SAMSA: Efficient Transformer for Many Data Modalities

0

Sign in to get full access
Overview
- SAMSA is an efficient transformer model that can work with various data modalities
- It achieves high performance while being computationally efficient
- The key innovations are its differentiable architecture and attention mechanism
Plain English Explanation
SAMSA is a new type of machine learning model called a transformer. Transformers are a powerful way to process different types of data, like text, images, and even time series data.
SAMSA is designed to be more efficient than other transformers. This means it can achieve high performance without using a lot of computing power or memory. The key innovations in SAMSA are:
- Its differentiable architecture - This allows the model to be trained end-to-end, which can improve its performance.
- Its attention mechanism - This is how the model focuses on the most important parts of the input data. SAMSA's attention mechanism is designed to be more efficient.
By being more efficient, SAMSA can be used in a wider range of applications, from processing text to analyzing time series data. This could lead to more powerful and versatile AI systems.
Technical Explanation
SAMSA builds on the success of transformer models, which have proven to be highly effective across a variety of data modalities. However, traditional transformers can be computationally expensive, limiting their practical deployment.
The key innovations in SAMSA are its differentiable architecture and efficient attention mechanism. The differentiable architecture allows the model to be trained end-to-end, which can improve its performance compared to models with non-differentiable components.
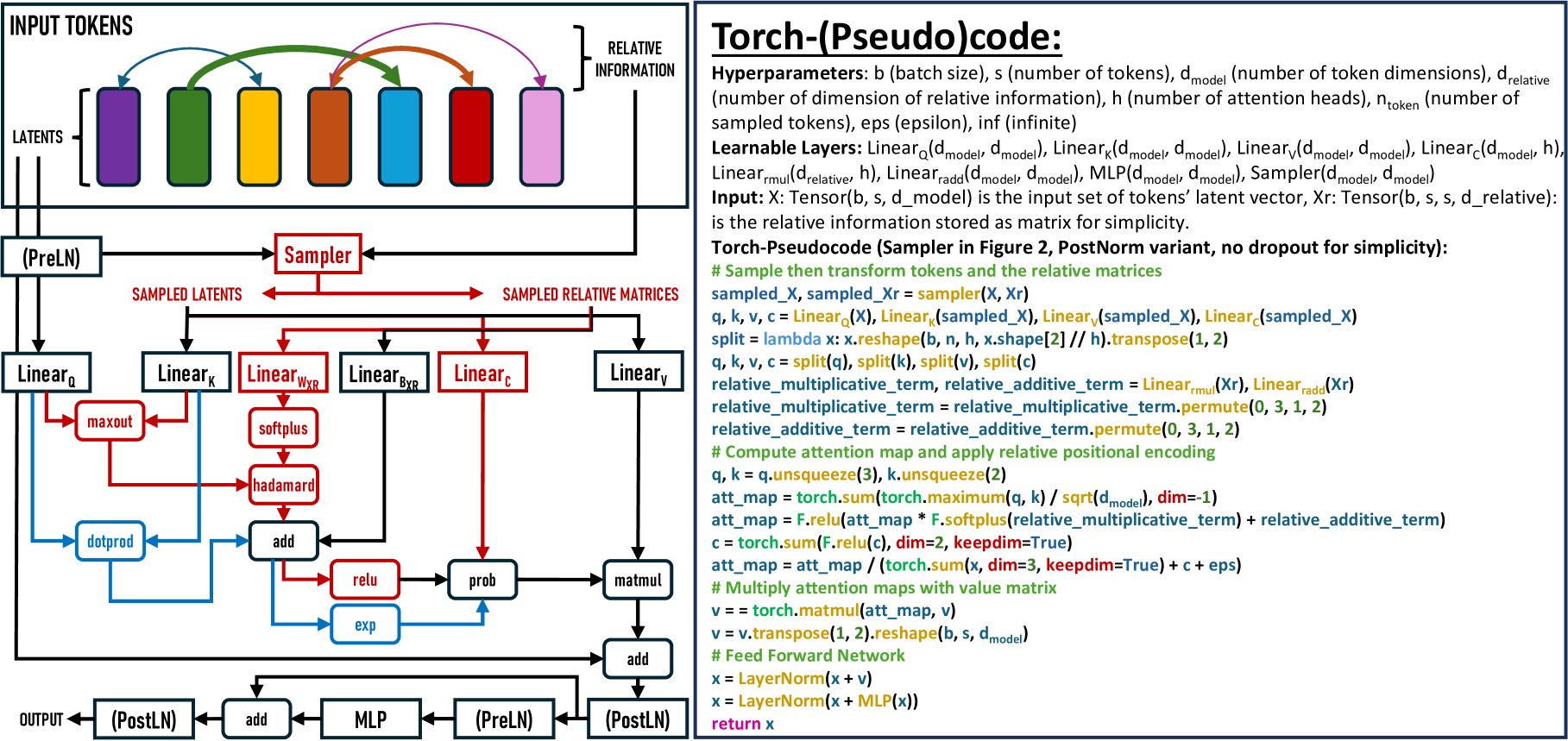
SAMSA's attention mechanism is also designed to be more efficient than standard transformer attention. It uses a shared attention map that is applied across all heads, reducing the number of parameters and computations required.
The authors evaluate SAMSA on a range of tasks including language modeling, image classification, and time series forecasting. They demonstrate that SAMSA achieves competitive performance while being substantially more efficient than baseline transformer models.
Critical Analysis
The paper provides a thorough evaluation of SAMSA across multiple datasets and tasks, which lends confidence in the model's versatility and effectiveness. However, the authors do not explore the model's limitations or potential failure modes in depth.
One area that could be explored further is the model's robustness to distribution shift or noisy input data. As with many deep learning models, SAMSA may rely on capturing statistical patterns in the training data, which could lead to brittleness when faced with significant real-world distribution changes.
Additionally, the paper does not provide much insight into the interpretability or explainability of SAMSA's attention mechanism. Understanding how the model is making decisions could be important for certain applications, especially those with high-stakes outcomes.
Overall, SAMSA represents an interesting and promising advance in efficient transformer architectures. Further research into its limitations and potential failure cases could help strengthen the claims and broaden the applicability of this approach.
Conclusion
SAMSA is an efficient transformer model that can handle a variety of data modalities, from text to images to time series. Its key innovations are a differentiable architecture and an attention mechanism designed for computational efficiency.
By being more efficient than standard transformer models, SAMSA could enable the deployment of powerful AI systems in a wider range of real-world applications. The thorough evaluation in the paper suggests SAMSA is a compelling addition to the transformer toolkit, though further research into its robustness and interpretability would be valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAMSA: Efficient Transformer for Many Data Modalities
Minh Lenhat, Viet Anh Nguyen, Khoa Nguyen, Duong Duc Hieu, Dao Huu Hung, Truong Son Hy
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. Efficient transformers, on the other hand, often rely on clever data-modality-dependent construction to get over the quadratic complexity of transformers. This greatly hinders their applications on different data modalities, which is one of the pillars of contemporary foundational modeling. In this paper, we lay the groundwork for efficient foundational modeling by proposing SAMSA - SAMpling-Self-Attention, a context-aware linear complexity self-attention mechanism that works well on multiple data modalities. Our mechanism is based on a differentiable sampling without replacement method we discovered. This enables the self-attention module to attend to the most important token set, where the importance is defined by data. Moreover, as differentiability is not needed in inference, the sparse formulation of our method costs little time overhead, further lowering computational costs. In short, SAMSA achieved competitive or even SOTA results on many benchmarks, while being faster in inference, compared to other very specialized models. Against full self-attention, real inference time significantly decreases while performance ranges from negligible degradation to outperformance. We release our source code in the repository: https://github.com/HySonLab/SAMSA
Read more8/20/2024

