Scaling Diffusion Transformers to 16 Billion Parameters

0

Sign in to get full access
Overview
- Scaling Diffusion Transformers to 16 Billion Parameters
- Explores training large-scale diffusion models with over 16 billion parameters
- Introduces techniques to enable efficient training and inference of these massive models
Plain English Explanation
This paper describes the process of training extremely large diffusion models, which are a type of machine learning model used for tasks like image and text generation. The researchers were able to scale these models up to 16 billion parameters, making them significantly more powerful and capable than previous diffusion models.
To enable the training of such massive models, the researchers developed several key techniques. This includes novel approaches to model architecture, efficient training and inference methods, and new ways to represent the model parameters. These innovations allowed the researchers to push the boundaries of what was previously possible with diffusion models.
The ability to train such large-scale diffusion models opens up new possibilities for generating high-quality, diverse content across a wide range of domains. This could have significant implications for fields like creative AI, content generation, and language modeling.
Technical Explanation
The core of this research is the development of techniques to enable the training of diffusion models with over 16 billion parameters. Diffusion models are a type of generative AI system that learns to generate new data by slowly "denoising" a random input.
To scale these models to such massive sizes, the researchers explored several key innovations. First, they developed a novel model architecture based on sparse and soft expert mixtures that allowed for efficient parameter sharing and computation. This was combined with efficient training and inference methods to further improve the models' performance.
Additionally, the researchers experimented with new ways to represent the model parameters, including using ternary or sparse expert-based representations. These techniques reduced the memory footprint and computational requirements of the models, enabling their scaling to unprecedented sizes.
The researchers thoroughly evaluated the performance of their 16 billion parameter diffusion models on a range of image and text generation tasks, demonstrating their ability to produce high-quality, diverse outputs.
Critical Analysis
The researchers provide a comprehensive exploration of the techniques required to scale diffusion models to such massive sizes. However, the paper does acknowledge some potential limitations and areas for further research.
One key concern is the considerable computational and memory requirements of these large models, which may limit their practical deployment, especially on resource-constrained devices. The researchers mention that further work is needed to reduce the memory footprint and improve the efficiency of these models.
Additionally, the paper does not delve deeply into the potential biases or safety concerns that could arise from such powerful generative models. As these models become increasingly capable, it will be important to carefully consider their societal impact and develop appropriate safeguards.
Overall, this research represents a significant advance in the field of large-scale diffusion modeling, but it also raises important questions about the responsible development and deployment of these technologies. Continued research and thoughtful discussion will be crucial to ensure that these powerful tools are used in a way that benefits society.
Conclusion
This paper presents a groundbreaking approach to scaling diffusion models to an unprecedented 16 billion parameters. By developing innovative techniques for model architecture, training, and parameter representation, the researchers have pushed the boundaries of what is possible with generative AI systems.
The ability to train such large-scale diffusion models opens up new possibilities for high-quality, diverse content generation across a wide range of domains. This could have significant implications for fields like creative AI, content generation, and language modeling, potentially transforming how we interact with and create digital content.
However, the research also highlights the need to carefully consider the societal implications of these powerful technologies. As diffusion models continue to grow in capability, it will be crucial to develop appropriate safeguards and ensure their responsible development and deployment.
