Scalable, reproducible, and cost-effective processing of large-scale medical imaging datasets

0
⚙️
Sign in to get full access
Overview
- Curating, processing, and combining large-scale medical imaging datasets from national studies is challenging due to intense computation, data throughput, data variability, and financial overhead.
- Existing platforms or tools for large-scale data curation, processing, and storage struggle to achieve a viable cost-to-scale ratio for research purposes, being too slow or too expensive.
- Managing and ensuring consistency of processing large data in a team-driven manner is non-trivial.
Plain English Explanation
The paper describes a method for efficiently and robustly processing large-scale diffusion-weighted and T1-weighted MRI data in a cost-effective way. Curating, processing, and combining these large medical imaging datasets from national studies is challenging due to the sheer amount of data involved, the variability in how the data is collected, and the high computational and financial costs.
Existing tools and platforms for managing and processing this kind of large-scale data often struggle to find the right balance between speed and cost-effectiveness. They tend to be either too slow or too expensive for researchers to use effectively. Additionally, coordinating the processing of this data across a team of researchers can be tricky, making it hard to ensure consistency in the results.
The method described in the paper aims to address these challenges by providing an efficient and robust data processing pipeline that is compatible with low-cost, high-efficiency computing systems. It automates the process of querying and running the data processing in a consistent and reproducible way, while leveraging a mix of heterogeneous computational resources and storage systems to keep costs down. The authors demonstrate that this approach can achieve processing speeds comparable to cloud-based computation, but at a fraction of the cost.
Technical Explanation
The paper presents a BIDS-compliant method for processing large-scale diffusion-weighted and T1-weighted MRI data. The key elements of their approach include:
- Automated Data Querying: The method includes automated processes for querying and identifying the data available for processing, ensuring a consistent and reproducible workflow.
- Heterogeneous Computational Resources: The pipeline leverages a mix of low-cost computational resources and storage systems, rather than relying on a single, expensive cloud-based solution. This allows for efficient processing and data transfer.
- High-Speed Data Throughput: The design of the workflow engine and data transfer processes enables fast data throughput, with an average of 0.60 Gb/s, compared to 0.33 Gb/s for cloud-based processing.
- Flexibility and Adaptability: The workflow design allows for quick processing of newly acquired data, while maintaining the flexibility to adapt to changes in the data or processing requirements.
The authors demonstrate that their method is comparable in processing time to cloud-based computation while being almost 20 times more cost-effective. This is achieved through the efficient use of heterogeneous computational resources and the optimization of data transfer speeds.
Critical Analysis
The paper presents a well-designed and cost-effective solution for processing large-scale medical imaging data. However, it is important to note a few potential limitations and areas for further research:
- Scalability: While the authors demonstrate the efficiency of their approach, it is unclear how the method would scale to even larger datasets or more complex processing requirements. Further testing and evaluation may be necessary to assess the limits of this approach.
- Reproducibility: The paper highlights the importance of consistent and reproducible processing, but it does not provide detailed information on the specific algorithms or software used. This could make it challenging for other researchers to replicate the results or adapt the method to their own datasets.
- Data Quality: The paper does not address the issue of data quality and how the method handles or accounts for variability in the acquired MRI data. Ensuring the quality and consistency of the processed data is crucial for downstream analyses and applications.
Overall, the paper presents a promising approach to addressing the challenges of processing large-scale medical imaging datasets in a cost-effective and efficient manner. Further research and validation of the method's scalability, reproducibility, and data quality considerations would strengthen the findings and their potential impact on the field.
Conclusion
The paper describes a novel method for efficiently and robustly processing large-scale diffusion-weighted and T1-weighted MRI data using a BIDS-compliant pipeline and heterogeneous computational resources. This approach addresses the challenges of high computational and data throughput requirements, data variability, and financial overhead associated with traditional large-scale medical imaging data processing.
The key innovation of this method is its ability to achieve processing speeds comparable to cloud-based computation while being significantly more cost-effective, making it a viable solution for researchers with limited budgets. The automated data querying, flexible workflow design, and high-speed data throughput enable efficient and consistent processing of newly acquired data.