0
ToSA: Token Selective Attention for Efficient Vision Transformers
Manish Kumar Singh, Rajeev Yasarla, Hong Cai, Mingu Lee, Fatih Porikli
In this paper, we propose a novel token selective attention approach, ToSA, which can identify tokens that need to be attended as well as those that can skip a transformer layer. More specifically, a token selector parses the current attention maps and predicts the attention maps for the next layer, which are then used to select the important tokens that should participate in the attention operation. The remaining tokens simply bypass the next layer and are concatenated with the attended ones to re-form a complete set of tokens. In this way, we reduce the quadratic computation and memory costs as fewer tokens participate in self-attention while maintaining the features for all the image patches throughout the network, which allows it to be used for dense prediction tasks. Our experiments show that by applying ToSA, we can significantly reduce computation costs while maintaining accuracy on the ImageNet classification benchmark. Furthermore, we evaluate on the dense prediction task of monocular depth estimation on NYU Depth V2, and show that we can achieve similar depth prediction accuracy using a considerably lighter backbone with ToSA.
Read more6/14/2024
🧠
0
A Generic Shared Attention Mechanism for Various Backbone Neural Networks
Zhongzhan Huang, Senwei Liang, Mingfu Liang, Liang Lin
The self-attention mechanism has emerged as a critical component for improving the performance of various backbone neural networks. However, current mainstream approaches individually incorporate newly designed self-attention modules (SAMs) into each layer of the network for granted without fully exploiting their parameters' potential. This leads to suboptimal performance and increased parameter consumption as the network depth increases. To improve this paradigm, in this paper, we first present a counterintuitive but inherent phenomenon: SAMs tend to produce strongly correlated attention maps across different layers, with an average Pearson correlation coefficient of up to 0.85. Inspired by this inherent observation, we propose Dense-and-Implicit Attention (DIA), which directly shares SAMs across layers and employs a long short-term memory module to calibrate and bridge the highly correlated attention maps of different layers, thus improving the parameter utilization efficiency of SAMs. This design of DIA is also consistent with the neural network's dynamical system perspective. Through extensive experiments, we demonstrate that our simple yet effective DIA can consistently enhance various network backbones, including ResNet, Transformer, and UNet, across tasks such as image classification, object detection, and image generation using diffusion models.
Read more4/11/2024
0
Sampling Foundational Transformer: A Theoretical Perspective
Viet Anh Nguyen, Minh Lenhat, Khoa Nguyen, Duong Duc Hieu, Dao Huu Hung, Truong Son Hy
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. To apply transformers across different data modalities, practitioners have to make specific clever data-modality-dependent constructions. In this paper, we propose Sampling Foundational Transformer (SFT) that can work on multiple data modalities (e.g., point cloud, graph, and sequence) and constraints (e.g., rotational-invariant). The existence of such model is important as contemporary foundational modeling requires operability on multiple data sources. For efficiency on large number of tokens, our model relies on our context aware sampling-without-replacement mechanism for both linear asymptotic computational complexity and real inference time gain. For efficiency, we rely on our newly discovered pseudoconvex formulation of transformer layer to increase model's convergence rate. As a model working on multiple data modalities, SFT has achieved competitive results on many benchmarks, while being faster in inference, compared to other very specialized models.
Read more8/20/2024