SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
2405.20974
28
0
Abstract
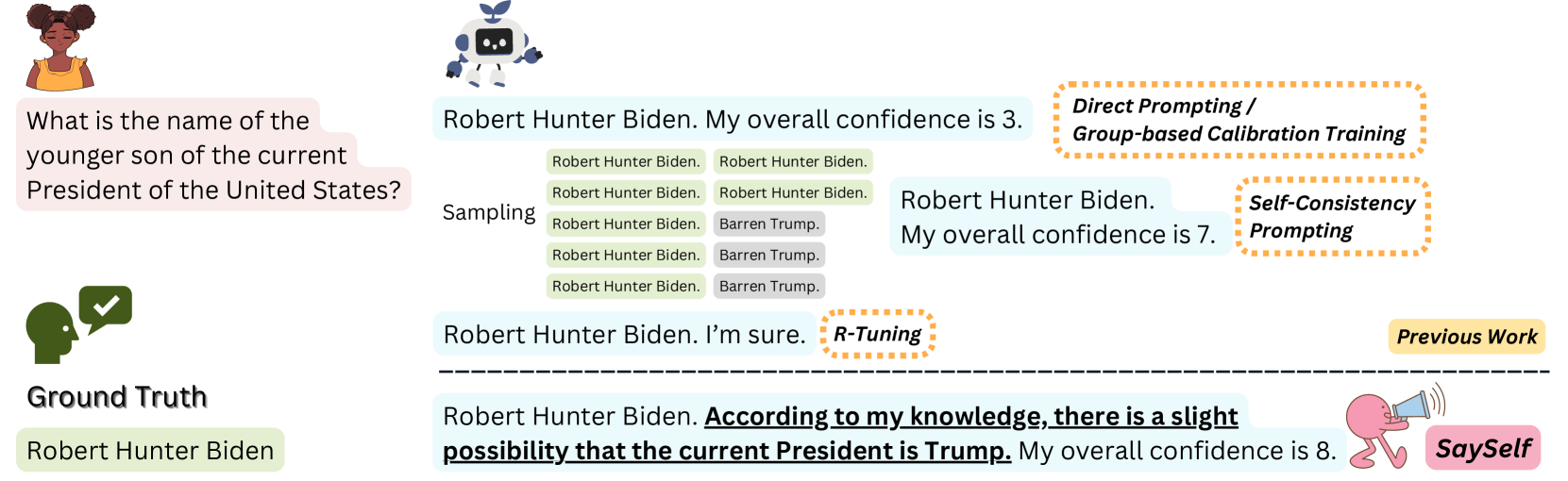
Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at https://github.com/xu1868/SaySelf.
Create account to get full access
Overview
• This paper introduces SaySelf, a system that teaches large language models (LLMs) to express confidence in their own responses by generating self-reflective rationales.
• The key idea is to train LLMs to not only generate outputs, but also to reason about and justify their own responses, which can help users better understand the model's level of confidence and reasoning.
• The authors demonstrate that this approach can improve the calibration of LLM confidence, leading to more reliable and transparent language models.
Plain English Explanation
The paper describes a new approach called SaySelf that aims to make large language models (LLMs) more transparent and reliable. LLMs are AI systems that can generate human-like text, but they don't always express how confident they are in their responses.
The core idea of SaySelf is to train LLMs to not only generate outputs, but also to explain their own reasoning and confidence levels. So, in addition to giving an answer, the model would also provide a self-reflective rationale that justifies its response.
For example, if asked "What is the capital of France?", a SaySelf-enabled model might respond: "I'm very confident that the capital of France is Paris, because France is a country in Western Europe and Paris is widely known as its capital city."
By having the model explain its thought process, users can better understand how reliable the model's response is. This can help improve trust in the model and make it more transparent.
The authors show through experiments that this approach can lead to LLMs that are better calibrated - meaning their expressed confidence levels better match their actual accuracy. This makes the models more reliable and trustworthy for real-world applications.
Technical Explanation
The key innovation of this paper is the introduction of the SaySelf framework, which trains large language models (LLMs) to not only generate outputs, but also to provide self-reflective rationales that explain their reasoning and confidence levels.