While the paper presents a promising solution, further research is needed to assess the method's scalability, reproducibility, and ability to ensure data quality. Nonetheless, this work represents an important step towards more accessible and sustainable processing of large-scale medical imaging datasets, with potential implications for a wide range of biomedical and clinical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Scalable, reproducible, and cost-effective processing of large-scale medical imaging datasets
Michael E. Kim, Karthik Ramadass, Chenyu Gao, Praitayini Kanakaraj, Nancy R. Newlin, Gaurav Rudravaram, Kurt G. Schilling, Blake E. Dewey, Derek Archer, Timothy J. Hohman, Zhiyuan Li, Shunxing Bao, Bennett A. Landman, Nazirah Mohd Khairi
Curating, processing, and combining large-scale medical imaging datasets from national studies is a non-trivial task due to the intense computation and data throughput required, variability of acquired data, and associated financial overhead. Existing platforms or tools for large-scale data curation, processing, and storage have difficulty achieving a viable cost-to-scale ratio of computation speed for research purposes, either being too slow or too expensive. Additionally, management and consistency of processing large data in a team-driven manner is a non-trivial task. We design a BIDS-compliant method for an efficient and robust data processing pipeline of large-scale diffusion-weighted and T1-weighted MRI data compatible with low-cost, high-efficiency computing systems. Our method accomplishes automated querying of data available for processing and process running in a consistent and reproducible manner that has long-term stability, while using heterogenous low-cost computational resources and storage systems for efficient processing and data transfer. We demonstrate how our organizational structure permits efficiency in a semi-automated data processing pipeline and show how our method is comparable in processing time to cloud-based computation while being almost 20 times more cost-effective. Our design allows for fast data throughput speeds and low latency to reduce the time for data transfer between storage servers and computation servers, achieving an average of 0.60 Gb/s compared to 0.33 Gb/s for using cloud-based processing methods. The design of our workflow engine permits quick process running while maintaining flexibility to adapt to newly acquired data.
Read more8/28/2024
📊
0
Machine Learning Techniques for MRI Data Processing at Expanding Scale
Taro Langner
Imaging sites around the world generate growing amounts of medical scan data with ever more versatile and affordable technology. Large-scale studies acquire MRI for tens of thousands of participants, together with metadata ranging from lifestyle questionnaires to biochemical assays, genetic analyses and more. These large datasets encode substantial information about human health and hold considerable potential for machine learning training and analysis. This chapter examines ongoing large-scale studies and the challenge of distribution shifts between them. Transfer learning for overcoming such shifts is discussed, together with federated learning for safe access to distributed training data securely held at multiple institutions. Finally, representation learning is reviewed as a methodology for encoding embeddings that express abstract relationships in multi-modal input formats.
Read more4/23/2024
🖼️
0
VISION: Toward a Standardized Process for Radiology Image Management at the National Level
Kathryn Knight, Ioana Danciu, Olga Ovchinnikova, Jacob Hinkle, Mayanka Chandra Shekar, Debangshu Mukherjee, Eileen McAllister, Caitlin Rizy, Kelly Cho, Amy C. Justice, Joseph Erdos, Peter Kuzmak, Lauren Costa, Yuk-Lam Ho, Reddy Madipadga, Suzanne Tamang, Ian Goethert
The compilation and analysis of radiological images poses numerous challenges for researchers. The sheer volume of data as well as the computational needs of algorithms capable of operating on images are extensive. Additionally, the assembly of these images alone is difficult, as these exams may differ widely in terms of clinical context, structured annotation available for model training, modality, and patient identifiers. In this paper, we describe our experiences and challenges in establishing a trusted collection of radiology images linked to the United States Department of Veterans Affairs (VA) electronic health record database. We also discuss implications in making this repository research-ready for medical investigators. Key insights include uncovering the specific procedures required for transferring images from a clinical to a research-ready environment, as well as roadblocks and bottlenecks in this process that may hinder future efforts at automation.
