Scaling Up Summarization: Leveraging Large Language Models for Long Text Extractive Summarization

0

Sign in to get full access
Overview
- This paper explores using large language models (LLMs) for extractive text summarization of long documents.
- The researchers developed a novel LLM-based summarization model that can handle long-form text more effectively than previous methods.
- The model outperforms state-of-the-art summarization techniques on several benchmark datasets, demonstrating the potential of LLMs for scaling up text summarization.
Plain English Explanation
The paper describes a new way to automatically summarize long documents using large language models (LLMs) - computer systems trained on massive amounts of text data to understand and generate human language.
Previous text summarization methods have struggled with long documents, often producing incoherent or irrelevant summaries. The researchers behind this paper created a novel LLM-based model that can better handle long-form text and generate more meaningful summaries.
The model works by first encoding the full document into a compact representation using the LLM. It then selects the most important sentences from the original text to include in the summary, based on factors like how representative the sentence is of the overall content. This "extractive" approach allows the model to create concise summaries while preserving the key information from the source material.
The researchers tested their model on several standard datasets used to benchmark summarization systems, and found that it outperformed other state-of-the-art methods. This suggests that large language models have great potential to help scale up text summarization to handle long and complex documents more effectively.
Technical Explanation
The paper introduces a novel LLM-based extractive summarization model called LamSum that can generate high-quality summaries for long-form text. The model first encodes the full document into a compact representation using an LLM-based encoder. It then uses a sentence scoring module to assign importance scores to each sentence based on factors like its relevance to the overall content.
The top-scoring sentences are then selected to form the final summary. This extractive approach allows the model to create concise yet informative summaries, in contrast to generative summarization which can sometimes produce incoherent or irrelevant output.
The researchers extensively evaluated LamSum on several benchmark datasets for long-form text summarization, including PubMed and ArXiv. They found that LamSum outperformed other state-of-the-art extractive and abstractive summarization models, demonstrating the advantages of leveraging powerful LLM capabilities for this task.
The paper also includes an analysis of the model's performance on documents of varying lengths, showing its ability to scale effectively. Overall, the results suggest that LLM-based approaches hold great promise for enhancing the state-of-the-art in long-form text summarization.
Critical Analysis
The paper makes a strong case for the effectiveness of large language models in tackling the challenge of long-form text summarization. The novel LamSum model demonstrated impressive results on benchmark datasets, outperforming other state-of-the-art approaches.
However, the authors acknowledge some limitations of their work, such as the potential for biases in the training data to affect the model's output. There is also room for further research to improve the model's ability to capture the semantic relationships and higher-level concepts within long documents.
Additionally, while the extractive approach used in LamSum can produce coherent summaries, it may not fully capture the nuanced meaning and context present in the original text. Exploring hybrid extractive-abstractive techniques could be a fruitful area for future work.
Overall, this paper provides a valuable contribution to the field of text summarization by showcasing the potential of large language models to handle lengthy and complex documents more effectively. The findings encourage further exploration of LLM-based methods and their application to real-world summarization challenges.
Conclusion
This paper demonstrates the power of large language models (LLMs) for enhancing long-form text summarization. The researchers developed a novel LLM-based extractive summarization model called LamSum that outperformed state-of-the-art methods on several benchmark datasets.
The results suggest that LLMs can be leveraged to scale up text summarization and handle longer and more complex documents more effectively than previous approaches. While the work has some limitations, it represents an important step forward in the field and encourages further research into applying these powerful language models to real-world summarization tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Up Summarization: Leveraging Large Language Models for Long Text Extractive Summarization
L'eo Hemamou, Mehdi Debiane
In an era where digital text is proliferating at an unprecedented rate, efficient summarization tools are becoming indispensable. While Large Language Models (LLMs) have been successfully applied in various NLP tasks, their role in extractive text summarization remains underexplored. This paper introduces EYEGLAXS (Easy Yet Efficient larGe LAnguage model for eXtractive Summarization), a framework that leverages LLMs, specifically LLAMA2-7B and ChatGLM2-6B, for extractive summarization of lengthy text documents. Instead of abstractive methods, which often suffer from issues like factual inaccuracies and hallucinations, EYEGLAXS focuses on extractive summarization to ensure factual and grammatical integrity. Utilizing state-of-the-art techniques such as Flash Attention and Parameter-Efficient Fine-Tuning (PEFT), EYEGLAXS addresses the computational and resource challenges typically associated with LLMs. The system sets new performance benchmarks on well-known datasets like PubMed and ArXiv. Furthermore, we extend our research through additional analyses that explore the adaptability of LLMs in handling different sequence lengths and their efficiency in training on smaller datasets. These contributions not only set a new standard in the field but also open up promising avenues for future research in extractive text summarization.
Read more8/29/2024
0
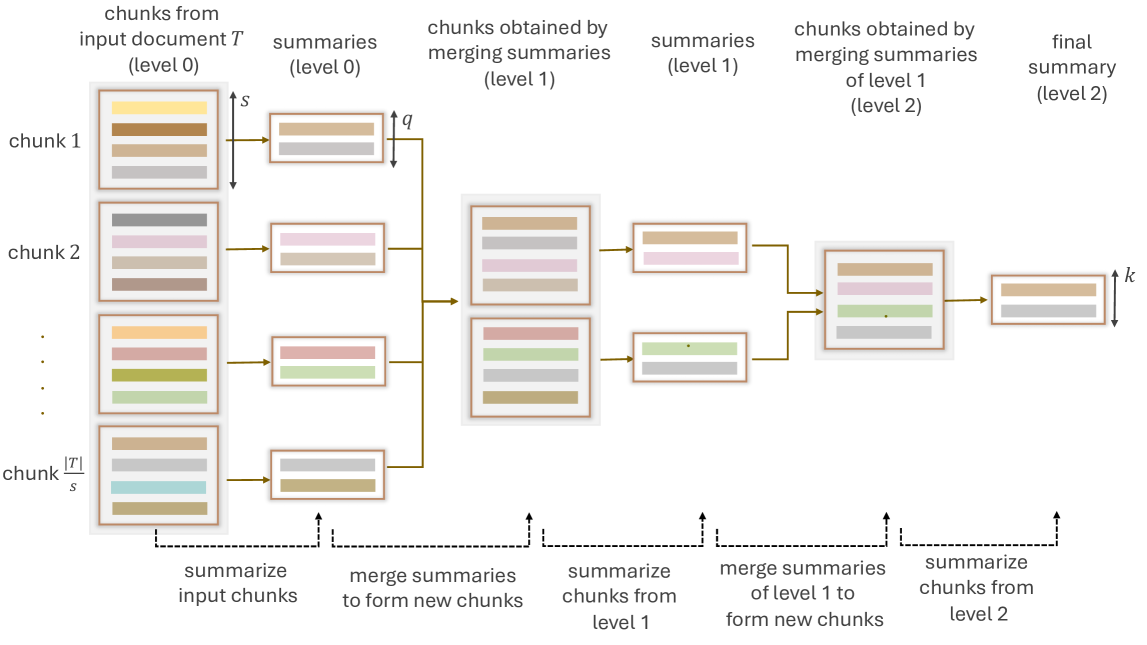
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024

