From Sparse to Soft Mixtures of Experts

1
🔮
Sign in to get full access
Overview
- Sparse mixture of expert (MoE) architectures can scale model capacity without significant increases in training or inference costs
- However, MoEs suffer from issues like training instability, token dropping, inability to scale the number of experts, and ineffective finetuning
- This paper proposes Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges while maintaining the benefits of MoEs
Plain English Explanation
Soft MoE is a type of AI model that uses a "mixture of experts" approach. This means the model has multiple specialized "expert" components that each focus on different parts of the input. This allows the model to handle more complex tasks without dramatically increasing the overall size and cost of the model.
Traditional mixture of expert models have some issues, like being unstable during training, dropping important information, struggling to scale up the number of experts, and having trouble fine-tuning the model for new tasks. Soft MoE aims to address these problems.
The key innovation in Soft MoE is that it performs a "soft assignment" - instead of strictly routing each input to a single expert, it passes weighted combinations of the inputs to each expert. This allows the experts to collaborate and share information more effectively. As a result, Soft MoE can achieve better performance than dense Transformer models and other MoE approaches, while still maintaining the efficiency benefits of the mixture of experts architecture.
Technical Explanation
Soft MoE is a fully-differentiable sparse Transformer model that builds on prior work in mixture of experts (MoEs) architectures. Like other MoEs, Soft MoE has multiple expert components that each specialize on different parts of the input. However, Soft MoE uses a "soft assignment" mechanism, where different weighted combinations of the input tokens are passed to each expert, rather than strictly routing each token to a single expert.
This soft assignment approach allows the experts to collaborate and share information more effectively, addressing issues seen in prior MoE models like training instability, token dropping, inability to scale experts, and ineffective finetuning. Additionally, because the experts only process a subset of the combined input tokens, Soft MoE can achieve larger model capacity and better performance compared to dense Transformer models, with only a small increase in inference time.
The paper evaluates Soft MoE on visual recognition tasks, where it significantly outperforms both dense Transformers (ViTs) and popular MoE approaches like Tokens-to-Choose and Experts-to-Choose. Furthermore, Soft MoE scales well - the authors demonstrate a Soft MoE Huge/14 model with 128 experts in 16 MoE layers that has over 40x more parameters than a ViT Huge/14, but with only a 2% increase in inference time, and substantially better quality.
Critical Analysis
The Soft MoE paper makes a compelling case for this new approach to mixture of experts architectures. By addressing key limitations of prior MoE models, Soft MoE demonstrates the potential for sparse, efficient models to outperform dense Transformer architectures on a range of tasks.
However, the paper does not delve into potential drawbacks or limitations of the Soft MoE approach. For example, the soft assignment mechanism adds computational overhead compared to hard routing, and the impact on training time and stability is not explored in depth. Additionally, the evaluation is limited to visual recognition tasks, so the generalizability of Soft MoE to other domains like natural language processing is unclear.
Furthermore, the authors do not consider potential societal impacts or ethical implications of deploying large, high-capacity models like Soft MoE Huge. As these models become more powerful and ubiquitous, it will be important to carefully examine issues around fairness, transparency, and responsible AI development.
Overall, the Soft MoE paper represents an exciting advance in efficient neural network architectures. But as with any powerful new technology, a more thorough critical analysis is warranted to fully understand its limitations and potential risks.
Conclusion
The Soft MoE paper proposes a novel sparse Transformer architecture that addresses key challenges with prior mixture of experts models. By using a fully-differentiable soft assignment mechanism, Soft MoE is able to scale model capacity and performance without significant increases in training or inference cost.
Evaluated on visual recognition tasks, Soft MoE demonstrates significant improvements over dense Transformer models and other popular MoE approaches. The ability to build extremely large Soft MoE models, like the 40x larger Soft MoE Huge variant, while maintaining efficient inference, suggests this architecture could be a powerful tool for building high-capacity AI systems.
However, the paper does not fully explore the limitations and potential risks of this technology. As Soft MoE and similar efficient models become more prominent, it will be important to carefully consider their societal impact and ensure they are developed responsibly. Overall, the Soft MoE paper represents an important advance, but further research and critical analysis will be needed to understand its broader implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
1
From Sparse to Soft Mixtures of Experts
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
Sparse mixture of expert architectures (MoEs) scale model capacity without significant increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoEs, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity (and performance) at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms dense Transformers (ViTs) and popular MoEs (Tokens Choice and Experts Choice). Furthermore, Soft MoE scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, with only 2% increased inference time, and substantially better quality.
