XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection
2403.18926
2
0
Abstract
Sparse models, including sparse Mixture-of-Experts (MoE) models, have emerged as an effective approach for scaling Transformer models. However, they often suffer from computational inefficiency since a significant number of parameters are unnecessarily involved in computations via multiplying values by zero or low activation values. To address this issue, we present tool, a novel MoE designed to enhance both the efficacy and efficiency of sparse MoE models. tool leverages small experts and a threshold-based router to enable tokens to selectively engage only essential parameters. Our extensive experiments on language modeling and machine translation tasks demonstrate that tool can enhance model performance while decreasing the computation load at MoE layers by over 50% without sacrificing performance. Furthermore, we present the versatility of tool by applying it to dense models, enabling sparse computation during inference. We provide a comprehensive analysis and make our code available at https://github.com/ysngki/XMoE.
Create account to get full access
Overview
- This paper introduces a novel approach to enhancing the efficiency of sparse machine learning models, called "Sparser Selection".
- The key idea is to train a sparse model with an additional sparsity-inducing regularization term, which encourages even sparser selection of model parameters during inference.
- This technique can lead to significant improvements in inference speed and memory usage, without compromising model accuracy.
Plain English Explanation
Machine learning models are often designed to be "sparse", meaning they only use a small subset of the available model parameters to make predictions. This sparsity can lead to faster and more efficient inference, which is critical for many real-world applications.
However, the process of training these sparse models can be complex, often requiring careful tuning of various hyperparameters. The authors of this paper propose a new method, called "Sparser Selection", that makes the training process more efficient and effective.
The core idea is to add an additional regularization term to the training objective that encourages the model to become even sparser during the training process. This means that the final model will use an even smaller number of parameters to make predictions, leading to faster and more memory-efficient inference.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, showing that "Sparser Selection" can achieve significant improvements in inference speed and memory usage, while maintaining the same level of accuracy as traditional sparse models. This could have important implications for the deployment of machine learning models in resource-constrained settings, such as edge devices or mobile applications.
Technical Explanation
The authors start by providing a background on the problem of sparse model training and inference, highlighting the importance of balancing model complexity, accuracy, and computational efficiency. They discuss prior approaches, such as dense training with sparse inference and mixture-of-experts models, which have aimed to address this challenge.
The key contribution of this paper is the "Sparser Selection" method, which introduces an additional sparsity-inducing regularization term to the training objective. This term encourages the model to learn a particularly sparse set of parameters, resulting in a more efficient inference process.
The authors evaluate their approach on several benchmark tasks, including language modeling and image classification. They compare the performance of "Sparser Selection" to traditional sparse modeling techniques, as well as dense models with sparse inference. The results show that their method can achieve significant improvements in inference speed and memory usage, while maintaining comparable accuracy to the baseline models.
Critical Analysis
The authors acknowledge some limitations of their approach, such as the potential for the additional regularization term to negatively impact model accuracy in certain cases. They also note that the optimal balance between sparsity and accuracy may depend on the specific application and hardware constraints.
One potential area for further research could be exploring the interaction between "Sparser Selection" and other sparse modeling techniques, such as dynamic mixture-of-experts models or regularization-based approaches. It would also be interesting to see how the method performs on a wider range of tasks and datasets, particularly in the context of real-world deployment scenarios.
Conclusion
Overall, the "Sparser Selection" method presented in this paper offers a promising approach to enhancing the efficiency of sparse machine learning models. By introducing an additional sparsity-inducing regularization term during training, the authors demonstrate the ability to achieve significant improvements in inference speed and memory usage, without compromising model accuracy.
This work has the potential to contribute to the broader efforts in the field of efficient machine learning, which aims to develop models that can be deployed effectively in resource-constrained environments. The insights and techniques developed in this paper could be particularly valuable for applications that require high-performance, low-latency, and energy-efficient machine learning, such as edge computing and mobile devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
From Sparse to Soft Mixtures of Experts
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
0
0
Sparse mixture of expert architectures (MoEs) scale model capacity without significant increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoEs, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity (and performance) at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms dense Transformers (ViTs) and popular MoEs (Tokens Choice and Experts Choice). Furthermore, Soft MoE scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, with only 2% increased inference time, and substantially better quality.