0
MixSumm: Topic-based Data Augmentation using LLMs for Low-resource Extractive Text Summarization
Gaurav Sahu, Issam H. Laradji
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on abstractive text summarization or prompts a large language model (LLM) like GPT-3 directly to generate summaries. In this work, we propose MixSumm for low-resource extractive text summarization. Specifically, MixSumm prompts an open-source LLM, LLaMA-3-70b, to generate documents that mix information from multiple topics as opposed to generating documents without mixup, and then trains a summarization model on the generated dataset. We use ROUGE scores and L-Eval, a reference-free LLaMA-3-based evaluation method to measure the quality of generated summaries. We conduct extensive experiments on a challenging text summarization benchmark comprising the TweetSumm, WikiHow, and ArXiv/PubMed datasets and show that our LLM-based data augmentation framework outperforms recent prompt-based approaches for low-resource extractive summarization. Additionally, our results also demonstrate effective knowledge distillation from LLaMA-3-70b to a small BERT-based extractive summarizer.
Read more7/11/2024
0
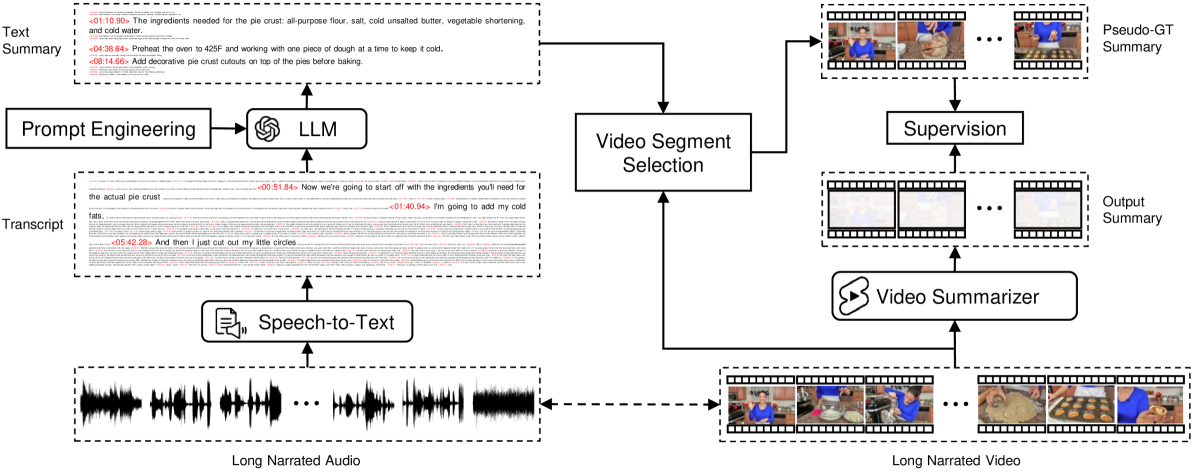
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Read more4/5/2024