Read more4/30/2024
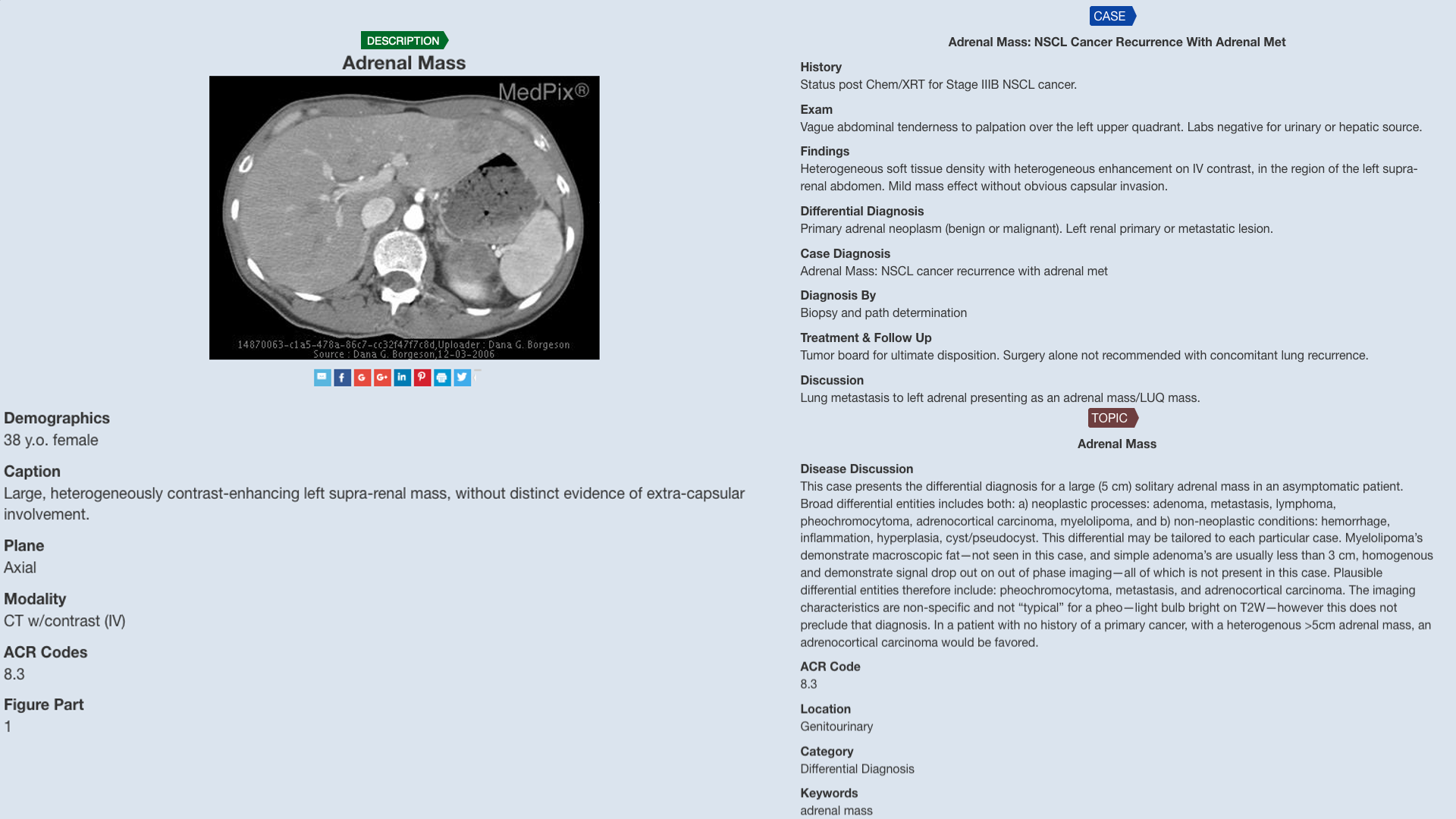
0
MedPix 2.0: A Comprehensive Multimodal Biomedical Dataset for Advanced AI Applications
Irene Siragusa, Salvatore Contino, Massimo La Ciura, Rosario Alicata, Roberto Pirrone
The increasing interest in developing Artificial Intelligence applications in the medical domain, suffers from the lack of high-quality dataset, mainly due to privacy-related issues. Moreover, the recent rising of Multimodal Large Language Models (MLLM) leads to a need for multimodal medical datasets, where clinical reports and findings are attached to the corresponding CT or MR scans. This paper illustrates the entire workflow for building the data set MedPix 2.0. Starting from the well-known multimodal dataset MedPixtextsuperscript{textregistered}, mainly used by physicians, nurses and healthcare students for Continuing Medical Education purposes, a semi-automatic pipeline was developed to extract visual and textual data followed by a manual curing procedure where noisy samples were removed, thus creating a MongoDB database. Along with the dataset, we developed a GUI aimed at navigating efficiently the MongoDB instance, and obtaining the raw data that can be easily used for training and/or fine-tuning MLLMs. To enforce this point, we also propose a CLIP-based model trained on MedPix 2.0 for scan classification tasks.
Read more7/4/2024