5/28/2024
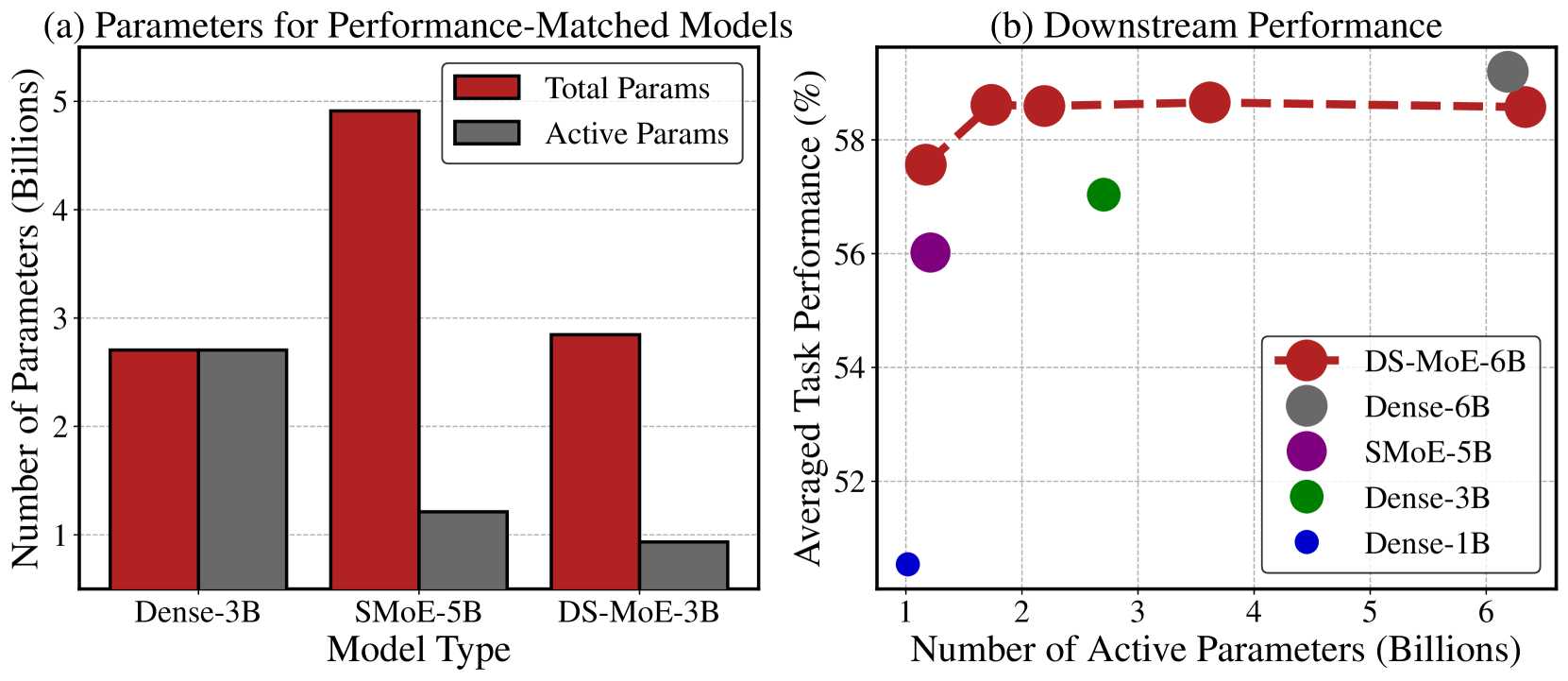
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
🔄
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Tao Lin
0
0
The Sparse Mixture of Experts (SMoE) has been widely employed to enhance the efficiency of training and inference for Transformer-based foundational models, yielding promising results. However, the performance of SMoE heavily depends on the choice of hyper-parameters, such as the number of experts and the number of experts to be activated (referred to as top-k), resulting in significant computational overhead due to the extensive model training by searching over various hyper-parameter configurations. As a remedy, we introduce the Dynamic Mixture of Experts (DynMoE) technique. DynMoE incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training. Extensive numerical results across Vision, Language, and Vision-Language tasks demonstrate the effectiveness of our approach to achieve competitive performance compared to GMoE for vision and language tasks, and MoE-LLaVA for vision-language tasks, while maintaining efficiency by activating fewer parameters. Our code is available at https://github.com/LINs-lab/DynMoE.
5/24/2024