Sample-Efficient Bayesian Optimization with Transfer Learning for Heterogeneous Search Spaces

0
🛠️
Sign in to get full access
Overview
- Provides a plain English summary and technical explanation of a research paper on the automl package.
- Includes a critical analysis of the paper's findings and limitations.
- Concludes with the main takeaways and potential implications of the research.
Plain English Explanation
The research paper discusses the automl package, which is a tool for automatically tuning machine learning models. The key idea is to make it easier for users to get good performance from machine learning models without having to manually tweak a lot of parameters.
The paper covers the different options and settings available in the automl package, as well as some supplementary materials that provide more details. It also includes a note about line numbering at the time of paper submission.
The main benefit of the automl package is that it can save users a lot of time and effort in building effective machine learning models. Instead of having to painstakingly test different model architectures, hyperparameters, and data preprocessing steps, the automl package can automatically explore this space and find a good configuration. This makes machine learning more accessible to a wider range of users, not just expert data scientists.
Technical Explanation
The paper provides a comprehensive overview of the package options available in automl, covering things like the different models that can be used, how to handle missing data, and options for model evaluation and selection.
The supplemental material includes additional technical details, such as the mathematical formulations and algorithms underlying the automl package. This gives users a deeper understanding of how the package works under the hood.
The note about line numbering is a minor but important detail, as it helps readers interpret the code examples and other references in the paper correctly.
Overall, the technical explanation provides a thorough documentation of the automl package, covering its features, capabilities, and implementation details. This will be valuable for users looking to effectively leverage the package in their own machine learning projects.
Critical Analysis
The paper does a good job of highlighting the key benefits and use cases for the automl package. However, it also acknowledges some potential limitations and areas for further research.
For example, the paper notes that the automl package may not be as effective for highly specialized or domain-specific machine learning problems. In these cases, manual feature engineering and model tuning by expert users may still be necessary.
Additionally, the paper suggests that the performance of the automl package could potentially be improved through the incorporation of transfer learning or multi-fidelity optimization techniques. These are interesting avenues for future work that could make the package even more powerful and widely applicable.
While the paper is generally well-designed and the research appears to be sound, there may be some additional concerns or limitations that are not explicitly discussed. Readers should think critically about the assumptions and constraints of the automl package and how they might impact its real-world usage.
Conclusion
The automl package represents an important step forward in making machine learning more accessible and user-friendly. By automating many of the tedious and time-consuming aspects of model development, the package has the potential to significantly lower the barrier to entry for a wide range of users.
