Scaling Laws Do Not Scale

0
🔮
Sign in to get full access
Overview
- The paper critically examines claims that as the size of training datasets for AI models increases, the model's performance will correspondingly increase (known as scaling laws).
- The authors argue that the scaling law relationship depends on the metrics used to measure performance, which may not align with how different communities perceive the quality of the model's output.
- As AI systems impact larger and more diverse groups of people, the values and preferences of the communities represented in the training or evaluation datasets may not be reflected in the metrics used to evaluate model performance.
Plain English Explanation
The paper challenges the idea that making AI models larger and training them on bigger and bigger datasets will always lead to better performance. The authors argue that this scaling law relationship depends on the specific ways that "performance" is measured, which may not match how different groups of people actually judge the quality of the model's outputs.
As AI systems start affecting more and more diverse communities, the values and preferences of those communities may not be fully represented in the datasets used to train the models or the metrics used to evaluate them. Different communities may have different ideas about what makes a good AI system, and these differences could lead to difficult choices about which metrics to use that don't satisfy everyone.
The authors suggest that the motivation for continuously expanding datasets may be based on flawed assumptions about model performance. Just because a model gets bigger and is trained on more data doesn't mean it will actually improve for everyone it affects. Instead, the authors encourage the AI field to rethink its values and norms, avoid claims of universality for large models, and explore more local, small-scale designs as alternatives to the push for ever-larger AI systems.
Technical Explanation
The paper draws on literature from social sciences and machine learning to critically examine the claims of "scaling laws" - the idea that as the size of a training dataset for an AI model increases, the model's performance will scale correspondingly.
The authors argue that this scaling law relationship depends on the specific metrics used to measure model performance, which may not accurately reflect how different groups of people perceive the quality of the model's outputs. As AI systems impact an ever-growing and more diverse set of communities, the values and preferences of those communities represented in the training or evaluation datasets may not be fully captured by the performance metrics.
Additionally, different communities may have values that are in tension with each other, making it difficult to choose metrics that satisfy everyone. This threatens the validity of claims that model performance universally improves as dataset size increases.
The paper concludes by suggesting that the drive to continuously expand datasets for AI training may be based on flawed assumptions about model performance. Models may not necessarily improve for all impacted communities as dataset size grows. The authors encourage the AI field to rethink its norms and values, resist claims of universality for large models, and explore more localized, small-scale designs as alternatives to the push for ever-larger AI systems.
Critical Analysis
The paper raises important concerns about the limitations of scaling laws and the potential misalignment between performance metrics and the values of diverse communities impacted by AI systems.
The authors acknowledge that as AI systems become more pervasive, the number of distinct communities represented in training or evaluation datasets will grow. This increases the likelihood that the preferences and values of certain communities will not be reflected in the performance metrics used to judge model quality.
While the paper does not present empirical evidence of this misalignment, it provides a compelling theoretical framework and cites relevant literature from the social sciences to support its claims. The authors encourage further research to better understand how different communities perceive and value the outputs of AI models.
One potential limitation of the paper is that it does not offer specific solutions or alternative approaches beyond suggesting more localized, small-scale designs and rethinking norms in AI development. Further research could explore practical ways to incorporate diverse community values into model development and evaluation processes.
Nevertheless, the paper makes an important contribution by challenging the unquestioned pursuit of ever-larger AI models and datasets. It encourages the AI community to think critically about the assumptions underlying scaling laws and to consider the ethical implications of developing models that may not serve the needs of all affected groups.
Conclusion
This paper provides a critical examination of the claims around scaling laws in AI model performance, arguing that the relationship between dataset size and model quality is more complex than often assumed.
The key insight is that the metrics used to measure model performance may not align with how different communities perceive the value and quality of the model's outputs. As AI systems become more widespread, this misalignment is likely to become more pronounced, potentially leading to difficult choices about which metrics to prioritize.
The paper encourages the AI community to rethink its norms and values, resist claims of universality for large models, and explore more localized, small-scale designs as alternatives to the relentless pursuit of ever-larger datasets and models. This challenge to the scaling law narrative is an important contribution that could help steer the field of AI development in a more thoughtful and inclusive direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Scaling Laws Do Not Scale
Fernando Diaz, Michael Madaio
Recent work has advocated for training AI models on ever-larger datasets, arguing that as the size of a dataset increases, the performance of a model trained on that dataset will correspondingly increase (referred to as scaling laws). In this paper, we draw on literature from the social sciences and machine learning to critically interrogate these claims. We argue that this scaling law relationship depends on metrics used to measure performance that may not correspond with how different groups of people perceive the quality of models' output. As the size of datasets used to train large AI models grows and AI systems impact ever larger groups of people, the number of distinct communities represented in training or evaluation datasets grows. It is thus even more likely that communities represented in datasets may have values or preferences not reflected in (or at odds with) the metrics used to evaluate model performance in scaling laws. Different communities may also have values in tension with each other, leading to difficult, potentially irreconcilable choices about metrics used for model evaluations -- threatening the validity of claims that model performance is improving at scale. We end the paper with implications for AI development: that the motivation for scraping ever-larger datasets may be based on fundamentally flawed assumptions about model performance. That is, models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models. We suggest opportunities for the field to rethink norms and values in AI development, resisting claims for universality of large models, fostering more local, small-scale designs, and other ways to resist the impetus towards scale in AI.
