Scalable Dynamic Embedding Size Search for Streaming Recommendation

0
Sign in to get full access
Overview
- This paper proposes a method for dynamically adjusting the embedding size of a recommender system to improve performance and efficiency.
- The approach uses reinforcement learning to search for an optimal embedding size during the training process.
- The authors demonstrate that their method outperforms static embedding sizes and can adapt to changing user preferences over time.
Plain English Explanation
In the world of online recommendation systems, the size of the "embedding" - a numerical representation of user preferences and item characteristics - is a crucial factor. Larger embedding sizes can capture more nuanced information, but also increase computational complexity and memory requirements.
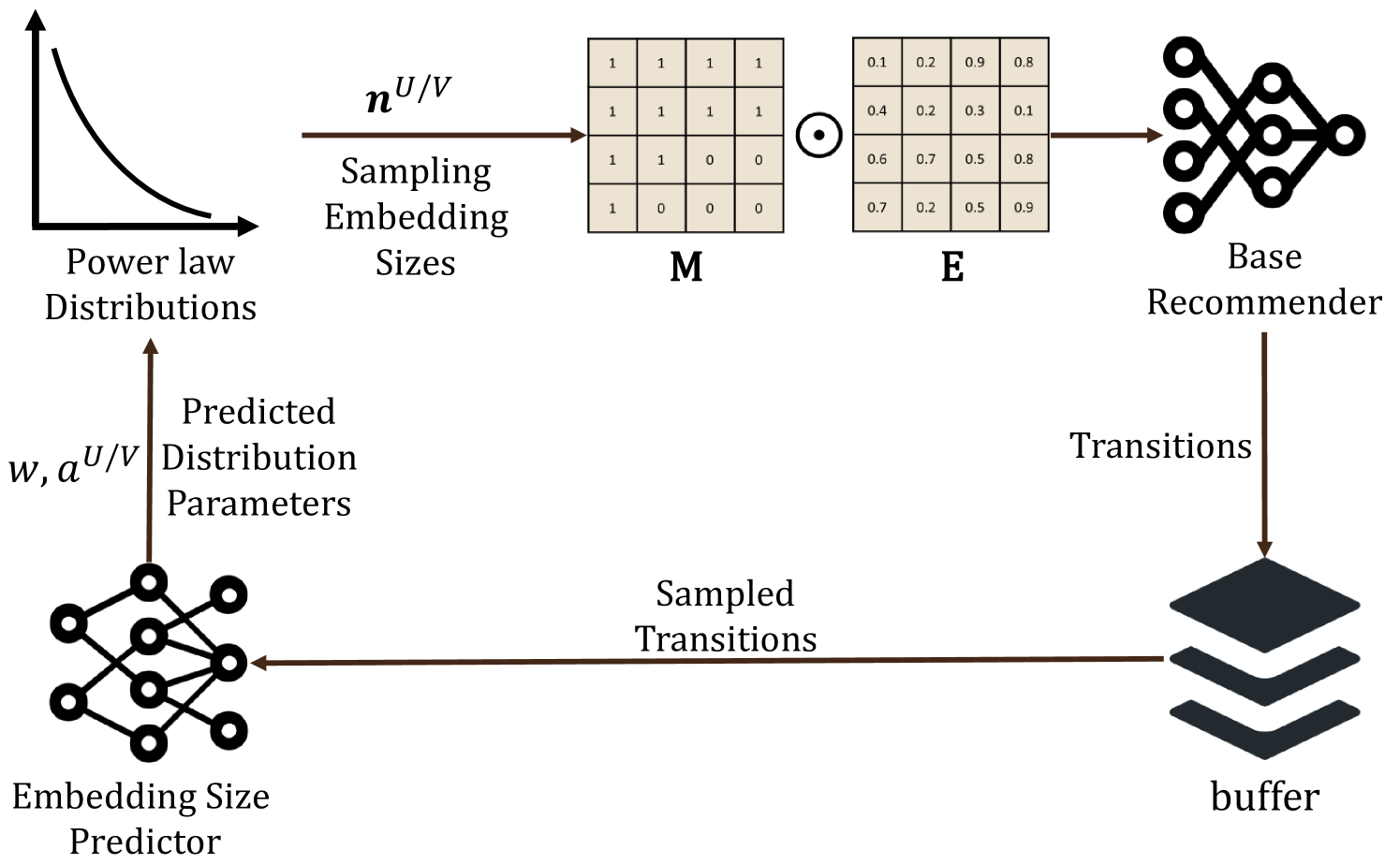
The authors of this paper introduce a novel approach to dynamically adjust the embedding size during training. Using reinforcement learning, their system learns to choose the optimal embedding size for each user and item, balancing the need for detailed representations with the practical constraints of real-world deployment.
This dynamic approach allows the model to adapt to changing user preferences over time, unlike static embedding sizes which can become outdated. By continuously optimizing the embedding size, the system can provide more accurate and efficient recommendations.
Technical Explanation
The core of the authors' approach is a reinforcement learning agent that dynamically adjusts the embedding size during the training process. This agent observes the current performance of the recommender system and selects an appropriate embedding size for the next training step.
The agent uses a deep neural network to map the current state of the system (e.g., recommendation accuracy, computational load) to an action (i.e., the embedding size to use). The agent is trained using a reward signal that encourages it to choose embedding sizes that maximize recommendation performance while minimizing computational overhead.
The authors demonstrate that their dynamic embedding size search outperforms static approaches, particularly in scenarios where user preferences evolve over time. They also show that the method is scalable and can be applied to large-scale recommender systems.
Critical Analysis
The authors acknowledge that their approach relies on the availability of a sufficiently large and diverse training dataset to learn effective embedding size policies. In scenarios with limited data, the reinforcement learning agent may struggle to converge to an optimal strategy.
Additionally, the paper does not address potential fairness or bias issues that can arise from the optimization of embedding spaces. It is important to ensure that the dynamic embedding size search does not exacerbate existing biases or create new ones.
Further research could explore ways to incorporate fairness considerations into the reinforcement learning framework, or investigate how the dynamic embedding size search performs in large-scale user modeling scenarios.
Conclusion
The authors' dynamic embedding size search method represents an innovative approach to improving the efficiency and performance of recommender systems. By continuously optimizing the embedding size, the system can adapt to changing user preferences and provide more accurate recommendations.
While there are some potential limitations and areas for further research, this work demonstrates the power of reinforcement learning in tackling complex optimization problems in the context of recommender systems. As the field of online recommendation continues to evolve, techniques like this may play an important role in building scalable, adaptive, and fair recommendation platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scalable Dynamic Embedding Size Search for Streaming Recommendation
Yunke Qu, Liang Qu, Tong Chen, Xiangyu Zhao, Quoc Viet Hung Nguyen, Hongzhi Yin
Recommender systems typically represent users and items by learning their embeddings, which are usually set to uniform dimensions and dominate the model parameters. However, real-world recommender systems often operate in streaming recommendation scenarios, where the number of users and items continues to grow, leading to substantial storage resource consumption for these embeddings. Although a few methods attempt to mitigate this by employing embedding size search strategies to assign different embedding dimensions in streaming recommendations, they assume that the embedding size grows with the frequency of users/items, which eventually still exceeds the predefined memory budget over time. To address this issue, this paper proposes to learn Scalable Lightweight Embeddings for streaming recommendation, called SCALL, which can adaptively adjust the embedding sizes of users/items within a given memory budget over time. Specifically, we propose to sample embedding sizes from a probabilistic distribution, with the guarantee to meet any predefined memory budget. By fixing the memory budget, the proposed embedding size sampling strategy can increase and decrease the embedding sizes in accordance to the frequency of the corresponding users or items. Furthermore, we develop a reinforcement learning-based search paradigm that models each state with mean pooling to keep the length of the state vectors fixed, invariant to the changing number of users and items. As a result, the proposed method can provide embedding sizes to unseen users and items. Comprehensive empirical evaluations on two public datasets affirm the advantageous effectiveness of our proposed method.
Read more8/1/2024

