Sampling Foundational Transformer: A Theoretical Perspective

0
Sign in to get full access
Overview
- The paper presents a theoretical perspective on the Sampling Foundational Transformer (SFT), a novel transformer-based architecture.
- The paper explores the theoretical foundations and properties of the SFT, including its ability to efficiently process data from multiple modalities.
- The paper aims to provide a comprehensive understanding of the SFT and its potential applications in various domains.
Plain English Explanation
The paper discusses a new type of transformer model called the Sampling Foundational Transformer (SFT). Transformers are a type of machine learning model that have become very popular in recent years for tasks like language processing and generation.
The key idea behind the SFT is that it can efficiently process data from multiple different sources or "modalities," such as text, images, and audio. Traditional transformer models often struggle to handle diverse data types, but the SFT is designed to overcome this limitation.
The paper provides a detailed theoretical explanation of how the SFT works and what makes it unique. It explores the mathematical properties and architectural choices that allow the SFT to effectively learn from and combine information from multiple data modalities.
The researchers believe the SFT could have important applications in fields like multimodal machine learning, time series forecasting, and efficient transformer optimization. By being able to seamlessly work with diverse data sources, the SFT could unlock new possibilities for AI systems that need to understand and reason about complex, real-world phenomena.
Technical Explanation
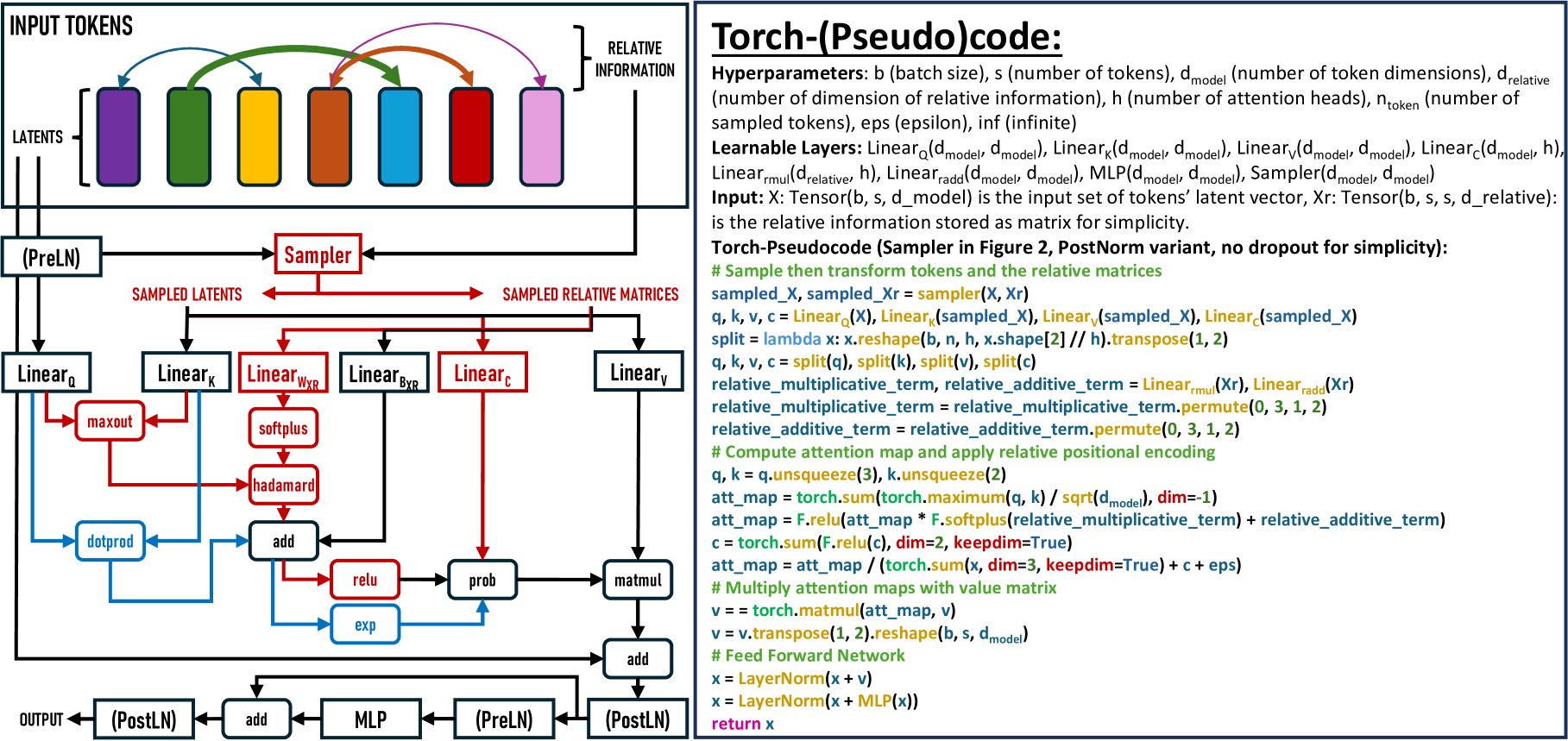
The paper introduces the Sampling Foundational Transformer (SFT), a novel transformer-based architecture designed to efficiently process data from multiple modalities. The key innovation of the SFT is its ability to learn modality-agnostic representations by utilizing a shared self-attention mechanism across different input types.
The SFT architecture consists of several key components:
