Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
2403.09972
0
0
Abstract
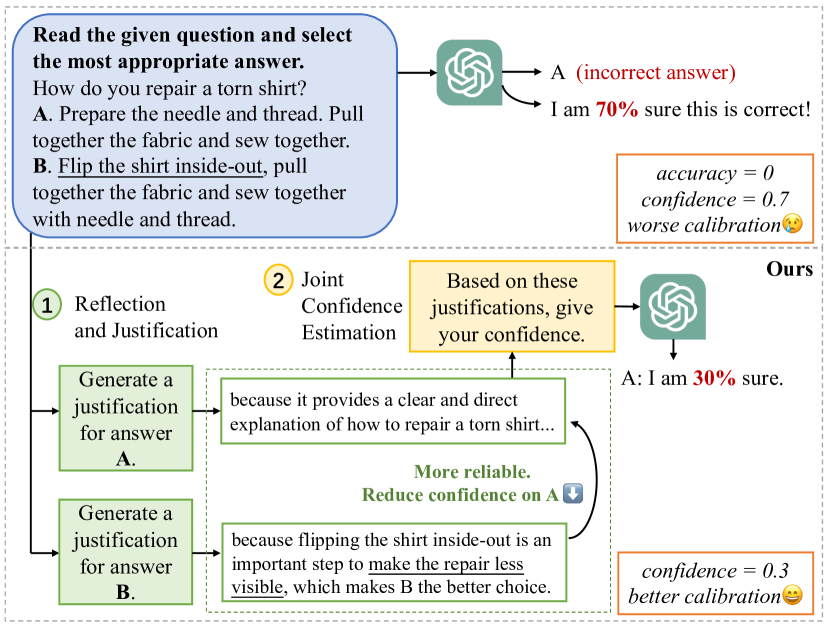
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
Create account to get full access
Overview
- This research paper explores a novel approach to improving the confidence estimation capabilities of large language models (LLMs).
- The key idea is to have the LLM reflect on multiple possible answers to a query, rather than just relying on a single output.
- By considering multiple perspectives, the model can better assess the confidence it has in its final response.
- The paper presents experiments and insights that demonstrate the benefits of this "think twice before assure" approach.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes be overconfident in their outputs, even when they are uncertain or mistaken. The researchers behind this paper wanted to find a way to improve the confidence estimation capabilities of LLMs so that they can be more transparent about the level of certainty in their responses.
Their approach involves having the LLM generate multiple possible answers to a given query, and then reflect on those answers to assess which one it is most confident in. By considering multiple perspectives, the model can better evaluate the strength of its own reasoning and avoid being overly assured about a potentially flawed or uncertain response.
The paper presents experiments that demonstrate the effectiveness of this "think twice before assure" method. The results show that LLMs trained with this approach are able to provide more accurate confidence estimates, which can be valuable in real-world applications where it's important to know how much trust can be placed in the model's output.
Technical Explanation
The researchers formulate the problem of confidence estimation as a way to improve the transparency and reliability of LLMs. They propose a novel training approach called "Think Twice Before Assure" (TTBA), which involves having the model generate multiple candidate answers to a query and then reflect on those answers to assess its own confidence.
The TTBA training process consists of several steps:
- The model generates a set of candidate answers to a given input question or prompt.
- The model then evaluates each of the candidate answers, assigning a confidence score to each one.
- The model selects the answer it is most confident in and outputs that as the final response.
- The model also outputs its overall confidence in the selected answer.
The key innovation in this approach is the reflection step, where the model considers multiple possibilities before deciding on its final output. This allows the model to better calibrate its confidence estimates, avoiding the overconfidence that can sometimes plague LLMs.
The researchers evaluate the TTBA approach on a range of benchmark tasks and find that it leads to significant improvements in confidence estimation accuracy compared to standard LLM training methods. They also provide insights into the inner workings of the model and discuss potential limitations and future research directions.
Critical Analysis
The "Think Twice Before Assure" approach presented in this paper is a promising step towards improving the transparency and reliability of large language models. By encouraging the model to consider multiple possible answers and reflect on its own confidence, the researchers have found a way to overcome some of the common issues with overconfidence in LLMs.
However, the paper does acknowledge several limitations and areas for further research. For example, the approach may be computationally expensive, as it requires the model to generate and evaluate multiple candidate responses. Additionally, the paper notes that the model's confidence estimates may still be imperfect, and that further work is needed to understand the factors that influence the model's self-assessment capabilities.
