A Tale of Tails: Model Collapse as a Change of Scaling Laws
2402.07043
0
0

Abstract
As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
Create account to get full access
Overview
- This paper explores the concept of "model collapse" in machine learning, where a model's performance degrades as it is trained on more data.
- The authors propose a "double scaling law" that explains how model collapse can arise as a change in the scaling behavior of the model's outputs.
- They demonstrate this phenomenon using a regression task and provide insights into the underlying mechanisms driving model collapse.
Plain English Explanation
The paper examines a curious behavior that can happen when training machine learning models: as you feed the model more and more data, its performance can actually start to get worse. This is known as "model collapse."
The researchers behind this paper wanted to better understand what's causing model collapse. They developed a mathematical model that helps explain it as a shift in how the model's outputs scale with the amount of training data. Essentially, there's a point where the model starts to change the way it processes information, leading to this collapse in performance.
To illustrate this, the researchers looked at a simple regression task, where the model is trying to predict a numerical output. They showed how the model's behavior goes through this transition, starting off by making good predictions but then eventually breaking down as more data is added.
[This work builds on previous research on scaling laws in machine learning, like the papers on unraveling the mystery of scaling laws, dynamical models and neural scaling laws, and an exactly solvable model for the emergence of scaling laws.]
The key insight is that model collapse isn't just a random failure mode - it's a natural consequence of how these models process information as the dataset grows. Understanding this transition can help machine learning practitioners anticipate and potentially avoid these kinds of breakdowns in the future.
Technical Explanation
The paper proposes a "double scaling law" to explain the phenomenon of model collapse. This law describes how the model's outputs scale with the amount of training data in two distinct regimes:
-
Initial Scaling Regime: When the model is trained on relatively little data, its outputs scale in a consistent, predictable way. This is the typical scaling behavior we expect to see in machine learning models.
-
Collapse Regime: However, as the model is trained on more and more data, the scaling behavior suddenly changes. The outputs start to collapse, meaning their magnitude decreases rapidly, leading to a degradation in performance.
The authors demonstrate this double scaling law using a simple regression task. They show how the model's performance first improves as more data is added, but then eventually deteriorates due to this collapse in the scaling of the model's outputs.
[This work builds on previous research on exactly solvable models for the emergence of scaling laws in machine learning, as described in the paper "Exactly Solvable Model for the Emergence of Scaling Laws".]
The paper provides insights into the underlying mechanisms driving this model collapse. It suggests that the change in scaling behavior is tied to the model's ability to effectively leverage the increasingly complex patterns in the growing dataset. At some point, the model becomes overwhelmed and starts to lose its ability to generalize, leading to the observed performance degradation.
Critical Analysis
The paper provides a compelling theoretical framework for understanding model collapse, but there are a few caveats to consider:
-
Generalization to More Complex Models: The analysis is based on a relatively simple regression task, and it's unclear how well the double scaling law would apply to more sophisticated machine learning models, such as deep neural networks used for image recognition or natural language processing. [Further research is needed to see how well this theory generalizes to a wider range of model architectures and tasks, as discussed in the paper "How Bad is Training on Synthetic Data? Statistical Limits and Insights".]
-
Practical Implications: While the paper offers a mathematical explanation for model collapse, it doesn't provide clear guidance on how practitioners can avoid or mitigate this issue in real-world applications. More work is needed to translate these theoretical insights into actionable strategies for training robust machine learning models.
-
Limitations of the Regression Task: The regression task used in the experiments may not fully capture the complexity of real-world machine learning problems, which often involve high-dimensional data and more intricate patterns. It would be valuable to see the authors extend their analysis to a broader range of tasks and datasets.
Overall, this paper makes an important contribution to our understanding of model collapse, but there is still more work to be done to fully explore the implications and practical applications of this research.
Conclusion
This paper presents a novel "double scaling law" that helps explain the phenomenon of model collapse, where machine learning models can experience a sudden degradation in performance as they are trained on larger and larger datasets.
The authors demonstrate this behavior using a regression task and provide insights into the underlying mechanisms driving model collapse. They suggest that this collapse is a natural consequence of how the model's outputs scale with the amount of training data, transitioning from an initial, predictable scaling regime to a collapse regime where the outputs rapidly decrease in magnitude.
