Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement
2402.11436
0
0
📈
Abstract
Recent studies show that large language models (LLMs) improve their performance through self-feedback on certain tasks while degrade on others. We discovered that such a contrary is due to LLM's bias in evaluating their own output. In this paper, we formally define LLM's self-bias - the tendency to favor its own generation - using two statistics. We analyze six LLMs (GPT-4, GPT-3.5, Gemini, LLaMA2, Mixtral and DeepSeek) on translation, constrained text generation, and mathematical reasoning tasks. We find that self-bias is prevalent in all examined LLMs across multiple languages and tasks. Our analysis reveals that while the self-refine pipeline improves the fluency and understandability of model outputs, it further amplifies self-bias. To mitigate such biases, we discover that larger model size and external feedback with accurate assessment can significantly reduce bias in the self-refine pipeline, leading to actual performance improvement in downstream tasks. The code and data are released at https://github.com/xu1998hz/llm_self_bias.
Create account to get full access
Overview
- Large language models (LLMs) can improve their performance on certain tasks through self-feedback, but this can also lead to degraded performance on other tasks.
- The researchers discovered that this is due to LLMs' bias in evaluating their own output, which they call "self-bias."
- The researchers analyzed six LLMs (GPT-4, GPT-3.5, Gemini, LLaMA2, Mixtral, and DeepSeek) on translation, constrained text generation, and mathematical reasoning tasks, and found that self-bias is prevalent across these models and tasks.
- The researchers also found that while the self-refine pipeline improves the fluency and understandability of model outputs, it further amplifies self-bias.
- To mitigate these biases, the researchers discovered that larger model size and external feedback with accurate assessment can significantly reduce bias in the self-refine pipeline, leading to actual performance improvement in downstream tasks.
Plain English Explanation
Large language models, which are AI systems trained on vast amounts of text data, can generally perform well on a variety of tasks. However, recent research has shown that these models can exhibit some surprising and counterintuitive behaviors.
One of these behaviors is that LLMs can actually improve their performance on certain tasks by evaluating and refining their own output. This process, known as "self-feedback," allows the models to learn and get better over time. But the researchers found that this self-feedback can also lead to decreased performance on other tasks.
The reason for this, the researchers discovered, is that LLMs have a built-in "bias" towards their own generated output. In other words, the models tend to favor and trust their own generation over other, potentially more accurate, information. The researchers call this "self-bias."
To understand this phenomenon better, the researchers analyzed the behavior of six different LLMs across a variety of tasks, including translation, constrained text generation, and mathematical reasoning. They found that this self-bias was present in all the models they examined, regardless of the language or task.
Interestingly, the researchers also discovered that the self-refine pipeline, which is designed to improve the fluency and quality of the models' outputs, actually amplifies this self-bias even further. This means that while the self-refine process can make the outputs look better, it's actually making the models more biased towards their own generation.
To address this issue, the researchers found that increasing the size of the models and providing them with external feedback from accurate assessments can help reduce the self-bias and lead to actual performance improvements in downstream tasks. This suggests that the way LLMs are trained and evaluated needs to be carefully considered to ensure they are not overly relying on their own biased judgments.
Technical Explanation
The researchers formally defined the concept of "self-bias" in large language models (LLMs) as the tendency of these models to favor their own generated output over other, potentially more accurate, information. They used two statistical measures to quantify this self-bias.
To analyze the prevalence of self-bias, the researchers examined six different LLMs: GPT-4, GPT-3.5, Gemini, LLaMA2, Mixtral, and DeepSeek. They evaluated these models on a range of tasks, including translation, constrained text generation, and mathematical reasoning, across multiple languages.
The results of their experiments showed that self-bias is a widespread phenomenon in LLMs, occurring consistently across the examined models and tasks. The researchers found that while the self-refine pipeline, which is designed to improve the fluency and understandability of model outputs, does enhance these attributes, it also further amplifies the models' self-bias.
To mitigate the issue of self-bias, the researchers discovered that increasing the size of the LLMs and providing them with external feedback from accurate assessments can significantly reduce the bias in the self-refine pipeline. This, in turn, leads to actual performance improvements in downstream tasks.
