Highway Value Iteration Networks

0

Sign in to get full access
Overview
- This paper introduces "Highway Value Iteration Networks" (HVINs), a novel deep reinforcement learning architecture that combines the strengths of value iteration networks and highway networks.
- HVINs aim to improve the performance and sample efficiency of reinforcement learning agents in complex, continuous environments, such as those found in autonomous driving and robotics applications.
- The key innovations of HVINs include the integration of value iteration updates within a neural network, the use of highway connections to facilitate efficient information flow, and the incorporation of domain-specific knowledge through value function initialization.
Plain English Explanation
HVINs are a new type of deep learning model designed to help AI systems learn how to make decisions and take actions in complex, real-world environments. Link to "Highway Value Iteration Networks" The researchers drew inspiration from two existing techniques: value iteration networks, which use a neural network to simulate the process of value iteration, and highway networks, which use special "highway" connections to help information flow more efficiently through the model.
The key idea behind HVINs is to combine these two approaches in a way that allows the AI system to learn more quickly and effectively, especially in challenging environments like those found in autonomous driving or robotics. Link to "Highway Reinforcement Learning" The researchers found that by integrating the value iteration process directly into the neural network, and using highway connections to help the information flow more smoothly, the AI system was able to learn complex tasks much faster than previous approaches.
One of the unique features of HVINs is that they allow the AI system to incorporate domain-specific knowledge, such as the laws of physics or the rules of the road, into the way it learns and makes decisions. Link to "Optimizing Vehicular Networks via Variational Quantum Circuits" This can help the system learn more efficiently and make better decisions, especially in complex, real-world environments where there are many variables to consider.
Overall, HVINs represent an important advance in the field of deep reinforcement learning, with the potential to enable AI systems that can navigate and make decisions in much more challenging and realistic environments than ever before. Link to "Novel Hybrid Time-Varying Graph Neural Network"
Technical Explanation
The key technical innovations of HVINs include:
-
Integration of Value Iteration: The researchers incorporated the value iteration process, a fundamental algorithm in reinforcement learning, directly into the neural network architecture. This allows the model to learn the value function and optimal policy simultaneously, improving sample efficiency and performance.
-
Highway Connections: HVINs utilize highway connections, which are specialized neural network layers that facilitate the efficient flow of information through the model. This helps the model learn complex tasks more quickly by allowing relevant information to be propagated more effectively.
-
Initialization with Domain Knowledge: The researchers proposed initializing the value function in HVINs with domain-specific knowledge, such as the laws of physics or the rules of the road. This can help the model learn more efficiently by guiding it towards promising regions of the state-action space. Link to "Hierarchical Reinforcement Learning Empowered Task Offloading"
The researchers evaluated HVINs on a range of continuous control tasks, including simulated driving and robot manipulation, and demonstrated significant improvements in sample efficiency and final performance compared to baseline reinforcement learning algorithms.
Critical Analysis
The paper provides a convincing technical explanation and empirical evaluation of the HVINs approach. However, some potential limitations and areas for further research are worth considering:
-
Generalization to More Complex Environments: While HVINs showed promising results in the evaluated tasks, it would be valuable to test their performance in even more complex, realistic environments, such as those with dynamic obstacles, partial observability, or noisy sensors.
-
Scalability to High-Dimensional State Spaces: The paper focused on relatively low-dimensional continuous control tasks. It's unclear how well HVINs would scale to high-dimensional state spaces, such as those encountered in real-world robotics or autonomous driving applications.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of HVINs may be opaque, making it challenging to understand how the model is making decisions. Improving the interpretability of HVINs could be an important direction for future research.
-
Sensitivity to Initialization and Hyperparameters: The paper mentioned that the performance of HVINs can be sensitive to the initialization of the value function and the choice of hyperparameters. Developing more robust initialization strategies and automated hyperparameter tuning methods could further improve the reliability of HVINs.
Overall, the HVINs approach represents a promising step forward in the field of deep reinforcement learning, with the potential to enable more capable and efficient AI systems for a wide range of real-world applications. However, as with any new technology, there are opportunities for further research and refinement to address the limitations and enhance the capabilities of this approach.
Conclusion
The Highway Value Iteration Networks (HVINs) proposed in this paper offer a novel and effective approach to deep reinforcement learning, combining the strengths of value iteration networks and highway networks. Link to "Highway Graph to Accelerate Reinforcement Learning" By integrating value iteration directly into the neural network architecture and utilizing highway connections to facilitate efficient information flow, HVINs demonstrate significant improvements in sample efficiency and final performance across a range of continuous control tasks.
The ability of HVINs to incorporate domain-specific knowledge through value function initialization is a particularly promising feature, as it can help AI systems learn more effectively in complex, real-world environments. Link to "Hierarchical Reinforcement Learning Empowered Task Offloading" As the field of deep reinforcement learning continues to advance, innovations like HVINs will play a crucial role in enabling AI systems that can navigate and make decisions in increasingly challenging and realistic scenarios, with far-reaching implications for autonomous driving, robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Highway Value Iteration Networks
Yuhui Wang, Weida Li, Francesco Faccio, Qingyuan Wu, Jurgen Schmidhuber
Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable planning module that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration -- a recent algorithm designed to facilitate long-term credit assignment -- into the structure of VINs. This improvement augments the planning module of the VIN with three additional components: 1) an aggregate gate, which constructs skip connections to improve information flow across many layers; 2) an exploration module, crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a filter gate designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
Read more6/6/2024

