Scaling Law Hypothesis for Multimodal Model

0

Sign in to get full access
Overview
- This paper proposes a scaling law hypothesis for multimodal models that can predict model performance based on dataset size and model size.
- The authors develop a bivariate scaling law model that captures the relationship between dataset size, model size, and task performance.
- They validate their hypothesis on several large-scale multimodal datasets and models, demonstrating its ability to accurately predict performance.
Plain English Explanation
The paper explores the idea that there may be a fundamental scaling law that governs the relationship between the size of a machine learning model, the amount of training data used, and the model's performance on a task. The authors focus on multimodal models, which are trained on a combination of text, images, and other data types.
The key insight is that as you increase the size of the model and the amount of training data, the model's performance tends to improve in a predictable way. The authors develop a mathematical model, called a bivariate scaling law, that can capture this relationship. This allows them to forecast how well a multimodal model will perform based on its size and the size of the dataset it was trained on.
By validating their hypothesis on several large-scale multimodal datasets and models, the authors demonstrate that this scaling law holds true. This is an important finding because it suggests that there may be fundamental underlying principles governing the behavior of these complex AI systems. Understanding these principles could help researchers and engineers build more capable and predictable language models in the future.
Technical Explanation
The core of the paper is the authors' proposal of a bivariate scaling law that models the relationship between multimodal model size, dataset size, and task performance. They hypothesize that model performance (P) can be expressed as:
P = a * (model size)^b * (dataset size)^c
Where a, b, and c are constants that can be empirically determined.
To validate this hypothesis, the authors conduct experiments on several large-scale multimodal datasets and models, including:
- LAION-400M, a 400 million image-text pair dataset
- CLIP, a state-of-the-art multimodal model trained on a large web-crawled dataset
- VisualGPT, a large language model trained on both text and images
By analyzing the scaling behavior of these models and datasets, the authors are able to empirically determine the values of the constants a, b, and c in the bivariate scaling law. They show that this model can accurately predict the performance of multimodal systems across a wide range of dataset and model sizes.
Critical Analysis
The authors present a compelling case for the existence of a scaling law governing multimodal models. However, there are a few potential limitations and areas for further research:
- The bivariate scaling law assumes a simple power-law relationship between the variables. More complex functional forms may be required to capture the full complexity of these systems.
- The experiments are limited to a small number of datasets and models. Validating the scaling law on a broader range of multimodal tasks and architectures would strengthen the conclusions.
- The paper does not explore the underlying mechanisms that give rise to the observed scaling behavior. Understanding these mechanisms could lead to more principled model design and optimization.
Overall, this paper makes an important contribution by proposing a unifying theoretical framework for understanding the behavior of multimodal AI systems. Further research in this direction could yield valuable insights for the development of more powerful and predictable language models.
Conclusion
This paper introduces a scaling law hypothesis for multimodal models, which proposes that there is a fundamental relationship between model size, dataset size, and model performance that can be captured by a bivariate power law. Through extensive experiments, the authors demonstrate the validity of this hypothesis and show that it can accurately predict the performance of large-scale multimodal systems.
By uncovering these underlying scaling principles, this research represents an important step towards a more systematic and principled understanding of complex AI systems. The insights gained could inform the design of future generations of multimodal models and help researchers and engineers build more capable and predictable language models that can tackle increasingly challenging tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Law Hypothesis for Multimodal Model
Qingyun Sun, Zhen Guo
We propose a scaling law hypothesis for multimodal models processing text, audio, images, and video within a shared token and embedding space. Our framework predicts model performance based on modality-specific compression and tokenization efficiency, extending established scaling laws from text-based decoder models to mixed-modality systems. We explore whether leveraging more training data in multiple modalities can reduce the size of the multimodal model, enabling efficient deployment on resource-constrained devices.
Read more9/18/2024
0
Scaling Properties of Speech Language Models
Santiago Cuervo, Ricard Marxer
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
Read more4/17/2024
📊
0
Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining
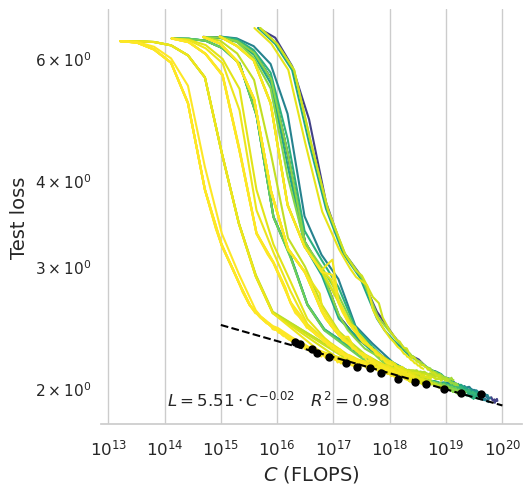
Ce Ge, Zhijian Ma, Daoyuan Chen, Yaliang Li, Bolin Ding
Large language models exhibit exceptional generalization capabilities, primarily attributed to the utilization of diversely sourced data. However, conventional practices in integrating this diverse data heavily rely on heuristic schemes, lacking theoretical guidance. This research tackles these limitations by investigating strategies based on low-cost proxies for data mixtures, with the aim of streamlining data curation to enhance training efficiency. Specifically, we propose a unified scaling law, termed $textbf{BiMix}$, which accurately models the bivariate scaling behaviors of both data quantity and mixing proportions. We conduct systematic experiments and provide empirical evidence for the predictive power and fundamental principles of $textbf{BiMix}$. Notably, our findings reveal that entropy-driven training-free data mixtures can achieve comparable or even better performance than more resource-intensive methods. We hope that our quantitative insights can shed light on further judicious research and development in cost-effective language modeling.