Read more7/30/2024
1
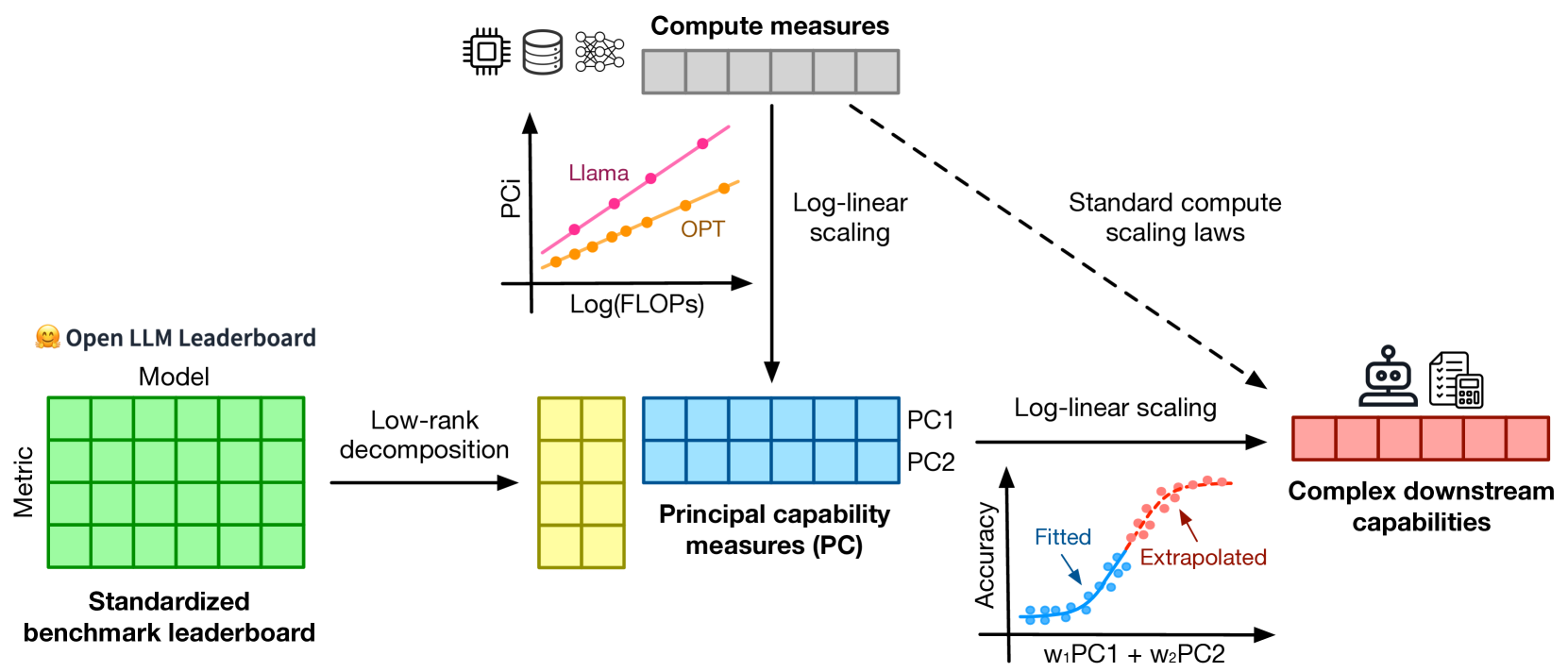
Observational Scaling Laws and the Predictability of Language Model Performance
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Read more5/20/2024
0
Inverse Scaling: When Bigger Isn't Better
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, Tom Tseng, Tomasz Korbak, Xudong Shen, Yuhui Zhang, Zhengping Zhou, Najoung Kim, Samuel R. Bowman, Ethan Perez
Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Read more5/14/2024

0
A Tale of Tails: Model Collapse as a Change of Scaling Laws
Elvis Dohmatob, Yunzhen Feng, Pu Yang, Francois Charton, Julia Kempe
As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
Read more6/3/2024