Another potential concern is the extent to which the model's confidence estimates can be trusted, especially in high-stakes applications where the consequences of errors can be significant. The paper does not delve deeply into this issue, and further research may be needed to explore the reliability and robustness of the TTBA approach in real-world settings.
Despite these limitations, the core idea of encouraging LLMs to reflect on multiple answers before providing a final output is a valuable contribution to the field of AI safety and reliability. By fostering a more nuanced and transparent approach to confidence estimation, the TTBA method has the potential to make LLMs more trustworthy and useful in a wide range of applications.
Conclusion
The "Think Twice Before Assure" approach presented in this paper represents an important step forward in improving the confidence estimation capabilities of large language models. By having the model generate and reflect on multiple possible answers, the researchers have found a way to mitigate the overconfidence that can sometimes plague LLMs.
The experimental results demonstrate the benefits of this approach, showing that models trained with TTBA are able to provide more accurate and reliable confidence estimates. While there are still some limitations and areas for further research, the core idea of encouraging self-reflection in LLMs is a valuable contribution to the field of AI safety and reliability.
As language models continue to play an increasingly important role in our lives, it will be crucial to develop techniques like TTBA that can make these systems more transparent and trustworthy. By fostering a culture of critical self-examination in AI, researchers can help ensure that these powerful technologies are deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Weize Liu, Guocong Li, Kai Zhang, Bang Du, Qiyuan Chen, Xuming Hu, Hongxia Xu, Jintai Chen, Jian Wu