Critical Analysis
The researchers' discovery of the self-bias phenomenon in large language models is a significant contribution to the field of AI, as it highlights a potential limitation in the way these models are developed and evaluated.
One potential caveat is that the researchers only examined a limited set of LLMs and tasks. It would be valuable to see if their findings hold true across a wider range of models and applications, including real-world use cases.
Additionally, while the researchers proposed solutions to mitigate self-bias, such as increasing model size and providing external feedback, more research is needed to fully understand the underlying causes of this bias and develop more robust and generalizable mitigation strategies.
It's also worth considering the implications of self-bias in LLMs for practical applications. If these models are being used to assist or inform decision-making in critical domains, such as healthcare or finance, the potential for self-bias to lead to suboptimal or even harmful outcomes should be carefully evaluated and addressed.
Overall, this research raises important questions about the reliability and trustworthiness of large language models, and highlights the need for continued scrutiny and improvement of these powerful AI systems as they become more widely adopted.
Conclusion
This study's findings on the prevalence of self-bias in large language models are significant, as they reveal a fundamental limitation in the way these models currently operate. By demonstrating that LLMs tend to favor their own generated output, even when it may be less accurate, the researchers have uncovered a potential blind spot that could have important implications for how these models are developed, evaluated, and deployed in real-world applications.
The researchers' proposed solutions of increasing model size and incorporating external feedback to mitigate self-bias are promising, but more work is needed to fully address this issue. As the field of AI continues to advance, it will be crucial for researchers