Read more7/12/2024
0
Temporal Scaling Law for Large Language Models
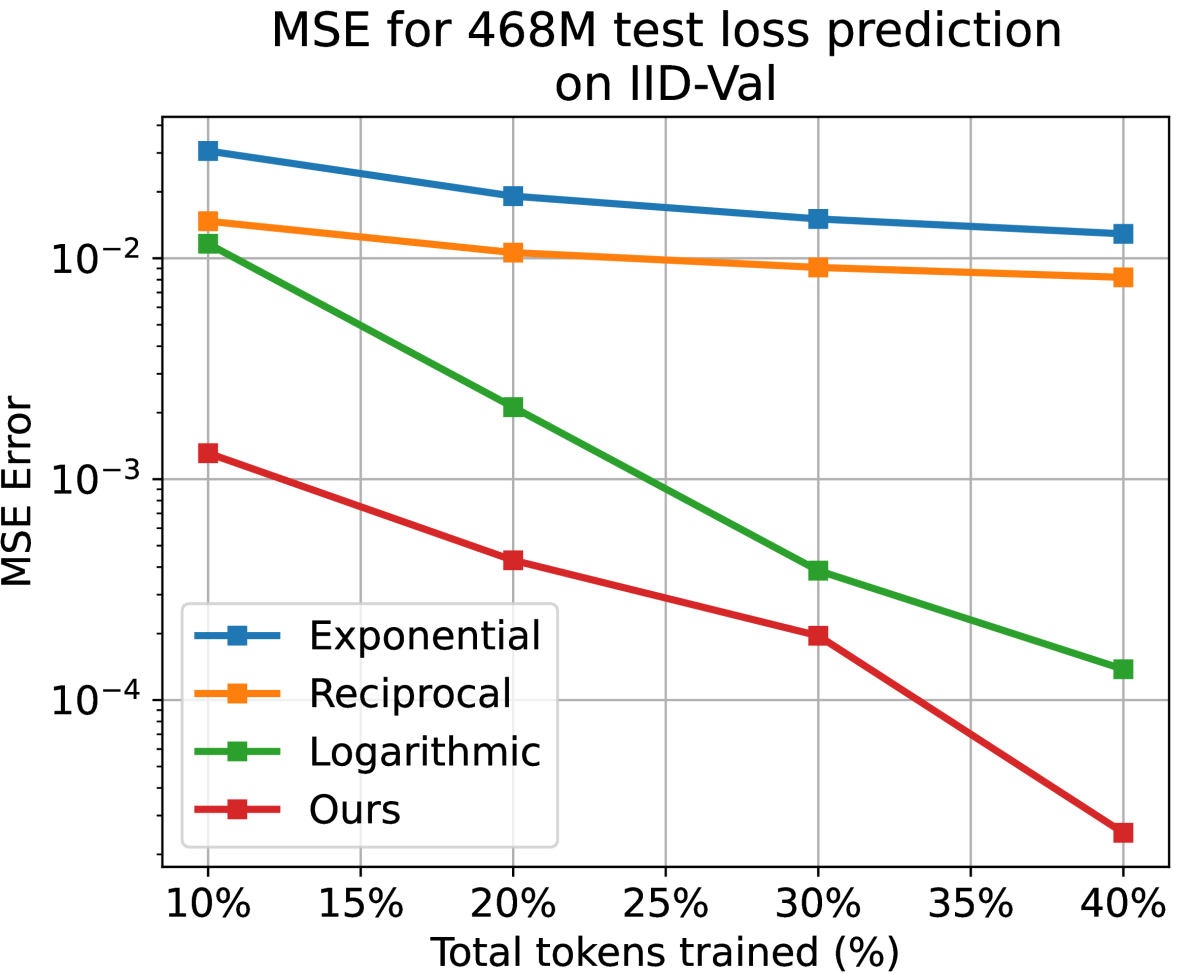
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
Read more6/18/2024