0
0
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
4/9/2024

When Hindsight is Not 20/20: Testing Limits on Reflective Thinking in Large Language Models
Yanhong Li, Chenghao Yang, Allyson Ettinger
0
0
Recent studies suggest that self-reflective prompting can significantly enhance the reasoning capabilities of Large Language Models (LLMs). However, the use of external feedback as a stop criterion raises doubts about the true extent of LLMs' ability to emulate human-like self-reflection. In this paper, we set out to clarify these capabilities under a more stringent evaluation setting in which we disallow any kind of external feedback. Our findings under this setting show a split: while self-reflection enhances performance in TruthfulQA, it adversely affects results in HotpotQA. We conduct follow-up analyses to clarify the contributing factors in these patterns, and find that the influence of self-reflection is impacted both by reliability of accuracy in models' initial responses, and by overall question difficulty: specifically, self-reflection shows the most benefit when models are less likely to be correct initially, and when overall question difficulty is higher. We also find that self-reflection reduces tendency toward majority voting. Based on our findings, we propose guidelines for decisions on when to implement self-reflection. We release the codebase for reproducing our experiments at https://github.com/yanhong-lbh/LLM-SelfReflection-Eval.
4/16/2024
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
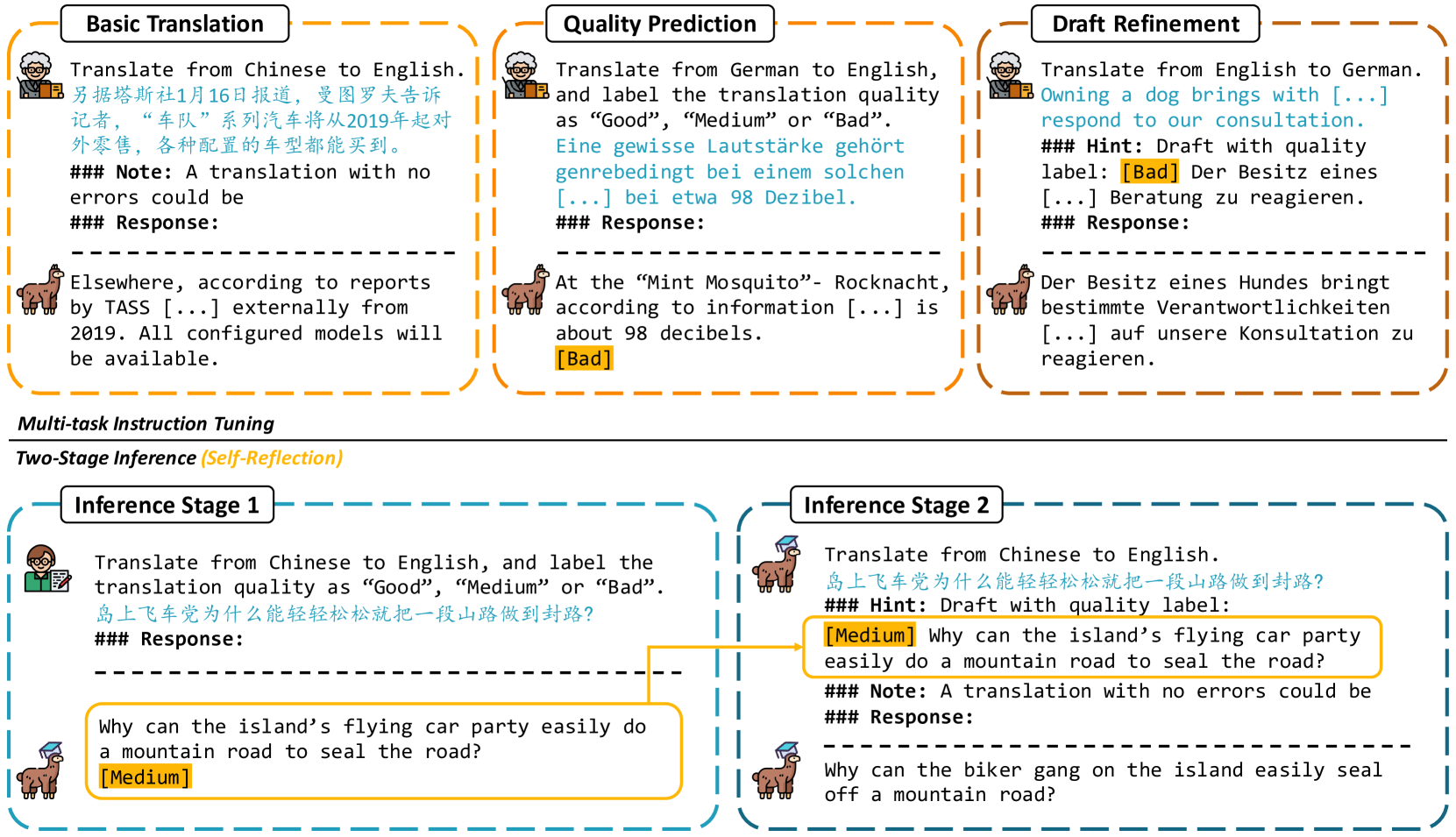
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Wenqi Zhang, Yongliang Shen, Linjuan Wu, Qiuying Peng, Jun Wang, Yueting Zhuang, Weiming Lu
0
0
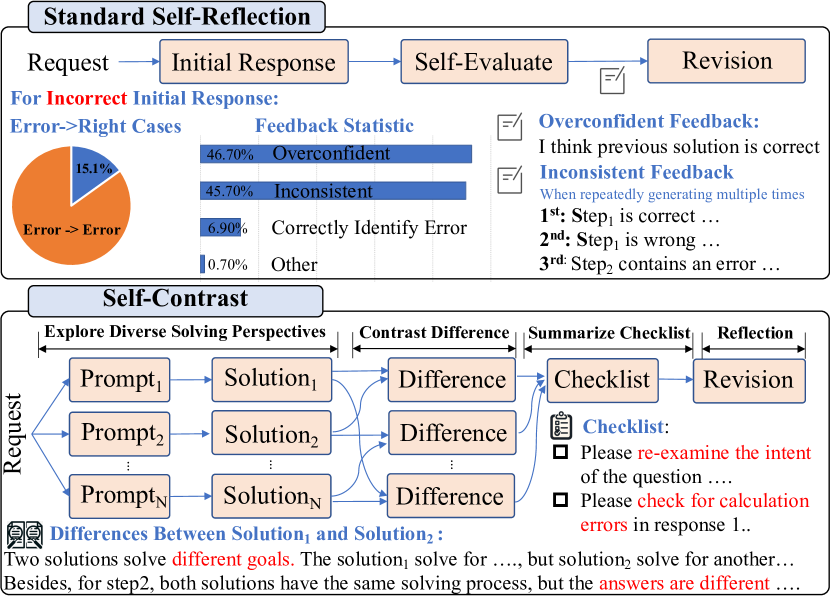
The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.
6/10/2024