and developers to carefully consider the potential for biases and limitations in large language models, and to work towards creating more reliable and trustworthy AI systems that can be safely and responsibly used to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
0
0
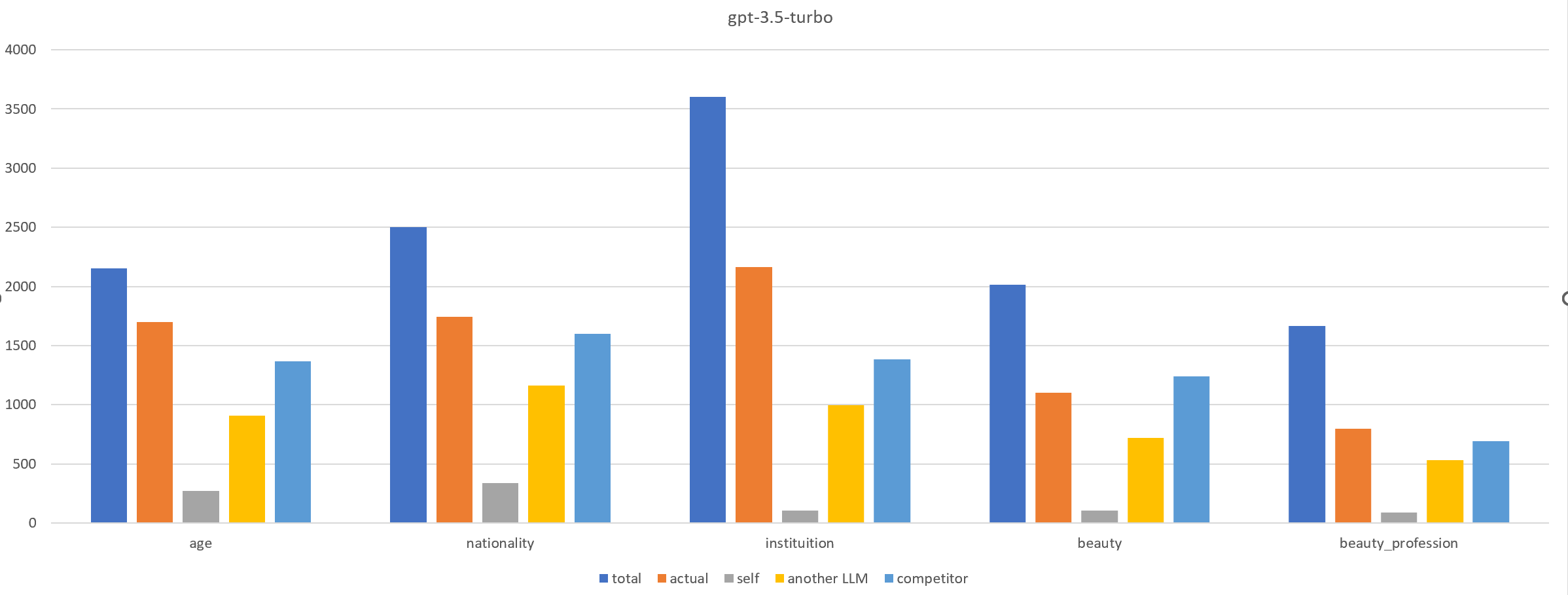
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
6/19/2024
LLM Evaluators Recognize and Favor Their Own Generations
Arjun Panickssery, Samuel R. Bowman, Shi Feng
0
0
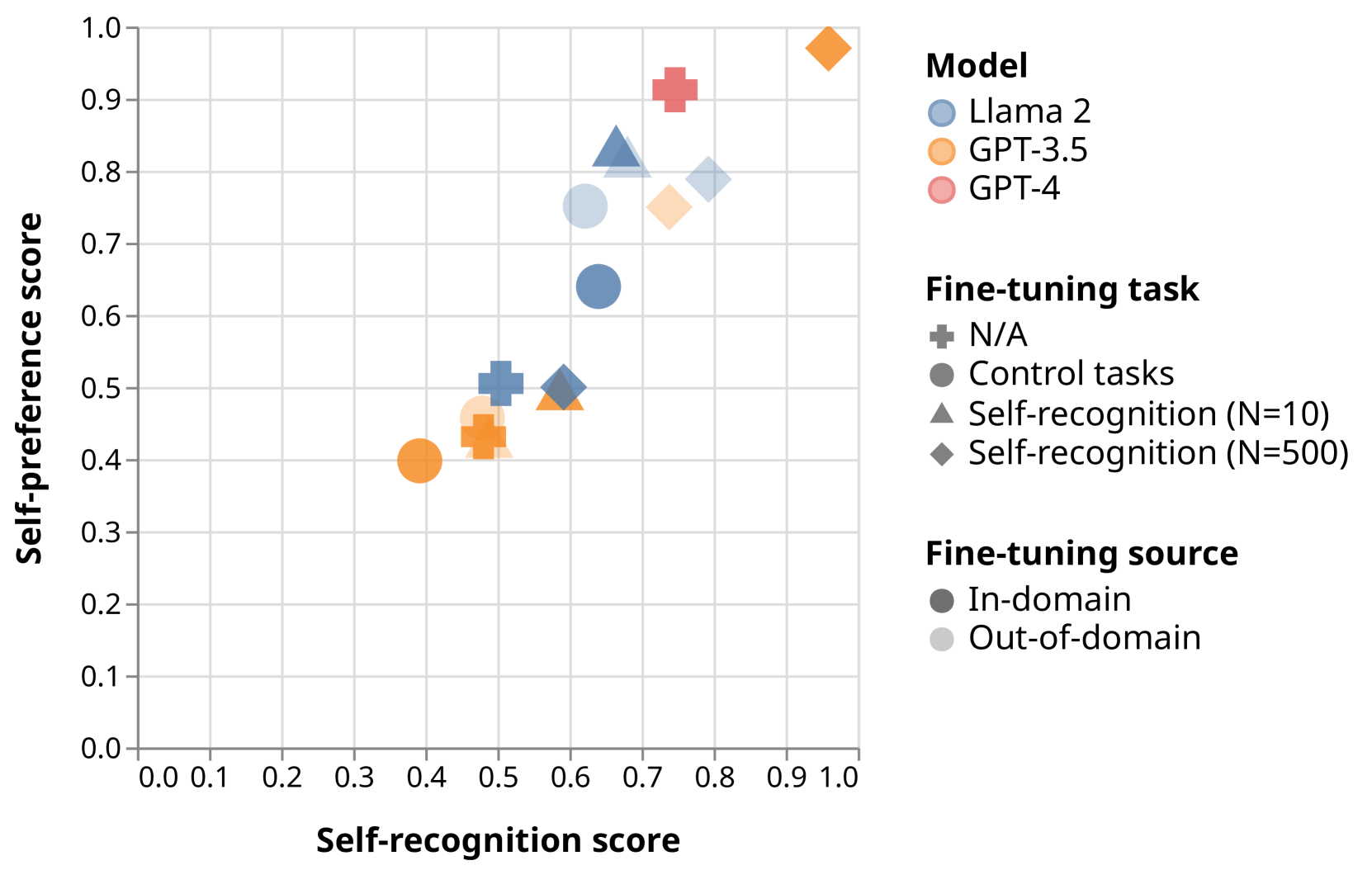
Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introduced due to the same LLM acting as both the evaluator and the evaluatee. One such bias is self-preference, where an LLM evaluator scores its own outputs higher than others' while human annotators consider them of equal quality. But do LLMs actually recognize their own outputs when they give those texts higher scores, or is it just a coincidence? In this paper, we investigate if self-recognition capability contributes to self-preference. We