To implement this, the authors utilize a multi-task learning approach. The model is trained on a primary task, such as question answering or text generation, as well as an auxiliary task that requires the model to generate a self-reflective rationale alongside its primary output.
The rationale is produced by a separate output head in the model's architecture, which is trained to summarize the model's reasoning process and estimate its own confidence. This allows the model to express its level of certainty about a given response.
The authors evaluate SaySelf on a range of language understanding and generation tasks, and show that it leads to significant improvements in confidence calibration - meaning the model's expressed confidence aligns better with its actual accuracy. This makes the model's outputs more reliable and transparent for users.
Some key technical insights from the paper include:
- The importance of multi-task learning to imbue LLMs with self-reflection capabilities
- Novel architectures that decouple response generation and self-reflection
- Effective training strategies to encourage models to develop accurate self-awareness
Critical Analysis
The SaySelf approach represents an important step towards more transparent and reliable large language models. By teaching LLMs to reason about and justify their own outputs, the authors address a key limitation of current models, which can sometimes produce confident-sounding but inaccurate responses.
That said, the paper does not delve deeply into potential limitations or failure modes of the SaySelf approach. For example, it's unclear how well the self-reflective rationales would generalize to out-of-distribution inputs, or how robust the confidence calibration would be to adversarial attacks.
Additionally, the added complexity of the SaySelf architecture and training process could make the models more computationally expensive or slower to deploy. The authors do not provide a thorough analysis of the tradeoffs in terms of efficiency and scalability.
Further research is also needed to understand how users interpret and respond to the self-reflective rationales in real-world applications. While the improved confidence calibration is promising, more user studies are required to validate the impact on trust and transparency.
Overall, the SaySelf framework represents an important advance in the field of trustworthy AI, but there are still open challenges and avenues for further exploration. Rigorous evaluation of the approach's limitations and real-world implications will be crucial as this line of research progresses.
Conclusion
This paper introduces SaySelf, a novel framework for training large language models to not only generate outputs, but also to provide self-reflective rationales that explain their reasoning and confidence levels. By imbuing LLMs with this self-awareness, the authors demonstrate significant improvements in confidence calibration, making the models' responses more reliable and transparent.
The SaySelf approach represents an important step towards developing AI systems that can better communicate their capabilities and limitations to users. As language models become increasingly pervasive in real-world applications, techniques like this will be crucial for building trust and ensuring these powerful tools are used responsibly and effectively.
While the paper does not address all potential limitations of the approach, it lays the groundwork for further research and development in the area of trustworthy AI. Continued progress in this direction could lead to a new generation of language models that are not only highly capable, but also self-aware and able to explain their inner workings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, Tat-Seng Chua
0
0
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
6/5/2024
📈
Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, William Yang Wang
0
0
Recent studies show that large language models (LLMs) improve their performance through self-feedback on certain tasks while degrade on others. We discovered that such a contrary is due to LLM's bias in evaluating their own output. In this paper, we formally define LLM's self-bias - the tendency to favor its own generation - using two statistics. We analyze six LLMs (GPT-4, GPT-3.5, Gemini, LLaMA2, Mixtral and DeepSeek) on translation, constrained text generation, and mathematical reasoning tasks. We find that self-bias is prevalent in all examined LLMs across multiple languages and tasks. Our analysis reveals that while the self-refine pipeline improves the fluency and understandability of model outputs, it further amplifies self-bias. To mitigate such biases, we discover that larger model size and external feedback with accurate assessment can significantly reduce bias in the self-refine pipeline, leading to actual performance improvement in downstream tasks. The code and data are released at https://github.com/xu1998hz/llm_self_bias.
6/19/2024
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
0
0
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
5/1/2024
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Loka Li, Zhenhao Chen, Guangyi Chen, Yixuan Zhang, Yusheng Su, Eric Xing, Kun Zhang
0
0
The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the confidence of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the confidence in their own responses. It motivates us to develop an If-or-Else (IoE) prompting framework, designed to guide LLMs in assessing their own confidence, facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with confidence. The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
5/14/2024