Scalable Detection of Salient Entities in News Articles
2405.20461
1
0

Abstract
News articles typically mention numerous entities, a large fraction of which are tangential to the story. Detecting the salience of entities in articles is thus important to applications such as news search, analysis and summarization. In this work, we explore new approaches for efficient and effective salient entity detection by fine-tuning pretrained transformer models with classification heads that use entity tags or contextualized entity representations directly. Experiments show that these straightforward techniques dramatically outperform prior work across datasets with varying sizes and salience definitions. We also study knowledge distillation techniques to effectively reduce the computational cost of these models without affecting their accuracy. Finally, we conduct extensive analyses and ablation experiments to characterize the behavior of the proposed models.
Create account to get full access
Overview
- This paper presents a scalable approach for detecting salient entities in news articles using transformers.
- The proposed method leverages contextual information to effectively identify important entities that are relevant to the main topics covered in the article.
- The authors evaluate their approach on several datasets and show that it outperforms existing entity salience detection techniques.
Plain English Explanation
In this research, the authors introduce a new way to automatically identify the most important people, places, and things mentioned in news articles. They use a type of machine learning model called a transformer to analyze the context and content of the articles and determine which entities (like people or organizations) are the most relevant and significant.
This is an important task because being able to quickly find the key entities in a news story can help readers understand the main topics and events being covered. It can also be useful for applications like summarizing articles or extracting information from large collections of news data.
The researchers show that their transformer-based approach outperforms previous methods for detecting salient entities. This suggests it could be a valuable tool for analyzing the vast amount of news content that is produced every day.
Technical Explanation
The core of the proposed approach is a transformer-based model that learns to predict the salience of entities mentioned in a news article. The model takes the full text of the article as input and outputs a salience score for each entity, indicating how important or relevant that entity is to the main topics covered.
The key innovation is the way the model leverages contextual information from the article to make these salience predictions. Rather than just looking at the entity itself, the transformer model considers the surrounding text and uses that context to better understand the entity's significance.
The authors evaluate their method on several benchmark datasets for entity salience detection. They show that it achieves state-of-the-art performance, outperforming previous techniques that relied more on simple entity-level features or event-based embeddings.
Critical Analysis
One limitation of the paper is that it focuses solely on news articles, and the generalizability of the approach to other domains like scientific literature or social media is not explored. The authors acknowledge this and suggest it as an area for future work.
Additionally, the evaluation is limited to entity salience detection, but the potential applications of this technology, such as summarization or question answering, are not thoroughly investigated. It would be interesting to see how the salience predictions could be leveraged in downstream NLP tasks.
Overall, this research presents a novel and effective approach for identifying salient entities in news articles. While there are some avenues for further exploration, the results demonstrate the value of using transformers to capture contextual cues for this important text mining task.
Conclusion
This paper introduces a scalable method for detecting salient entities in news articles using transformer-based models. The key innovation is the way the approach leverages the full context of the article to better understand the significance of each mentioned entity.
The authors show that their technique outperforms previous state-of-the-art methods for entity salience detection, suggesting it could be a valuable tool for applications like summarization, information extraction, and knowledge graph construction from large news corpora. While the current evaluation is limited to the news domain, the general approach could potentially be extended to other text-based applications as well.