Read more5/28/2024
0
Beyond Parameter Count: Implicit Bias in Soft Mixture of Experts
Youngseog Chung, Dhruv Malik, Jeff Schneider, Yuanzhi Li, Aarti Singh
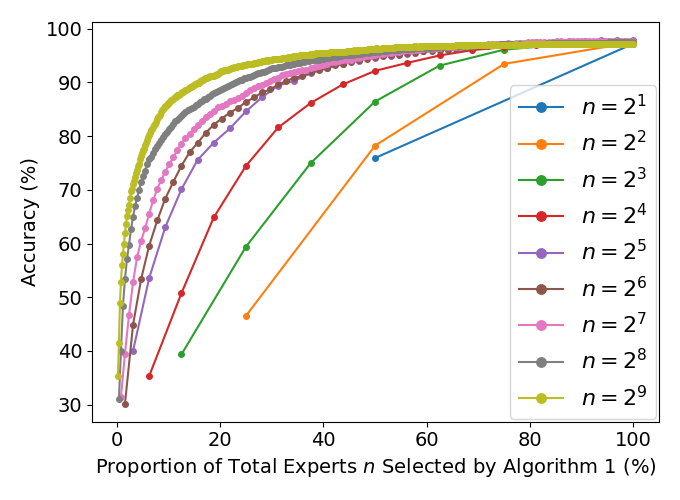
The traditional viewpoint on Sparse Mixture of Experts (MoE) models is that instead of training a single large expert, which is computationally expensive, we can train many small experts. The hope is that if the total parameter count of the small experts equals that of the singular large expert, then we retain the representation power of the large expert while gaining computational tractability and promoting expert specialization. The recently introduced Soft MoE replaces the Sparse MoE's discrete routing mechanism with a differentiable gating function that smoothly mixes tokens. While this smooth gating function successfully mitigates the various training instabilities associated with Sparse MoE, it is unclear whether it induces implicit biases that affect Soft MoE's representation power or potential for expert specialization. We prove that Soft MoE with a single arbitrarily powerful expert cannot represent simple convex functions. This justifies that Soft MoE's success cannot be explained by the traditional viewpoint of many small experts collectively mimicking the representation power of a single large expert, and that multiple experts are actually necessary to achieve good representation power (even for a fixed total parameter count). Continuing along this line of investigation, we introduce a notion of expert specialization for Soft MoE, and while varying the number of experts yet fixing the total parameter count, we consider the following (computationally intractable) task. Given any input, how can we discover the expert subset that is specialized to predict this input's label? We empirically show that when there are many small experts, the architecture is implicitly biased in a fashion that allows us to efficiently approximate the specialized expert subset. Our method can be easily implemented to potentially reduce computation during inference.
Read more9/4/2024
0
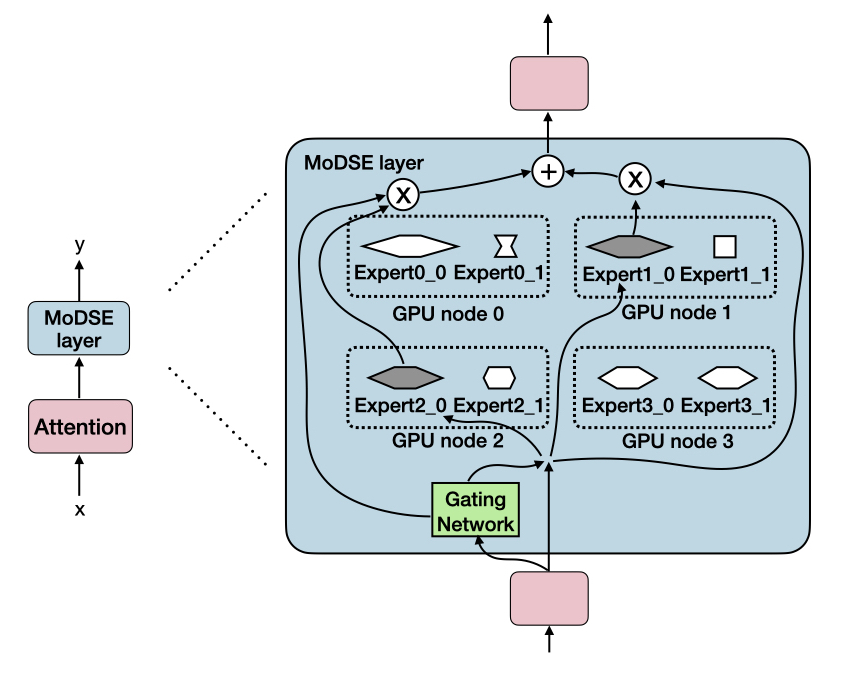
Mixture of Diverse Size Experts
Manxi Sun, Wei Liu, Jian Luan, Pengzhi Gao, Bin Wang
The Sparsely-Activated Mixture-of-Experts (MoE) has gained increasing popularity for scaling up large language models (LLMs) without exploding computational costs. Despite its success, the current design faces a challenge where all experts have the same size, limiting the ability of tokens to choose the experts with the most appropriate size for generating the next token. In this paper, we propose the Mixture of Diverse Size Experts (MoDSE), a new MoE architecture with layers designed to have experts of different sizes. Our analysis of difficult token generation tasks shows that experts of various sizes achieve better predictions, and the routing path of the experts tends to be stable after a training period. However, having experts of diverse sizes can lead to uneven workload distribution. To tackle this limitation, we introduce an expert-pair allocation strategy to evenly distribute the workload across multiple GPUs. Comprehensive evaluations across multiple benchmarks demonstrate the effectiveness of MoDSE, as it outperforms existing MoEs by allocating the parameter budget to experts adaptively while maintaining the same total parameter size and the number of experts.
Read more9/20/2024
1
XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection
Yuanhang Yang, Shiyi Qi, Wenchao Gu, Chaozheng Wang, Cuiyun Gao, Zenglin Xu
Sparse models, including sparse Mixture-of-Experts (MoE) models, have emerged as an effective approach for scaling Transformer models. However, they often suffer from computational inefficiency since a significant number of parameters are unnecessarily involved in computations via multiplying values by zero or low activation values. To address this issue, we present tool, a novel MoE designed to enhance both the efficacy and efficiency of sparse MoE models. tool leverages small experts and a threshold-based router to enable tokens to selectively engage only essential parameters. Our extensive experiments on language modeling and machine translation tasks demonstrate that tool can enhance model performance while decreasing the computation load at MoE layers by over 50% without sacrificing performance. Furthermore, we present the versatility of tool by applying it to dense models, enabling sparse computation during inference. We provide a comprehensive analysis and make our code available at https://github.com/ysngki/XMoE.
Read more5/27/2024