0
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
Yuhui Wang, Qingyuan Wu, Weida Li, Dylan R. Ashley, Francesco Faccio, Chao Huang, Jurgen Schmidhuber
The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a $100times 100$ maze -- a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module's depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an adaptive highway loss that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
Read more6/13/2024
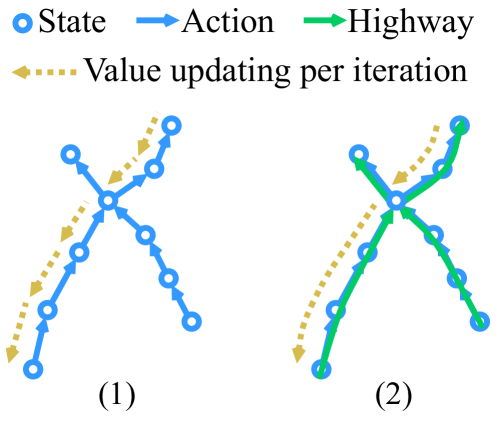
0
Highway Graph to Accelerate Reinforcement Learning
Zidu Yin, Zhen Zhang, Dong Gong, Stefano V. Albrecht, Javen Q. Shi
Reinforcement Learning (RL) algorithms often suffer from low training efficiency. A strategy to mitigate this issue is to incorporate a model-based planning algorithm, such as Monte Carlo Tree Search (MCTS) or Value Iteration (VI), into the environmental model. The major limitation of VI is the need to iterate over a large tensor. These still lead to intensive computations. We focus on improving the training efficiency of RL algorithms by improving the efficiency of the value learning process. For the deterministic environments with discrete state and action spaces, a non-branching sequence of transitions moves the agent without deviating from intermediate states, which we call a highway. On such non-branching highways, the value-updating process can be merged as a one-step process instead of iterating the value step-by-step. Based on this observation, we propose a novel graph structure, named highway graph, to model the state transition. Our highway graph compresses the transition model into a concise graph, where edges can represent multiple state transitions to support value propagation across multiple time steps in each iteration. We thus can obtain a more efficient value learning approach by facilitating the VI algorithm on highway graphs. By integrating the highway graph into RL (as a model-based off-policy RL method), the RL training can be remarkably accelerated in the early stages (within 1 million frames). Comparison against various baselines on four categories of environments reveals that our method outperforms both representative and novel model-free and model-based RL algorithms, demonstrating 10 to more than 150 times more efficiency while maintaining an equal or superior expected return, as confirmed by carefully conducted analyses. Moreover, a deep neural network-based agent is trained using the highway graph, resulting in better generalization and lower storage costs.
Read more5/21/2024
🏅
0
Highway Reinforcement Learning
Yuhui Wang, Miroslav Strupl, Francesco Faccio, Qingyuan Wu, Haozhe Liu, Micha{l} Grudzie'n, Xiaoyang Tan, Jurgen Schmidhuber
Learning from multi-step off-policy data collected by a set of policies is a core problem of reinforcement learning (RL). Approaches based on importance sampling (IS) often suffer from large variances due to products of IS ratios. Typical IS-free methods, such as $n$-step Q-learning, look ahead for $n$ time steps along the trajectory of actions (where $n$ is called the lookahead depth) and utilize off-policy data directly without any additional adjustment. They work well for proper choices of $n$. We show, however, that such IS-free methods underestimate the optimal value function (VF), especially for large $n$, restricting their capacity to efficiently utilize information from distant future time steps. To overcome this problem, we introduce a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal VF. At its core lies a simple but non-trivial emph{highway gate}, which controls the information flow from the distant future by comparing it to a threshold. The highway gate guarantees convergence to the optimal VF for arbitrary $n$ and arbitrary behavioral policies. It gives rise to a novel family of off-policy RL algorithms that safely learn even when $n$ is very large, facilitating rapid credit assignment from the far future to the past. On tasks with greatly delayed rewards, including video games where the reward is given only at the end of the game, our new methods outperform many existing multi-step off-policy algorithms.
Read more5/29/2024