The detailed documentation and technical explanation provided in this paper give users a thorough understanding of the package's capabilities and inner workings. This will help ensure that automl is used effectively and appropriately in a variety of applications.
While the package has some limitations, the research team has identified promising directions for future improvements. As the field of machine learning continues to evolve, tools like automl will play an increasingly critical role in accelerating the development and deployment of high-performance models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Sample-Efficient Bayesian Optimization with Transfer Learning for Heterogeneous Search Spaces
Aryan Deshwal, Sait Cakmak, Yuhou Xia, David Eriksson
Bayesian optimization (BO) is a powerful approach to sample-efficient optimization of black-box functions. However, in settings with very few function evaluations, a successful application of BO may require transferring information from historical experiments. These related experiments may not have exactly the same tunable parameters (search spaces), motivating the need for BO with transfer learning for heterogeneous search spaces. In this paper, we propose two methods for this setting. The first approach leverages a Gaussian process (GP) model with a conditional kernel to transfer information between different search spaces. Our second approach treats the missing parameters as hyperparameters of the GP model that can be inferred jointly with the other GP hyperparameters or set to fixed values. We show that these two methods perform well on several benchmark problems.
Read more9/10/2024
0
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Huong Ha, Vu Nguyen, Hung Tran-The, Hongyu Zhang, Xiuzhen Zhang, Anton van den Hengel
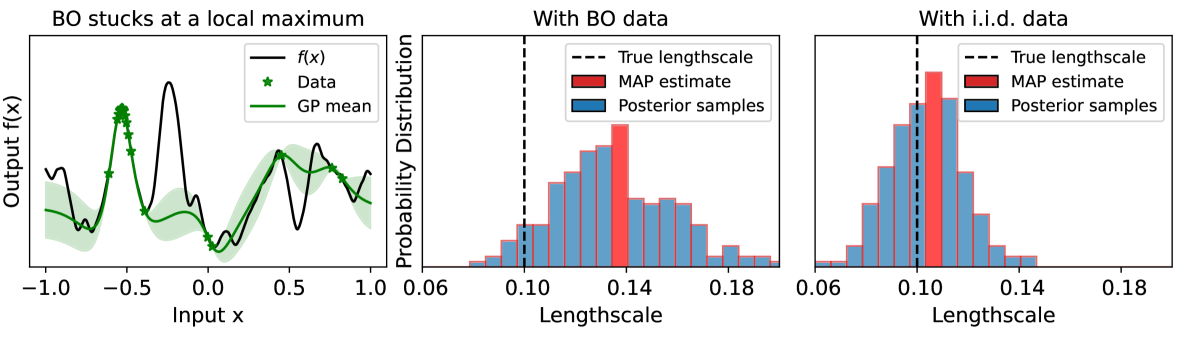
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Read more6/7/2024
0
Cost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
Dong Bok Lee, Aoxuan Silvia Zhang, Byungjoo Kim, Junhyeon Park, Juho Lee, Sung Ju Hwang, Hae Beom Lee
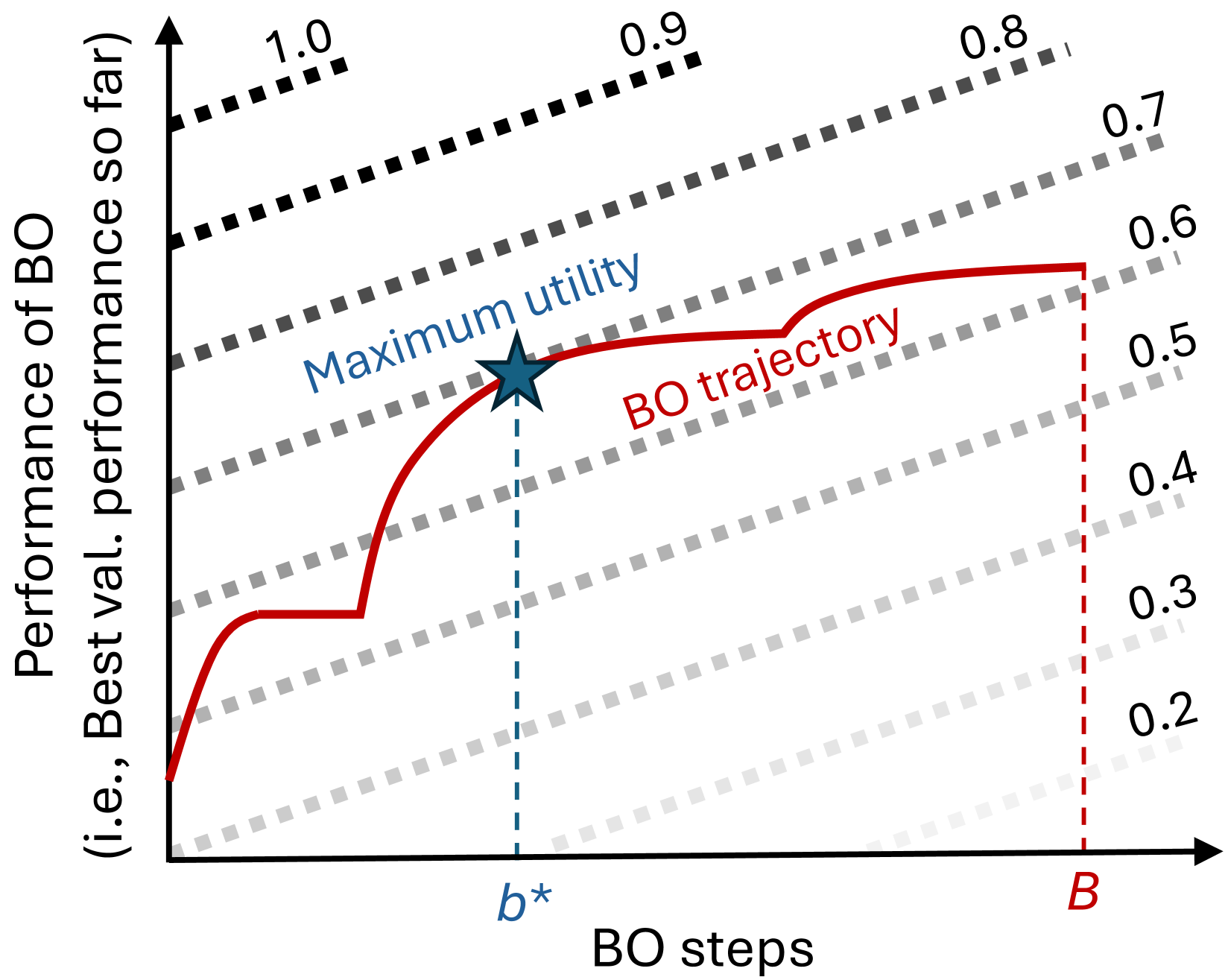
In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
Read more5/29/2024
🧠
0
Large-Batch, Iteration-Efficient Neural Bayesian Design Optimization
Navid Ansari, Alireza Javanmardi, Eyke Hullermeier, Hans-Peter Seidel, Vahid Babaei
Bayesian optimization (BO) provides a powerful framework for optimizing black-box, expensive-to-evaluate functions. It is therefore an attractive tool for engineering design problems, typically involving multiple objectives. Thanks to the rapid advances in fabrication and measurement methods as well as parallel computing infrastructure, querying many design problems can be heavily parallelized. This class of problems challenges BO with an unprecedented setup where it has to deal with very large batches, shifting its focus from sample efficiency to iteration efficiency. We present a novel Bayesian optimization framework specifically tailored to address these limitations. Our key contribution is a highly scalable, sample-based acquisition function that performs a non-dominated sorting of not only the objectives but also their associated uncertainty. We show that our acquisition function in combination with different Bayesian neural network surrogates is effective in data-intensive environments with a minimal number of iterations. We demonstrate the superiority of our method by comparing it with state-of-the-art multi-objective optimizations. We perform our evaluation on two real-world problems -- airfoil design and 3D printing -- showcasing the applicability and efficiency of our approach. Our code is available at: https://github.com/an-on-ym-ous/lbn_mobo
Read more9/6/2024