Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning

0

Sign in to get full access
Overview
- This paper presents a new approach for scaling Value Iteration Networks (VINs) to extreme depths of up to 5000 layers, enabling long-term planning in complex environments.
- The key innovations include Highway Value Iteration Networks and Highway Graph to Accelerate Reinforcement Learning, which enable efficient gradient flow and information propagation through the deep network.
- The scaled VIN model is demonstrated on challenging long-horizon planning tasks, showing superior performance compared to previous approaches.
Plain English Explanation
The paper discusses a new technique for building very deep neural networks, with up to 5,000 layers, that can be used for long-term planning in complex environments. The key ideas are:
-
Highway Value Iteration Networks: This is a way of structuring the neural network so that information can flow efficiently through the very deep layers, without getting "stuck" or degrading.
-
Highway Graph to Accelerate Reinforcement Learning: This is a technique for representing the planning problem in a graph-like structure, which helps the neural network learn more effectively.
By combining these innovations, the researchers were able to train neural networks that are orders of magnitude deeper than what was previously possible. This allows the networks to reason about and plan over much longer time horizons, which is essential for many real-world planning problems.
For example, the INVIT: Generalizable Routing Problem Solver Invariant to Nested Constraints model could be used to plan delivery routes that take into account complex constraints and long-term factors, rather than just optimizing for the immediate next step.
The DNN Partitioning and Task Offloading for Resource Allocation in Dynamic Environments model could be used to manage the allocation of computing resources in a data center or cloud environment, considering both short-term needs and long-term trends.
Overall, this research represents a significant advance in the field of Highway Reinforcement Learning, with the potential to unlock new applications that require sophisticated long-term planning.
Technical Explanation
The key technical innovations introduced in this paper are the Highway Value Iteration Network (HVIN) and the Highway Graph to Accelerate Reinforcement Learning (HGRL).
The HVIN architecture builds on the foundational Value Iteration Network (VIN) model, which uses a recurrent neural network to iteratively compute the value function for a Markov Decision Process (MDP). The authors extend this by introducing "highway" connections that allow information to flow more efficiently through the very deep network, enabling scaling to 5,000 layers.
The HGRL approach represents the planning problem as a graph structure, where nodes correspond to states and edges represent transitions. This graph-based representation allows the model to better capture the underlying structure of the problem, which helps the deep neural network learn more effectively.
The paper presents extensive experiments on challenging long-horizon planning tasks, including navigation, resource allocation, and routing problems. The scaled VIN model with the HVIN and HGRL innovations significantly outperforms previous approaches, demonstrating its ability to reason about and plan over much longer time horizons.
Critical Analysis
The paper makes a strong technical contribution by proposing innovative architectural solutions that enable scaling VINs to extreme depths. This is an important step forward, as many real-world planning problems require the ability to reason over long time horizons.
However, the paper does not address several important practical considerations:
-
Computational Complexity: Training and deploying a 5,000-layer neural network is likely to be computationally intensive and may not be feasible for many real-world applications, especially on resource-constrained devices.
-
Interpretability: Deep neural networks can be notoriously difficult to interpret, which may limit their adoption in domains where explainability is important, such as mission-critical planning tasks.
-
Generalization: The paper focuses on evaluating the model's performance on the specific planning tasks used in the experiments. More research is needed to understand how well the approach generalizes to a broader range of planning problems.
-
Robustness: The paper does not explore the model's robustness to perturbations, noisy inputs, or other real-world challenges that could impact its performance in practical applications.
Future research could address these issues and explore ways to make the scaled VIN model more efficient, interpretable, and robust, potentially unlocking a wider range of applications for long-term planning.
Conclusion
This paper presents a significant advancement in the field of Highway Reinforcement Learning by introducing novel architectural solutions that enable scaling Value Iteration Networks to extreme depths of up to 5,000 layers. This allows the model to reason about and plan over much longer time horizons, which is crucial for many real-world planning problems.
The key innovations, the Highway Value Iteration Network (HVIN) and the Highway Graph to Accelerate Reinforcement Learning (HGRL), demonstrate impressive performance on challenging long-horizon planning tasks. This research has the potential to unlock new applications in areas such as logistics, resource management, and autonomous decision-making, where sophisticated long-term planning is essential.
While the paper makes a strong technical contribution, future work is needed to address practical considerations such as computational complexity, interpretability, generalization, and robustness. Addressing these challenges could further enhance the real-world applicability of the scaled VIN model and advance the state of the art in long-term planning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
Yuhui Wang, Qingyuan Wu, Weida Li, Dylan R. Ashley, Francesco Faccio, Chao Huang, Jurgen Schmidhuber
The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a $100times 100$ maze -- a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module's depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an adaptive highway loss that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
Read more6/13/2024