0
On the Embedding Collapse when Scaling up Recommendation Models
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
Recent advances in foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. Still, mainstream models remain embarrassingly small in size and naive enlarging does not lead to sufficient performance gain, suggesting a deficiency in the model scalability. In this paper, we identify the embedding collapse phenomenon as the inhibition of scalability, wherein the embedding matrix tends to occupy a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate a emph{two-sided effect} of feature interaction specific to recommendation models. On the one hand, interacting with collapsed embeddings restricts embedding learning and exacerbates the collapse issue. On the other hand, interaction is crucial in mitigating the fitting of spurious features as a scalability guarantee. Based on our analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to learn embedding sets with large diversity and thus reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability and effective collapse mitigation for various recommendation models. Code is available at this repository: https://github.com/thuml/Multi-Embedding.
Read more6/7/2024

0
Monitoring the Evolution of Behavioural Embeddings in Social Media Recommendation
Srijan Saket, Olivier Jeunen, Md. Danish Kalim
Emerging short-video platforms like TikTok, Instagram Reels, and ShareChat present unique challenges for recommender systems, primarily originating from a continuous stream of new content. ShareChat alone receives approximately 2 million pieces of fresh content daily, complicating efforts to assess quality, learn effective latent representations, and accurately match content with the appropriate user base, especially given limited user feedback. Embedding-based approaches are a popular choice for industrial recommender systems because they can learn low-dimensional representations of items, leading to effective recommendation that can easily scale to millions of items and users. Our work characterizes the evolution of such embeddings in short-video recommendation systems, comparing the effect of batch and real-time updates to content embeddings. We investigate emph{how} embeddings change with subsequent updates, explore the relationship between embeddings and popularity bias, and highlight their impact on user engagement metrics. Our study unveils the contrast in the number of interactions needed to achieve mature embeddings in a batch learning setup versus a real-time one, identifies the point of highest information updates, and explores the distribution of $ell_2$-norms across the two competing learning modes. Utilizing a production system deployed on a large-scale short-video app with over 180 million users, our findings offer insights into designing effective recommendation systems and enhancing user satisfaction and engagement in short-video applications.
Read more5/29/2024

0
Towards Lifelong Learning Embeddings: An Algorithmic Approach to Dynamically Extend Embeddings
Miguel Alves Gomes, Philipp Meisen, Tobias Meisen
The rapid evolution of technology has transformed business operations and customer interactions worldwide, with personalization emerging as a key opportunity for e-commerce companies to engage customers more effectively. The application of machine learning, particularly that of deep learning models, has gained significant traction due to its ability to rapidly recognize patterns in large datasets, thereby offering numerous possibilities for personalization. These models use embeddings to map discrete information, such as product IDs, into a latent vector space, a method increasingly popular in recent years. However, e-commerce's dynamic nature, characterized by frequent new product introductions, poses challenges for these embeddings, which typically require fixed dimensions and inputs, leading to the need for periodic retraining from scratch. This paper introduces a modular algorithm that extends embedding input size while preserving learned knowledge, addressing the challenges posed by e-commerce's dynamism. The proposed algorithm also incorporates strategies to mitigate the cold start problem associated with new products. The results of initial experiments suggest that this method outperforms traditional embeddings.
Read more8/27/2024