While this work offers a compelling theoretical framework, more research is needed to understand how well it generalizes to more complex machine learning models and real-world applications. Nevertheless, this paper represents an important step forward in our understanding of the challenges and limitations of scaling up machine learning systems, which will be crucial as these technologies become increasingly ubiquitous in our lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Neural Scaling Laws on Graphs
Jingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, Jiliang Tang
0
0
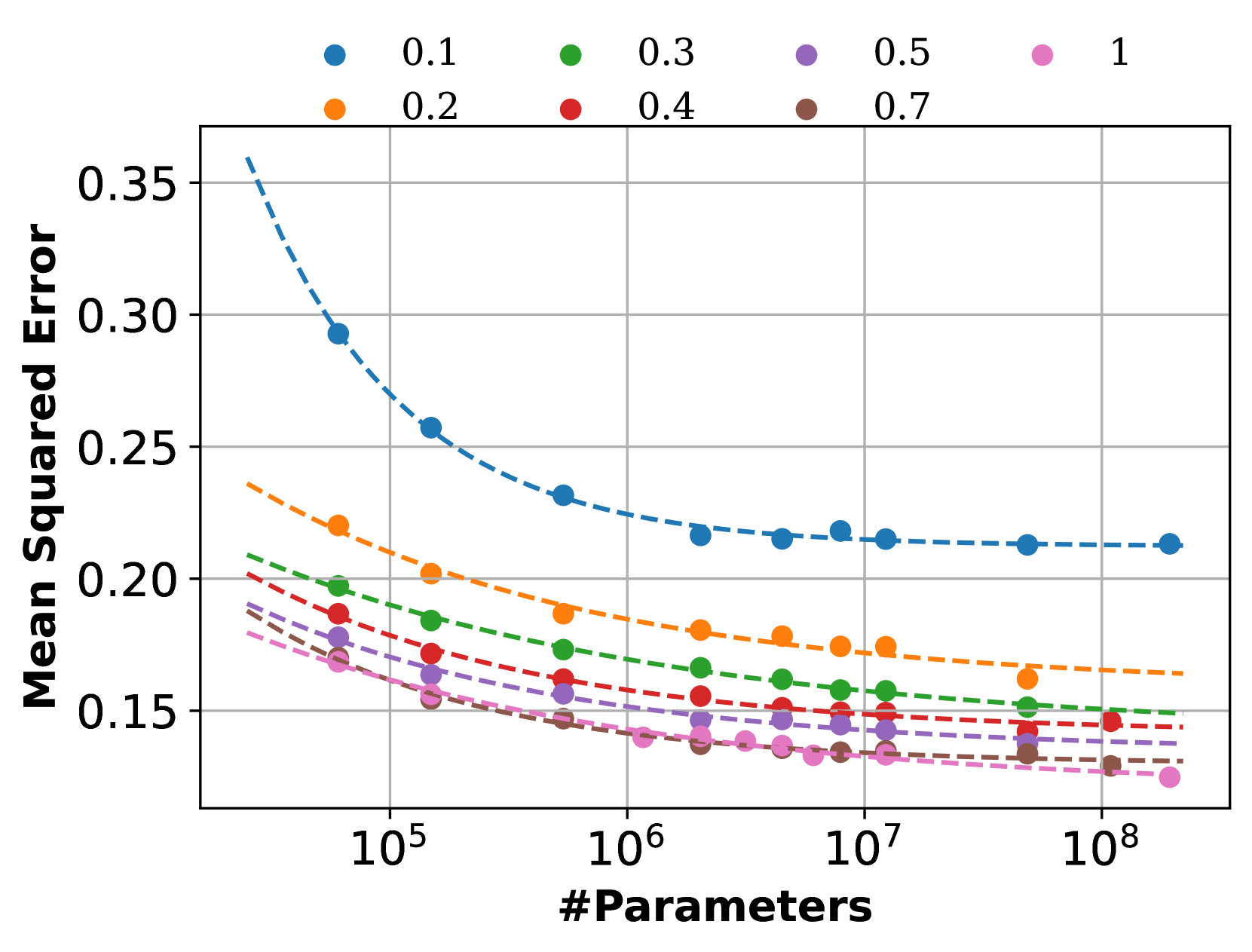
Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.