Overall, this research represents an important advance in the field of text mining and natural language processing, with practical implications for how we extract and organize information from the growing volume of online news content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Leveraging Contextual Information for Effective Entity Salience Detection
Rajarshi Bhowmik, Marco Ponza, Atharva Tendle, Anant Gupta, Rebecca Jiang, Xingyu Lu, Qian Zhao, Daniel Preotiuc-Pietro
0
0
In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
4/4/2024
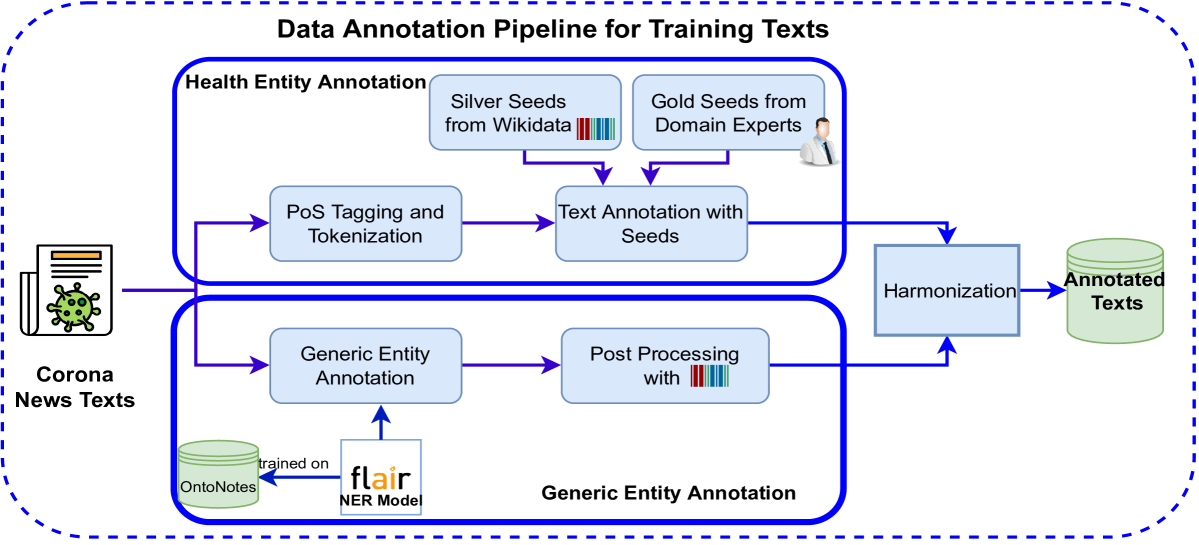
Fine-Grained Named Entities for Corona News
Sefika Efeoglu, Adrian Paschke
0
0
Information resources such as newspapers have produced unstructured text data in various languages related to the corona outbreak since December 2019. Analyzing these unstructured texts is time-consuming without representing them in a structured format; therefore, representing them in a structured format is crucial. An information extraction pipeline with essential tasks -- named entity tagging and relation extraction -- to accomplish this goal might be applied to these texts. This study proposes a data annotation pipeline to generate training data from corona news articles, including generic and domain-specific entities. Named entity recognition models are trained on this annotated corpus and then evaluated on test sentences manually annotated by domain experts evaluating the performance of a trained model. The code base and demonstration are available at https://github.com/sefeoglu/coronanews-ner.git.
4/23/2024
🖼️
A Novel Method for News Article Event-Based Embedding
Koren Ishlach, Itzhak Ben-David, Michael Fire, Lior Rokach
0
0
Embedding news articles is a crucial tool for multiple fields, such as media bias detection, identifying fake news, and news recommendations. However, existing news embedding methods are not optimized for capturing the latent context of news events. In many cases, news embedding methods rely on full-textual information and neglect the importance of time-relevant embedding generation. Here, we aim to address these shortcomings by presenting a novel lightweight method that optimizes news embedding generation by focusing on the entities and themes mentioned in the articles and their historical connections to specific events. We suggest a method composed of three stages. First, we process and extract the events, entities, and themes for the given news articles. Second, we generate periodic time embeddings for themes and entities by training timely separated GloVe models on current and historical data. Lastly, we concatenate the news embeddings generated by two distinct approaches: Smooth Inverse Frequency (SIF) for article-level vectors and Siamese Neural Networks for embeddings with nuanced event-related information. To test and evaluate our method, we leveraged over 850,000 news articles and 1,000,000 events from the GDELT project. For validation purposes, we conducted a comparative analysis of different news embedding generation methods, applying them twice to a shared event detection task - first on articles published within the same day and subsequently on those published within the same month. Our experiments show that our method significantly improves the Precision-Recall (PR) AUC across all tasks and datasets. Specifically, we observed an average PR AUC improvement of 2.15% and 2.57% compared to SIF, as well as 2.57% and 2.43% compared to the semi-supervised approach for daily and monthly shared event detection tasks, respectively.
5/24/2024
🛸
XL-HeadTags: Leveraging Multimodal Retrieval Augmentation for the Multilingual Generation of News Headlines and Tags
Faisal Tareque Shohan, Mir Tafseer Nayeem, Samsul Islam, Abu Ubaida Akash, Shafiq Joty
0
0
Millions of news articles published online daily can overwhelm readers. Headlines and entity (topic) tags are essential for guiding readers to decide if the content is worth their time. While headline generation has been extensively studied, tag generation remains largely unexplored, yet it offers readers better access to topics of interest. The need for conciseness in capturing readers' attention necessitates improved content selection strategies for identifying salient and relevant segments within lengthy articles, thereby guiding language models effectively. To address this, we propose to leverage auxiliary information such as images and captions embedded in the articles to retrieve relevant sentences and utilize instruction tuning with variations to generate both headlines and tags for news articles in a multilingual context. To make use of the auxiliary information, we have compiled a dataset named XL-HeadTags, which includes 20 languages across 6 diverse language families. Through extensive evaluation, we demonstrate the effectiveness of our plug-and-play multimodal-multilingual retrievers for both tasks. Additionally, we have developed a suite of tools for processing and evaluating multilingual texts, significantly contributing to the research community by enabling more accurate and efficient analysis across languages.
6/10/2024