Overall, this work represents a significant advancement in the field of large-scale generative AI, and the insights and techniques presented here are likely to have far-reaching impacts on the future of machine learning and content creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Diffusion Transformers to 16 Billion Parameters
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Junshi Huang
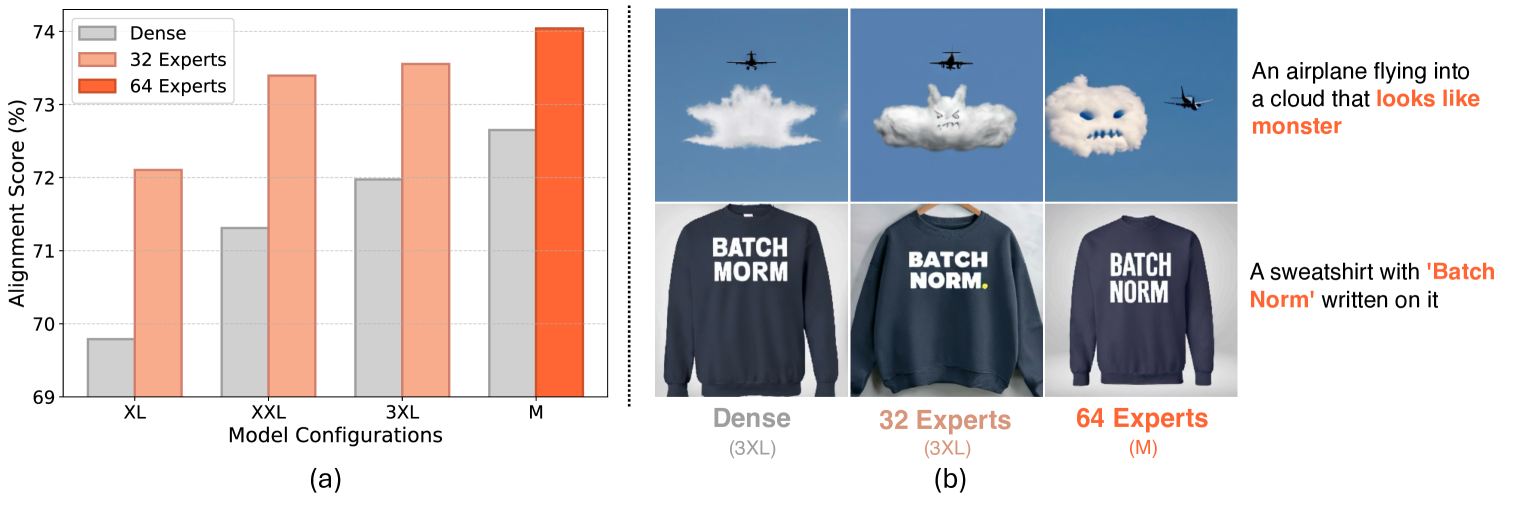
In this paper, we present DiT-MoE, a sparse version of the diffusion Transformer, that is scalable and competitive with dense networks while exhibiting highly optimized inference. The DiT-MoE includes two simple designs: shared expert routing and expert-level balance loss, thereby capturing common knowledge and reducing redundancy among the different routed experts. When applied to conditional image generation, a deep analysis of experts specialization gains some interesting observations: (i) Expert selection shows preference with spatial position and denoising time step, while insensitive with different class-conditional information; (ii) As the MoE layers go deeper, the selection of experts gradually shifts from specific spacial position to dispersion and balance. (iii) Expert specialization tends to be more concentrated at the early time step and then gradually uniform after half. We attribute it to the diffusion process that first models the low-frequency spatial information and then high-frequency complex information. Based on the above guidance, a series of DiT-MoE experimentally achieves performance on par with dense networks yet requires much less computational load during inference. More encouragingly, we demonstrate the potential of DiT-MoE with synthesized image data, scaling diffusion model at a 16.5B parameter that attains a new SoTA FID-50K score of 1.80 in 512$times$512 resolution settings. The project page: https://github.com/feizc/DiT-MoE.
Read more9/10/2024
0
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Haotian Sun, Tao Lei, Bowen Zhang, Yanghao Li, Haoshuo Huang, Ruoming Pang, Bo Dai, Nan Du
Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.
Read more10/8/2024
🛠️
1
From Sparse to Soft Mixtures of Experts
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
Sparse mixture of expert architectures (MoEs) scale model capacity without significant increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoEs, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity (and performance) at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms dense Transformers (ViTs) and popular MoEs (Tokens Choice and Experts Choice). Furthermore, Soft MoE scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, with only 2% increased inference time, and substantially better quality.
Read more5/28/2024

0
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Byeongjun Park, Hyojun Go, Jin-Young Kim, Sangmin Woo, Seokil Ham, Changick Kim
Diffusion models have achieved remarkable success across a range of generative tasks. Recent efforts to enhance diffusion model architectures have reimagined them as a form of multi-task learning, where each task corresponds to a denoising task at a specific noise level. While these efforts have focused on parameter isolation and task routing, they fall short of capturing detailed inter-task relationships and risk losing semantic information, respectively. In response, we introduce Switch Diffusion Transformer (Switch-DiT), which establishes inter-task relationships between conflicting tasks without compromising semantic information. To achieve this, we employ a sparse mixture-of-experts within each transformer block to utilize semantic information and facilitate handling conflicts in tasks through parameter isolation. Additionally, we propose a diffusion prior loss, encouraging similar tasks to share their denoising paths while isolating conflicting ones. Through these, each transformer block contains a shared expert across all tasks, where the common and task-specific denoising paths enable the diffusion model to construct its beneficial way of synergizing denoising tasks. Extensive experiments validate the effectiveness of our approach in improving both image quality and convergence rate, and further analysis demonstrates that Switch-DiT constructs tailored denoising paths across various generation scenarios.
Read more7/11/2024