Satyrn: A Platform for Analytics Augmented Generation

0

Sign in to get full access
Overview
- Satyrn is a platform that combines analytics and generative capabilities to produce high-quality, personalized content
- The platform leverages large language models and retrieval-augmented generation techniques to generate content tailored to user needs and preferences
- Key features of Satyrn include analytics-driven content generation, personalization based on user data, and seamless integration with other tools and services
Plain English Explanation
Satyrn is a new platform that aims to make it easier and more efficient to create content that is tailored to individual users' needs and preferences. It does this by combining powerful language models, which are able to generate human-like text, with advanced analytics capabilities.
The key idea behind Satyrn is to use data about a user's interests, behavior, and past interactions to inform the content generation process. This allows the platform to produce content that is much more relevant and useful to that particular user, rather than just generic, one-size-fits-all content.
For example, imagine you're looking for information on how to reduce your home's energy usage. Satyrn could analyze your past searches, your location, the size and type of your home, your energy bills, and other relevant data. It could then use that information to generate a personalized report with customized tips and recommendations just for you. The platform's ability to leverage this kind of data-driven approach sets it apart from traditional content creation methods.
Technical Explanation
At the core of Satyrn is a retrieval-augmented generation (RAG) architecture, which combines large language models with the ability to dynamically retrieve and incorporate relevant information from external sources. This allows the platform to generate content that is grounded in facts and data, rather than just relying on the language model's own knowledge.
The Satyrn workflow begins by gathering relevant user data and contextual information. This data is then used to query a knowledge base and retrieve the most pertinent information. The language model then uses this retrieved information, along with its own generated text, to produce the final output. This integration of analytics and generation is a key innovation of the Satyrn platform.
Satyrn also incorporates techniques for personalizing the generated content, such as adapting the tone, style, and level of detail based on user preferences. This personalization capability helps ensure that the output is truly tailored to the individual user's needs.
Critical Analysis
One potential limitation of Satyrn is the reliance on external data sources and the accuracy of the information retrieved. If the knowledge base contains incomplete or inaccurate data, it could lead to suboptimal content generation. Additionally, the platform's ability to truly personalize the output may be constrained by the availability and quality of user data.
Another area for further exploration is the platform's scalability and ability to handle diverse content types and user needs. As the user base and content demands grow, Satyrn will need to demonstrate robust performance and the ability to adapt to a wide range of use cases.
Overall, Satyrn represents an exciting step forward in the integration of analytics and content generation, with the potential to revolutionize how we create and consume personalized information. However, as with any new technology, there are challenges and areas for improvement that will need to be carefully addressed as the platform continues to evolve.
Conclusion
Satyrn is a innovative platform that combines the power of large language models with advanced analytics to generate personalized, high-quality content. By leveraging user data and contextual information, Satyrn is able to produce content that is tailored to individual needs and preferences, setting it apart from traditional content creation methods.
While the platform faces some potential limitations and areas for further development, Satyrn's ability to integrate analytics and generation represents a significant advancement in the field of content creation. As the technology continues to mature, it has the potential to transform how we access and interact with information, making it more relevant, engaging, and valuable to each individual user.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Satyrn: A Platform for Analytics Augmented Generation
Marko Sterbentz, Cameron Barrie, Shubham Shahi, Abhratanu Dutta, Donna Hooshmand, Harper Pack, Kristian J. Hammond
Large language models (LLMs) are capable of producing documents, and retrieval augmented generation (RAG) has shown itself to be a powerful method for improving accuracy without sacrificing fluency. However, not all information can be retrieved from text. We propose an approach that uses the analysis of structured data to generate fact sets that are used to guide generation in much the same way that retrieved documents are used in RAG. This analytics augmented generation (AAG) approach supports the ability to utilize standard analytic techniques to generate facts that are then converted to text and passed to an LLM. We present a neurosymbolic platform, Satyrn that leverages AAG to produce accurate, fluent, and coherent reports grounded in large scale databases. In our experiments, we find that Satyrn generates reports in which over 86% accurate claims while maintaining high levels of fluency and coherence, even when using smaller language models such as Mistral-7B, as compared to GPT-4 Code Interpreter in which just 57% of claims are accurate.
Read more6/19/2024