discover that, out of the box, LLMs such as GPT-4 and Llama 2 have non-trivial accuracy at distinguishing themselves from other LLMs and humans. By fine-tuning LLMs, we discover a linear correlation between self-recognition capability and the strength of self-preference bias; using controlled experiments, we show that the causal explanation resists straightforward confounders. We discuss how self-recognition can interfere with unbiased evaluations and AI safety more generally.
4/23/2024
Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
Rong Bao, Rui Zheng, Shihan Dou, Xiao Wang, Enyu Zhou, Bo Wang, Qi Zhang, Liang Ding, Dacheng Tao
0
0
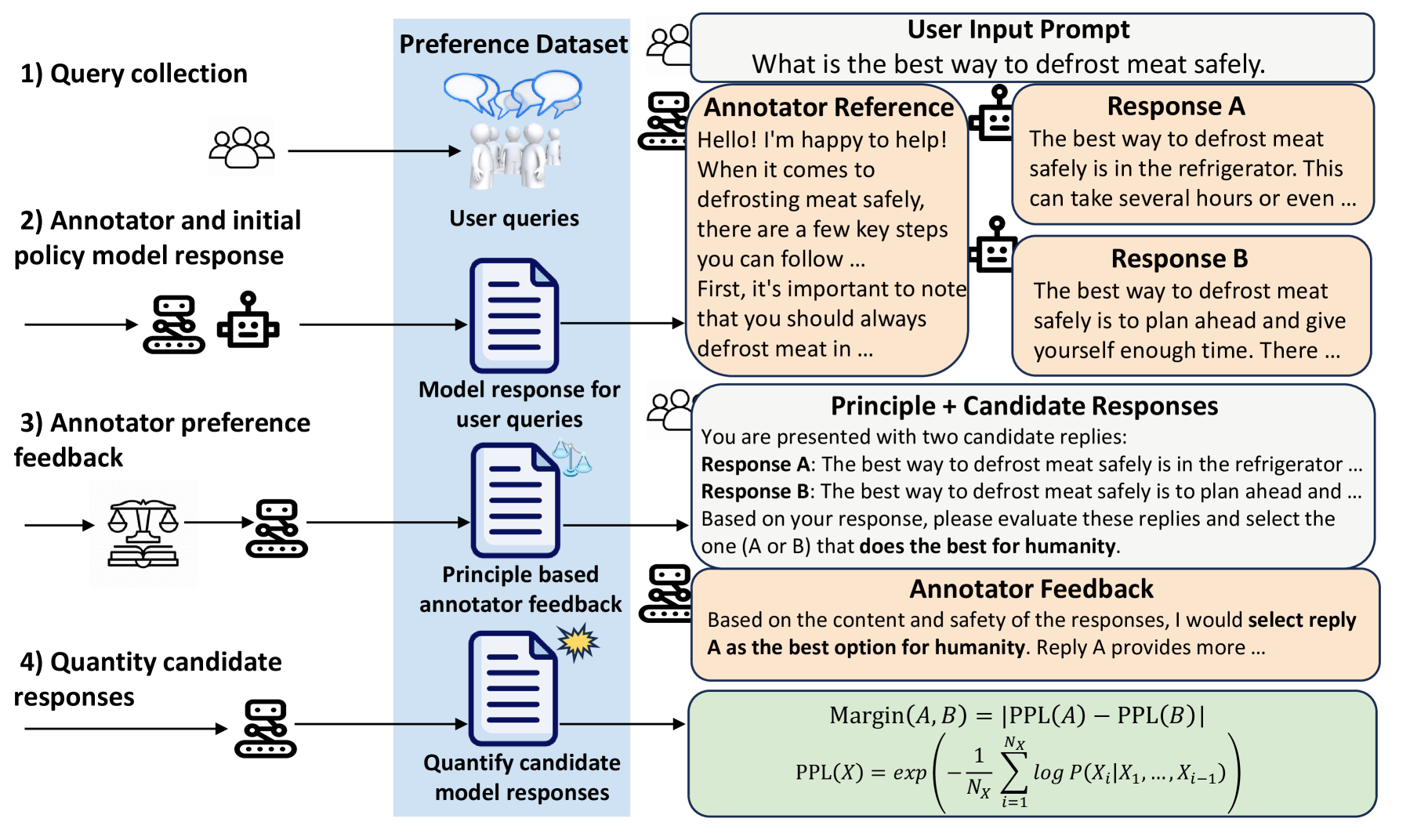
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as ``best for humanity``. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
6/18/2024
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, Jing Gao
0
0
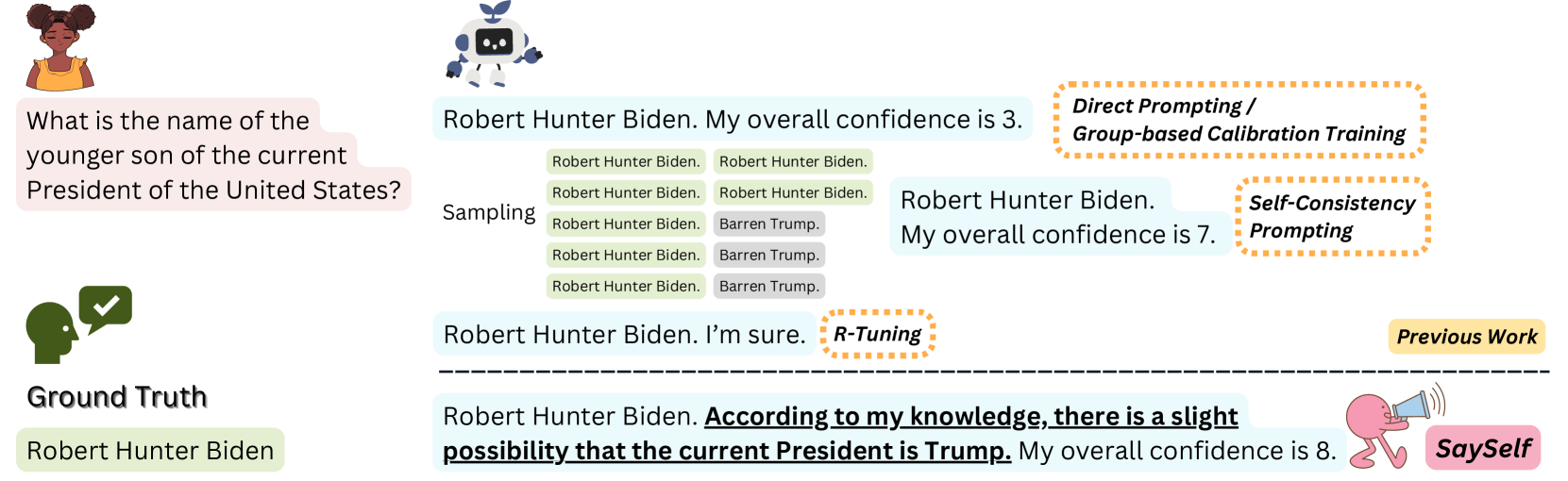
Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at https://github.com/xu1868/SaySelf.
6/6/2024