- Modality-Specific Encoders: The model contains separate encoders for each input modality (e.g., text, image, audio), which learn modality-specific representations.
- Shared Self-Attention Mechanism: A single self-attention module is shared across all modalities, allowing the model to discover cross-modal relationships.
- Modality-Specific Decoders: The model has separate decoders for each output modality, which leverage the shared representations to generate modality-specific outputs.
The paper provides a detailed theoretical analysis of the properties and capabilities of the SFT. This includes examining its ability to learn efficient, frequency-inspired optimizations and its potential applications in multimodal machine learning and time series forecasting.
Critical Analysis
The paper presents a thorough and well-reasoned theoretical analysis of the Sampling Foundational Transformer. However, the authors acknowledge that the practical implementation and empirical evaluation of the SFT are not covered in this work. As such, the true effectiveness and performance of the SFT remain to be demonstrated through future experimental studies.
Additionally, the paper does not address potential limitations or challenges that may arise when applying the SFT to real-world tasks and datasets. For example, the authors do not discuss how the SFT would handle noisy, incomplete, or imbalanced data, which are common issues in many application domains.
Further research is needed to fully assess the SFT's robustness, scalability, and generalization capabilities across a wide range of multimodal learning problems. The paper lays an important theoretical foundation, but empirical validation and exploration of the SFT's practical implications are necessary to fully understand its potential impact.
Conclusion
The paper presents a comprehensive theoretical analysis of the Sampling Foundational Transformer (SFT), a novel transformer-based architecture designed to efficiently process data from multiple modalities. The SFT's key innovation is its ability to learn modality-agnostic representations through a shared self-attention mechanism, which could unlock new possibilities for multimodal machine learning and other applications.