0
FACTS About Building Retrieval Augmented Generation-based Chatbots
Rama Akkiraju, Anbang Xu, Deepak Bora, Tan Yu, Lu An, Vishal Seth, Aaditya Shukla, Pritam Gundecha, Hridhay Mehta, Ashwin Jha, Prithvi Raj, Abhinav Balasubramanian, Murali Maram, Guru Muthusamy, Shivakesh Reddy Annepally, Sidney Knowles, Min Du, Nick Burnett, Sean Javiya, Ashok Marannan, Mamta Kumari, Surbhi Jha, Ethan Dereszenski, Anupam Chakraborty, Subhash Ranjan, Amina Terfai, Anoop Surya, Tracey Mercer, Vinodh Kumar Thanigachalam, Tamar Bar, Sanjana Krishnan, Samy Kilaru, Jasmine Jaksic, Nave Algarici, Jacob Liberman, Joey Conway, Sonu Nayyar, Justin Boitano
Enterprise chatbots, powered by generative AI, are emerging as key applications to enhance employee productivity. Retrieval Augmented Generation (RAG), Large Language Models (LLMs), and orchestration frameworks like Langchain and Llamaindex are crucial for building these chatbots. However, creating effective enterprise chatbots is challenging and requires meticulous RAG pipeline engineering. This includes fine-tuning embeddings and LLMs, extracting documents from vector databases, rephrasing queries, reranking results, designing prompts, honoring document access controls, providing concise responses, including references, safeguarding personal information, and building orchestration agents. We present a framework for building RAG-based chatbots based on our experience with three NVIDIA chatbots: for IT/HR benefits, financial earnings, and general content. Our contributions are three-fold: introducing the FACTS framework (Freshness, Architectures, Cost, Testing, Security), presenting fifteen RAG pipeline control points, and providing empirical results on accuracy-latency tradeoffs between large and small LLMs. To the best of our knowledge, this is the first paper of its kind that provides a holistic view of the factors as well as solutions for building secure enterprise-grade chatbots.
Read more7/11/2024
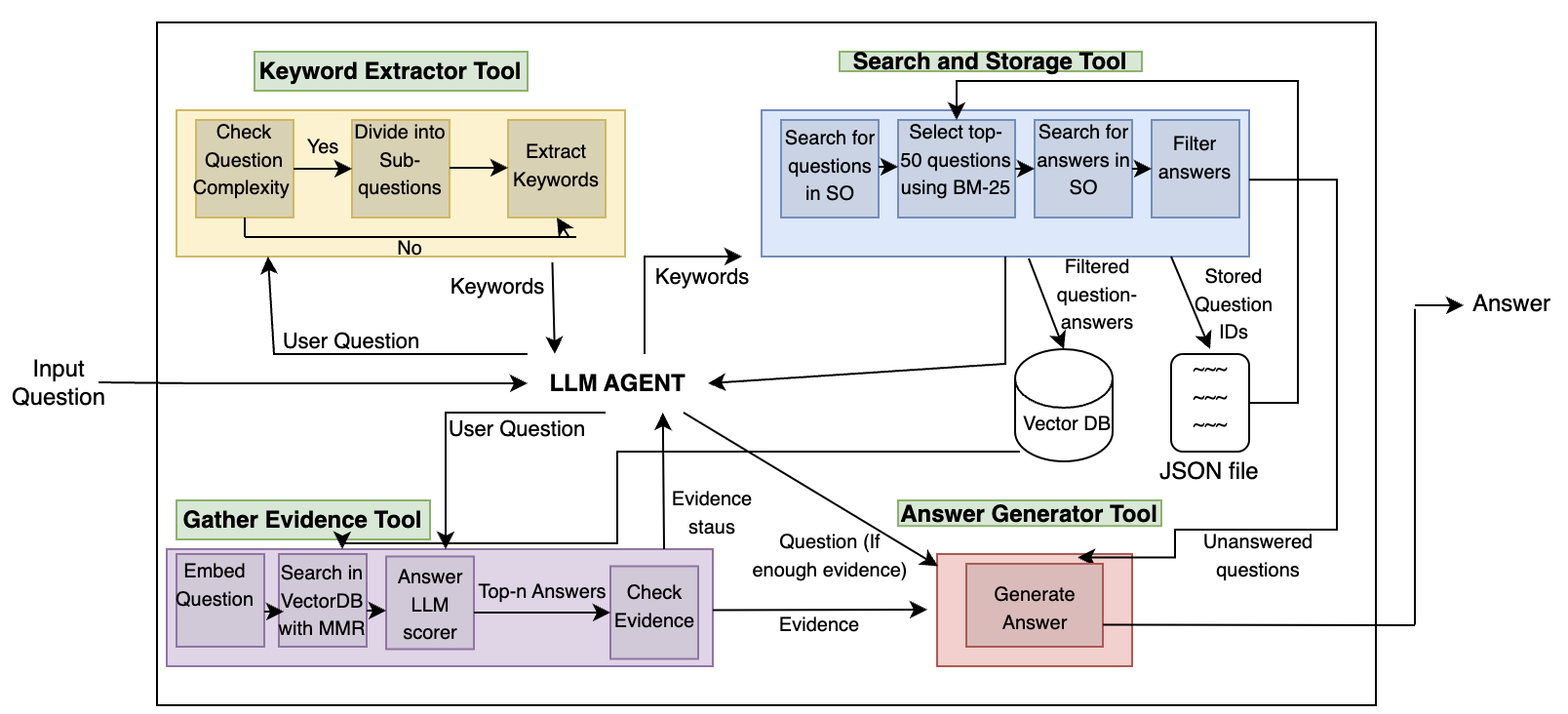
0
StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
Davit Abrahamyan, Fatemeh H. Fard
Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.
Read more6/21/2024
🛸
0
PersonaRAG: Enhancing Retrieval-Augmented Generation Systems with User-Centric Agents
Saber Zerhoudi, Michael Granitzer
Large Language Models (LLMs) struggle with generating reliable outputs due to outdated knowledge and hallucinations. Retrieval-Augmented Generation (RAG) models address this by enhancing LLMs with external knowledge, but often fail to personalize the retrieval process. This paper introduces PersonaRAG, a novel framework incorporating user-centric agents to adapt retrieval and generation based on real-time user data and interactions. Evaluated across various question answering datasets, PersonaRAG demonstrates superiority over baseline models, providing tailored answers to user needs. The results suggest promising directions for user-adapted information retrieval systems.
Read more7/15/2024