Scaling Laws For Diffusion Transformers

0

Sign in to get full access
Overview
- This paper studies the scaling laws of diffusion transformers, a type of machine learning model used for text and image generation.
- The researchers analyze how the performance of diffusion transformers changes as the model size and amount of training data are increased.
- They find that diffusion transformers exhibit strong scaling laws, meaning their performance improves predictably as the model and dataset size grow.
- This has important implications for the development of more capable and efficient diffusion-based AI systems.
Plain English Explanation
Diffusion transformers are a type of AI model that can be used to generate text, images, and other types of data. This paper looks at how the performance of these models changes as they get bigger (more parameters) and are trained on more data.
The researchers found that diffusion transformers have "scaling laws" - their performance improves in a predictable way as the model size and training dataset grow. This means that if you double the model size and training data, you can expect to see a consistent improvement in the model's capabilities.
This is an important discovery because it suggests that diffusion transformers can become increasingly powerful and capable as computing resources and datasets continue to expand. It provides a roadmap for how these models can be scaled up to tackle more and more challenging AI problems in the future.
Technical Explanation
The paper examines the scaling laws of diffusion transformers, a type of generative AI model that uses a process of gradually adding noise to data (diffusion) and then learning to reverse that process to generate new samples.
The researchers analyze how the performance of diffusion transformers scales as a function of model size (number of parameters) and dataset size. They train models of varying sizes on datasets of different scales and measure metrics like sample quality and sample diversity.
The key finding is that diffusion transformers exhibit strong scaling laws - their performance scales predictably with increases in model and dataset size. For example, doubling the model size and training data leads to a consistent improvement in sample quality and diversity.
This contrasts with some other AI models that do not show such clean scaling laws. The researchers hypothesize that the modular and flexible nature of the diffusion process gives diffusion transformers an advantage when it comes to scaling.
Critical Analysis
The paper provides a thorough and rigorous analysis of the scaling properties of diffusion transformers. The experimental design is sound, and the results are convincingly demonstrated.
One potential limitation is that the study is focused on a specific architecture and training setup for diffusion transformers. It's possible that other variations or implementation choices could impact the scaling laws in different ways. The researchers acknowledge this and suggest further study is needed.
Additionally, the paper does not delve deeply into the underlying reasons why diffusion transformers exhibit such clean scaling laws. More investigation into the theoretical foundations could provide additional insights.
Overall, this research makes an important contribution to understanding the scalability of diffusion-based generative models. The findings have significant implications for the continued development and deployment of these models as AI systems become more powerful and prevalent.
Conclusion
This paper demonstrates that diffusion transformers, a powerful class of generative AI models, exhibit strong and predictable scaling laws. As the model size and training dataset grow, the performance of diffusion transformers improves in a consistent manner.
This scaling property is a crucial advantage for the continued advancement of diffusion-based AI systems. It suggests that these models can become increasingly capable as computing resources and data availability increase in the future. The findings in this paper provide a foundation for the development of ever-more powerful and efficient diffusion-based generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Scaling Laws For Diffusion Transformers
Zhengyang Liang, Hao He, Ceyuan Yang, Bo Dai
Diffusion transformers (DiT) have already achieved appealing synthesis and scaling properties in content recreation, e.g., image and video generation. However, scaling laws of DiT are less explored, which usually offer precise predictions regarding optimal model size and data requirements given a specific compute budget. Therefore, experiments across a broad range of compute budgets, from 1e17 to 6e18 FLOPs are conducted to confirm the existence of scaling laws in DiT for the first time. Concretely, the loss of pretraining DiT also follows a power-law relationship with the involved compute. Based on the scaling law, we can not only determine the optimal model size and required data but also accurately predict the text-to-image generation loss given a model with 1B parameters and a compute budget of 1e21 FLOPs. Additionally, we also demonstrate that the trend of pre-training loss matches the generation performances (e.g., FID), even across various datasets, which complements the mapping from compute to synthesis quality and thus provides a predictable benchmark that assesses model performance and data quality at a reduced cost.