While the theoretical foundations of the SFT are well-established in this work, the practical implementation and empirical evaluation of the model remain to be explored. Further research is needed to assess the SFT's real-world performance, robustness, and scalability. Nevertheless, this paper provides a solid theoretical basis for the development and exploration of the SFT, which could have significant implications for the field of artificial intelligence and its ability to understand and reason about complex, multimodal data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sampling Foundational Transformer: A Theoretical Perspective
Viet Anh Nguyen, Minh Lenhat, Khoa Nguyen, Duong Duc Hieu, Dao Huu Hung, Truong Son Hy
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. To apply transformers across different data modalities, practitioners have to make specific clever data-modality-dependent constructions. In this paper, we propose Sampling Foundational Transformer (SFT) that can work on multiple data modalities (e.g., point cloud, graph, and sequence) and constraints (e.g., rotational-invariant). The existence of such model is important as contemporary foundational modeling requires operability on multiple data sources. For efficiency on large number of tokens, our model relies on our context aware sampling-without-replacement mechanism for both linear asymptotic computational complexity and real inference time gain. For efficiency, we rely on our newly discovered pseudoconvex formulation of transformer layer to increase model's convergence rate. As a model working on multiple data modalities, SFT has achieved competitive results on many benchmarks, while being faster in inference, compared to other very specialized models.
Read more8/20/2024

0
Threshold Filtering Packing for Supervised Fine-Tuning: Training Related Samples within Packs
Jiancheng Dong, Lei Jiang, Wei Jin, Lu Cheng
Packing for Supervised Fine-Tuning (SFT) in autoregressive models involves concatenating data points of varying lengths until reaching the designed maximum length to facilitate GPU processing. However, randomly concatenating data points and feeding them into an autoregressive transformer can lead to cross-contamination of sequences due to the significant difference in their subject matter. The mainstream approaches in SFT ensure that each token in the attention calculation phase only focuses on tokens within its own short sequence, without providing additional learning signals for the preceding context. To address these challenges, we introduce Threshold Filtering Packing (TFP), a method that selects samples with related context while maintaining sufficient diversity within the same pack. Our experiments show that TFP offers a simple-to-implement and scalable approach that significantly enhances SFT performance, with observed improvements of up to 7% on GSM8K, 4% on HumanEval, and 15% on the adult-census-income dataset.
Read more8/20/2024

0
SAMSA: Efficient Transformer for Many Data Modalities
Minh Lenhat, Viet Anh Nguyen, Khoa Nguyen, Duong Duc Hieu, Dao Huu Hung, Truong Son Hy
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. Efficient transformers, on the other hand, often rely on clever data-modality-dependent construction to get over the quadratic complexity of transformers. This greatly hinders their applications on different data modalities, which is one of the pillars of contemporary foundational modeling. In this paper, we lay the groundwork for efficient foundational modeling by proposing SAMSA - SAMpling-Self-Attention, a context-aware linear complexity self-attention mechanism that works well on multiple data modalities. Our mechanism is based on a differentiable sampling without replacement method we discovered. This enables the self-attention module to attend to the most important token set, where the importance is defined by data. Moreover, as differentiability is not needed in inference, the sparse formulation of our method costs little time overhead, further lowering computational costs. In short, SAMSA achieved competitive or even SOTA results on many benchmarks, while being faster in inference, compared to other very specialized models. Against full self-attention, real inference time significantly decreases while performance ranges from negligible degradation to outperformance. We release our source code in the repository: https://github.com/HySonLab/SAMSA
Read more8/20/2024
🤷
0
Boosting X-formers with Structured Matrix for Long Sequence Time Series Forecasting
Zhicheng Zhang, Yong Wang, Shaoqi Tan, Bowei Xia, Yujie Luo
Transformer-based models for long sequence time series forecasting (LSTF) problems have gained significant attention due to their exceptional forecasting precision. As the cornerstone of these models, the self-attention mechanism poses a challenge to efficient training and inference due to its quadratic time complexity. In this article, we propose a novel architectural design for Transformer-based models in LSTF, leveraging a substitution framework that incorporates Surrogate Attention Blocks and Surrogate FFN Blocks. The framework aims to boost any well-designed model's efficiency without sacrificing its accuracy. We further establish the equivalence of the Surrogate Attention Block to the self-attention mechanism in terms of both expressiveness and trainability. Through extensive experiments encompassing nine Transformer-based models across five time series tasks, we observe an average performance improvement of 9.45% while achieving a significant reduction in model size by 46%
Read more5/24/2024