algorithms approximate a special type of Q-function, which is a key component in many RL methods.
The first algorithm, Distributionally Robust Q-Learning, efficiently computes this robust Q-function. The second algorithm, Variance-Reduced Distributionally Robust Q-Learning, combines this with techniques to reduce the variance of the estimates, further improving performance.
Importantly, the paper shows that the second algorithm has a sample complexity (the number of samples required to learn a good policy) that does not depend on the size of the "ambiguity set" - a measure of how different the new environment can be from the training environment. This is a novel theoretical result, providing new insights into the challenges of dealing with distributional shifts in RL.
The researchers also demonstrate the effectiveness of their algorithms through numerical experiments, showing that they can handle distributional shifts better than standard RL methods.
Technical Explanation
The paper presents two novel model-free algorithms for Distributionally Robust Reinforcement Learning in infinite-horizon, gamma-discounted Markov Decision Processes (MDPs).
The first algorithm, Distributionally Robust Q-Learning, efficiently approximates the robust Q-function of the MDP, which is the optimal value function under a Kullback-Leibler ambiguity set. This allows the agent to learn a policy that performs well even when the environment changes during deployment.
The second algorithm, Variance-Reduced Distributionally Robust Q-Learning, combines the synchronous Q-learning update with variance reduction techniques to enhance the performance of the first algorithm.
The paper establishes a minimax sample complexity upper bound for the second algorithm that is independent of the ambiguity size, which is a novel theoretical result. This provides new insights into the sample complexity of Distributionally Robust RL.
The numerical experiments confirm the theoretical findings and demonstrate the effectiveness of the proposed algorithms in handling distributional shifts compared to standard RL methods.
Critical Analysis
The paper presents a thorough theoretical analysis of the proposed algorithms, including establishing sample complexity bounds. However, the authors do not discuss potential limitations or caveats of their approach.
For example, the algorithms assume access to a generative model of the environment, which may not be available in many real-world applications. Additionally, the performance guarantees are derived in an asymptotic sense, and it is unclear how the algorithms would perform in finite-sample regimes.
Furthermore, the paper does not compare the proposed methods to other approaches for handling distributional shifts, such as domain adaptation or robust optimization techniques. Exploring the relative strengths and weaknesses of different strategies for this problem would provide a more complete picture.
Lastly, the numerical experiments are limited to relatively simple benchmark tasks. Evaluating the algorithms on more complex, real-world problems would help assess their practical applicability and effectiveness in handling realistic distributional shifts.
Conclusion
This paper introduces two novel model-free algorithms for Distributionally Robust Reinforcement Learning, which can learn a robust policy despite shifts in the environment distribution between training and deployment.
The key contributions of the work include the efficient approximation of the robust Q-function, the incorporation of variance reduction techniques to enhance performance, and the establishment of a sample complexity bound that is independent of the ambiguity size - a novel theoretical result.
The proposed algorithms demonstrate promising empirical results in handling distributional shifts, but further research is needed to assess their limitations, compare them to alternative approaches, and evaluate their performance on more challenging real-world problems.
Overall, this paper advances the state of the art in reinforcement learning under distributional shifts, an important problem with significant practical implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Sample Complexity of Variance-reduced Distributionally Robust Q-learning
Shengbo Wang, Nian Si, Jose Blanchet, Zhengyuan Zhou
Dynamic decision-making under distributional shifts is of fundamental interest in theory and applications of reinforcement learning: The distribution of the environment in which the data is collected can differ from that of the environment in which the model is deployed. This paper presents two novel model-free algorithms, namely the distributionally robust Q-learning and its variance-reduced counterpart, that can effectively learn a robust policy despite distributional shifts. These algorithms are designed to efficiently approximate the $q$-function of an infinite-horizon $gamma$-discounted robust Markov decision process with Kullback-Leibler ambiguity set to an entry-wise $epsilon$-degree of precision. Further, the variance-reduced distributionally robust Q-learning combines the synchronous Q-learning with variance-reduction techniques to enhance its performance. Consequently, we establish that it attains a minimax sample complexity upper bound of $tilde O(|mathbf{S}||mathbf{A}|(1-gamma)^{-4}epsilon^{-2})$, where $mathbf{S}$ and $mathbf{A}$ denote the state and action spaces. This is the first complexity result that is independent of the ambiguity size $delta$, thereby providing new complexity theoretic insights. Additionally, a series of numerical experiments confirm the theoretical findings and the efficiency of the algorithms in handling distributional shifts.
Read more9/5/2024
🌐
0
A Finite Sample Complexity Bound for Distributionally Robust Q-learning
Shengbo Wang, Nian Si, Jose Blanchet, Zhengyuan Zhou
We consider a reinforcement learning setting in which the deployment environment is different from the training environment. Applying a robust Markov decision processes formulation, we extend the distributionally robust $Q$-learning framework studied in Liu et al. [2022]. Further, we improve the design and analysis of their multi-level Monte Carlo estimator. Assuming access to a simulator, we prove that the worst-case expected sample complexity of our algorithm to learn the optimal robust $Q$-function within an $epsilon$ error in the sup norm is upper bounded by $tilde O(|S||A|(1-gamma)^{-5}epsilon^{-2}p_{wedge}^{-6}delta^{-4})$, where $gamma$ is the discount rate, $p_{wedge}$ is the non-zero minimal support probability of the transition kernels and $delta$ is the uncertainty size. This is the first sample complexity result for the model-free robust RL problem. Simulation studies further validate our theoretical results.
Read more8/2/2024
🏅
0
The Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Matthieu Geist, Yuejie Chi
This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $chi^2$ divergence. The algorithm studied here is a model-based method called {em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
Read more4/15/2024
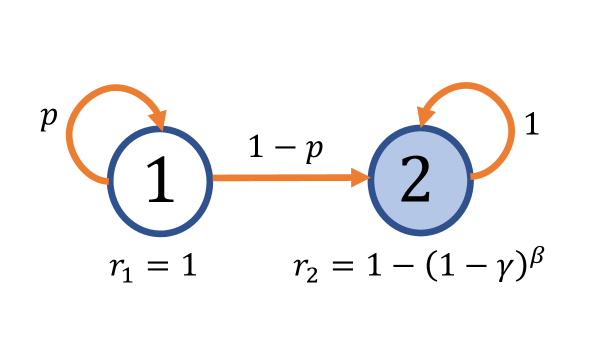
0
Variance-Reduced Cascade Q-learning: Algorithms and Sample Complexity
Mohammad Boveiri, Peyman Mohajerin Esfahani
We study the problem of estimating the optimal Q-function of $gamma$-discounted Markov decision processes (MDPs) under the synchronous setting, where independent samples for all state-action pairs are drawn from a generative model at each iteration. We introduce and analyze a novel model-free algorithm called Variance-Reduced Cascade Q-learning (VRCQ). VRCQ comprises two key building blocks: (i) the established direct variance reduction technique and (ii) our proposed variance reduction scheme, Cascade Q-learning. By leveraging these techniques, VRCQ provides superior guarantees in the $ell_infty$-norm compared with the existing model-free stochastic approximation-type algorithms. Specifically, we demonstrate that VRCQ is minimax optimal. Additionally, when the action set is a singleton (so that the Q-learning problem reduces to policy evaluation), it achieves non-asymptotic instance optimality while requiring the minimum number of samples theoretically possible. Our theoretical results and their practical implications are supported by numerical experiments.
Read more8/14/2024