6/11/2024
Model Collapse Demystified: The Case of Regression
Elvis Dohmatob, Yunzhen Feng, Julia Kempe
0
0
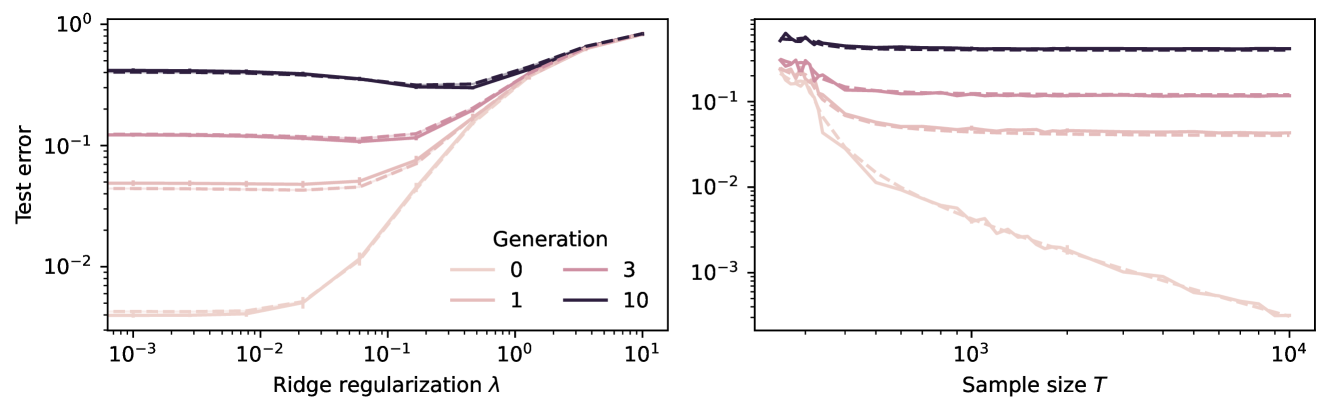
In the era of proliferation of large language and image generation models, the phenomenon of model collapse refers to the situation whereby as a model is trained recursively on data generated from previous generations of itself over time, its performance degrades until the model eventually becomes completely useless, i.e the model collapses. In this work, we study this phenomenon in the setting of high-dimensional regression and obtain analytic formulae which quantitatively outline this phenomenon in a broad range of regimes. In the special case of polynomial decaying spectral and source conditions, we obtain modified scaling laws which exhibit new crossover phenomena from fast to slow rates. We also propose a simple strategy based on adaptive regularization to mitigate model collapse. Our theoretical results are validated with experiments.
5/2/2024
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
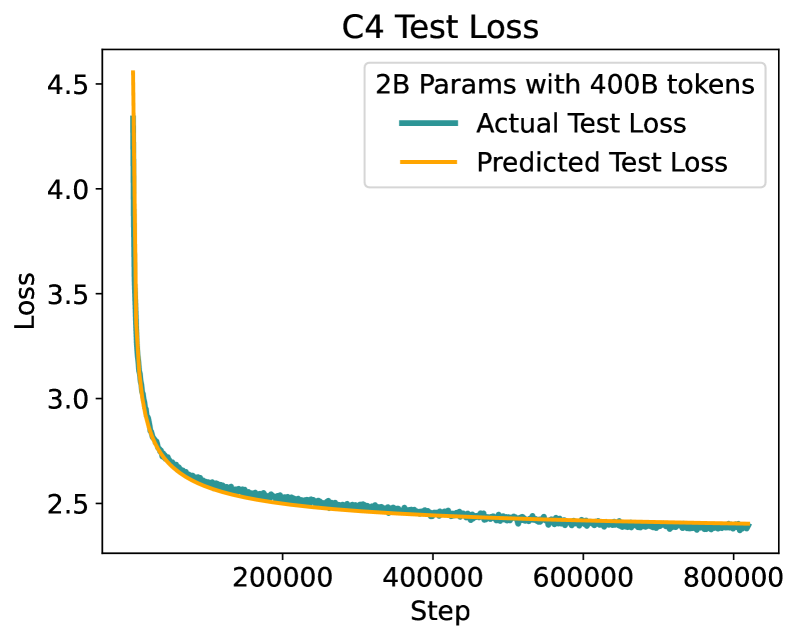
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
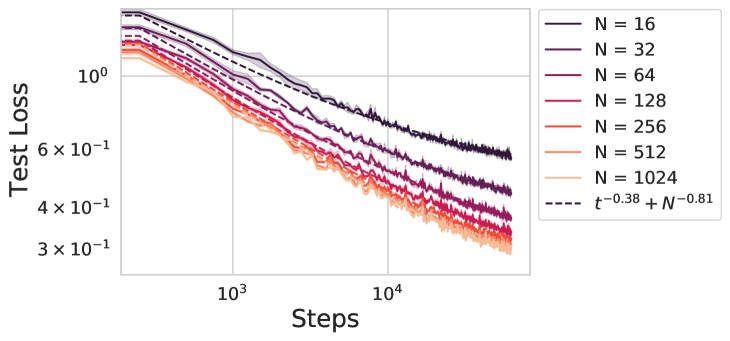
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
6/26/2024