Read more10/11/2024
0
On the Scalability of Diffusion-based Text-to-Image Generation
Hao Li, Yang Zou, Ying Wang, Orchid Majumder, Yusheng Xie, R. Manmatha, Ashwin Swaminathan, Zhuowen Tu, Stefano Ermon, Stefano Soatto
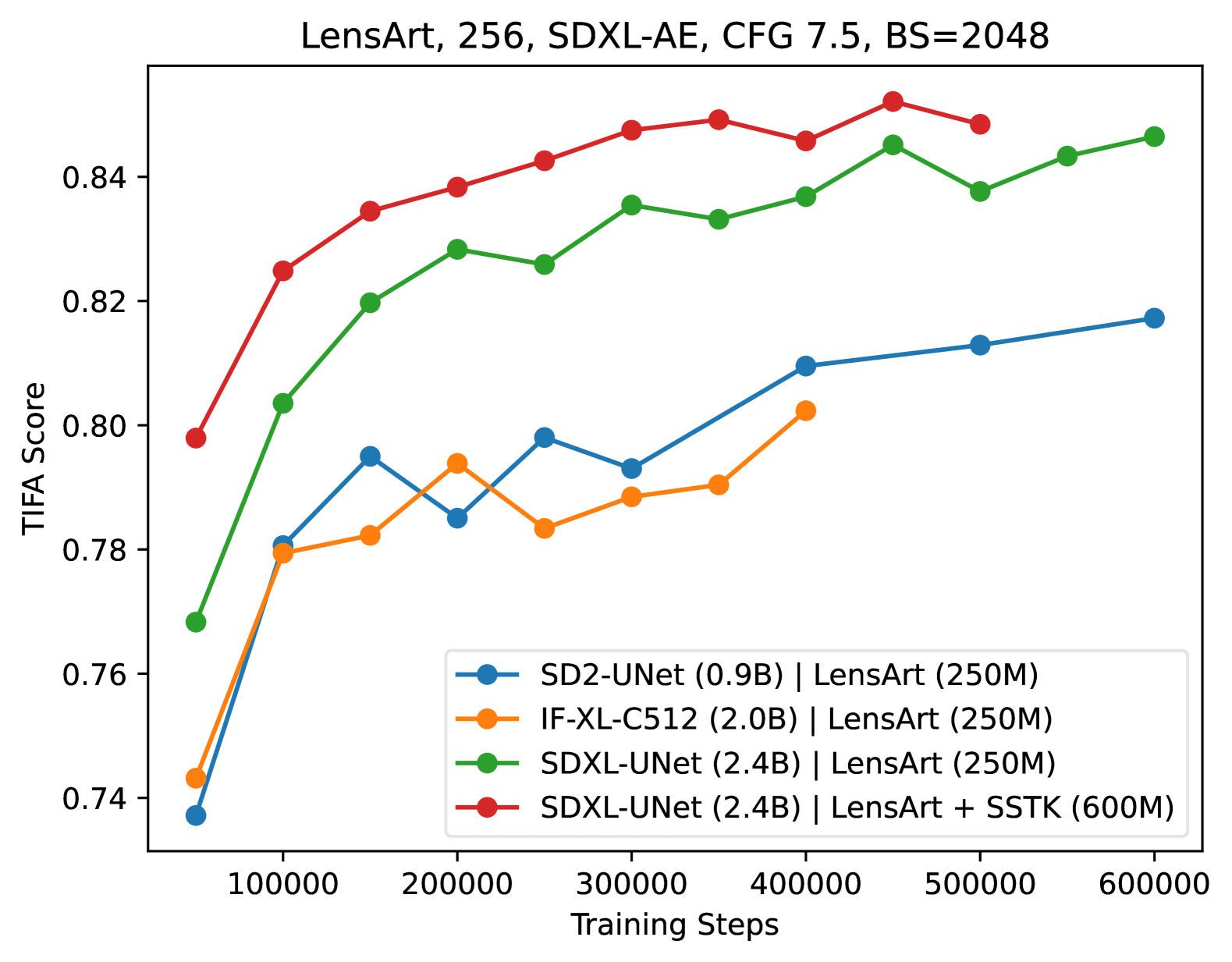
Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
Read more4/4/2024
⛏️
0
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
Read more5/24/2024
0
Dynamic Diffusion Transformer
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Yibing Song, Gao Huang, Fan Wang, Yang You
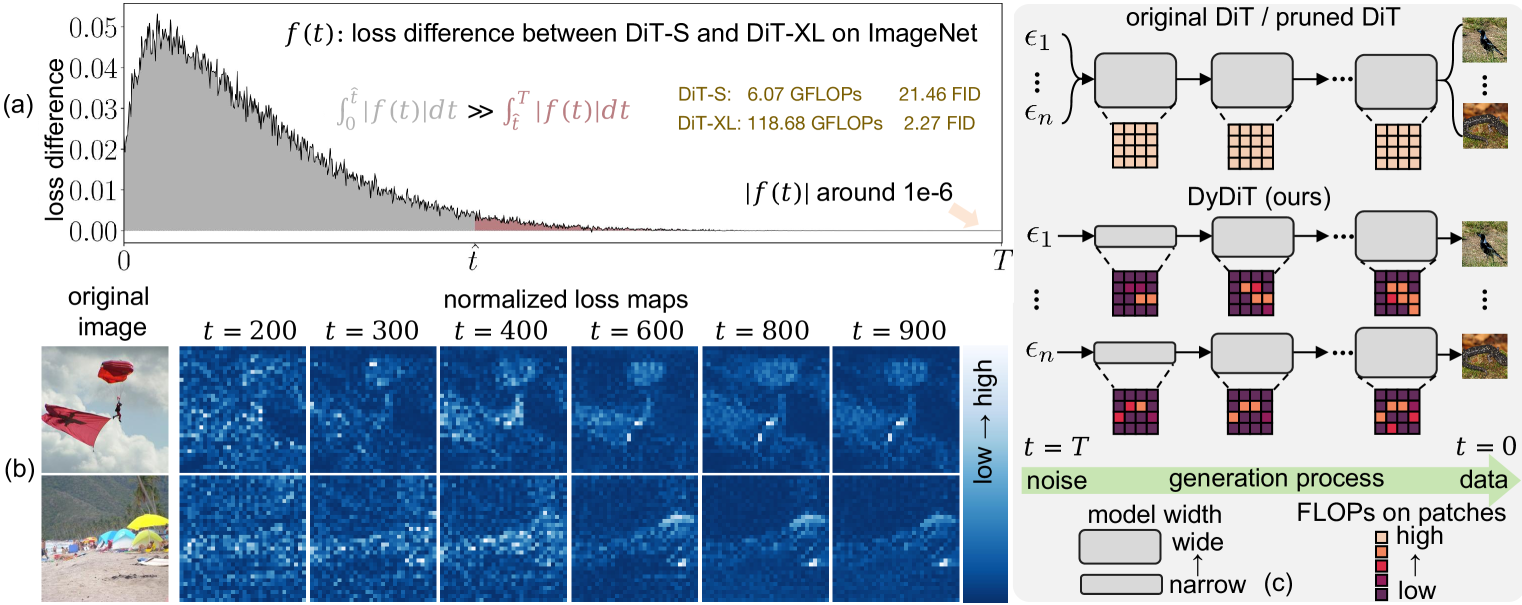
Diffusion Transformer (DiT), an emerging diffusion model for image generation, has demonstrated superior performance but suffers from substantial computational costs. Our investigations reveal that these costs stem from the static inference paradigm, which inevitably introduces redundant computation in certain diffusion timesteps and spatial regions. To address this inefficiency, we propose Dynamic Diffusion Transformer (DyDiT), an architecture that dynamically adjusts its computation along both timestep and spatial dimensions during generation. Specifically, we introduce a Timestep-wise Dynamic Width (TDW) approach that adapts model width conditioned on the generation timesteps. In addition, we design a Spatial-wise Dynamic Token (SDT) strategy to avoid redundant computation at unnecessary spatial locations. Extensive experiments on various datasets and different-sized models verify the superiority of DyDiT. Notably, with <3% additional fine-tuning iterations, our method reduces the FLOPs of DiT-XL by 51%, accelerates generation by 1.73, and achieves a competitive FID score of 2.07 on ImageNet. The code is publicly available at https://github.com/NUS-HPC-AI-Lab/ Dynamic-Diffusion-Transformer.
Read more10/10/2024