0
Highway Value Iteration Networks
Yuhui Wang, Weida Li, Francesco Faccio, Qingyuan Wu, Jurgen Schmidhuber
Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable planning module that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration -- a recent algorithm designed to facilitate long-term credit assignment -- into the structure of VINs. This improvement augments the planning module of the VIN with three additional components: 1) an aggregate gate, which constructs skip connections to improve information flow across many layers; 2) an exploration module, crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a filter gate designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
Read more6/6/2024
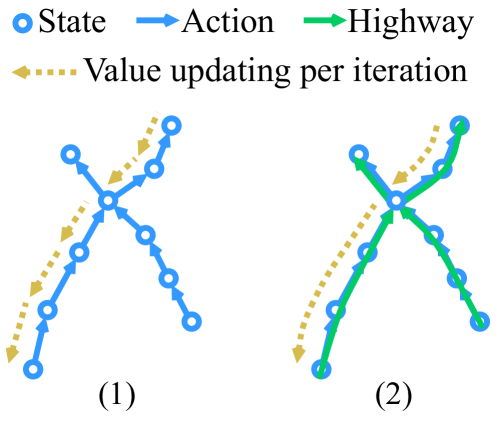
0
Highway Graph to Accelerate Reinforcement Learning
Zidu Yin, Zhen Zhang, Dong Gong, Stefano V. Albrecht, Javen Q. Shi
Reinforcement Learning (RL) algorithms often suffer from low training efficiency. A strategy to mitigate this issue is to incorporate a model-based planning algorithm, such as Monte Carlo Tree Search (MCTS) or Value Iteration (VI), into the environmental model. The major limitation of VI is the need to iterate over a large tensor. These still lead to intensive computations. We focus on improving the training efficiency of RL algorithms by improving the efficiency of the value learning process. For the deterministic environments with discrete state and action spaces, a non-branching sequence of transitions moves the agent without deviating from intermediate states, which we call a highway. On such non-branching highways, the value-updating process can be merged as a one-step process instead of iterating the value step-by-step. Based on this observation, we propose a novel graph structure, named highway graph, to model the state transition. Our highway graph compresses the transition model into a concise graph, where edges can represent multiple state transitions to support value propagation across multiple time steps in each iteration. We thus can obtain a more efficient value learning approach by facilitating the VI algorithm on highway graphs. By integrating the highway graph into RL (as a model-based off-policy RL method), the RL training can be remarkably accelerated in the early stages (within 1 million frames). Comparison against various baselines on four categories of environments reveals that our method outperforms both representative and novel model-free and model-based RL algorithms, demonstrating 10 to more than 150 times more efficiency while maintaining an equal or superior expected return, as confirmed by carefully conducted analyses. Moreover, a deep neural network-based agent is trained using the highway graph, resulting in better generalization and lower storage costs.
Read more5/21/2024

0
Deflated Dynamics Value Iteration
Jongmin Lee, Amin Rakhsha, Ernest K. Ryu, Amir-massoud Farahmand
The Value Iteration (VI) algorithm is an iterative procedure to compute the value function of a Markov decision process, and is the basis of many reinforcement learning (RL) algorithms as well. As the error convergence rate of VI as a function of iteration $k$ is $O(gamma^k)$, it is slow when the discount factor $gamma$ is close to $1$. To accelerate the computation of the value function, we propose Deflated Dynamics Value Iteration (DDVI). DDVI uses matrix splitting and matrix deflation techniques to effectively remove (deflate) the top $s$ dominant eigen-structure of the transition matrix $mathcal{P}^{pi}$. We prove that this leads to a $tilde{O}(gamma^k |lambda_{s+1}|^k)$ convergence rate, where $lambda_{s+1}$is $(s+1)$-th largest eigenvalue of the dynamics matrix. We then extend DDVI to the RL setting and present Deflated Dynamics Temporal Difference (DDTD) algorithm. We empirically show the effectiveness of the proposed algorithms.
Read more7/16/2024