Highway Reinforcement Learning
2405.18289
0
0
🏅
Abstract
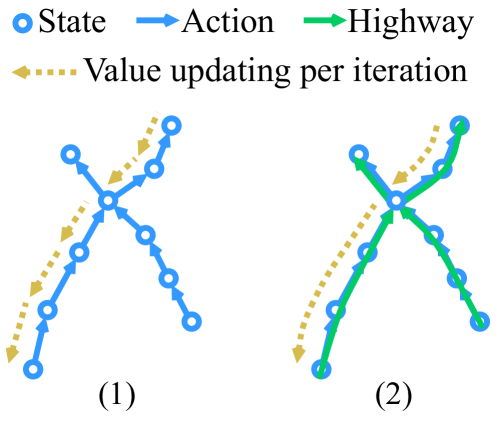
Learning from multi-step off-policy data collected by a set of policies is a core problem of reinforcement learning (RL). Approaches based on importance sampling (IS) often suffer from large variances due to products of IS ratios. Typical IS-free methods, such as $n$-step Q-learning, look ahead for $n$ time steps along the trajectory of actions (where $n$ is called the lookahead depth) and utilize off-policy data directly without any additional adjustment. They work well for proper choices of $n$. We show, however, that such IS-free methods underestimate the optimal value function (VF), especially for large $n$, restricting their capacity to efficiently utilize information from distant future time steps. To overcome this problem, we introduce a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal VF. At its core lies a simple but non-trivial emph{highway gate}, which controls the information flow from the distant future by comparing it to a threshold. The highway gate guarantees convergence to the optimal VF for arbitrary $n$ and arbitrary behavioral policies. It gives rise to a novel family of off-policy RL algorithms that safely learn even when $n$ is very large, facilitating rapid credit assignment from the far future to the past. On tasks with greatly delayed rewards, including video games where the reward is given only at the end of the game, our new methods outperform many existing multi-step off-policy algorithms.
Create account to get full access
Overview
- Reinforcement learning (RL) often relies on multi-step off-policy data collected by a set of policies
- Importance sampling (IS)-based approaches can suffer from high variance due to products of IS ratios
- N-step Q-learning is an IS-free method that looks ahead for n time steps, but it can underestimate the optimal value function, especially for large n
- The paper introduces a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal value function
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards. In many cases, the agent learns from data collected by a different set of policies, rather than its own actions. This is known as "off-policy" learning.
One common approach to off-policy learning is called "importance sampling" (IS). IS-based methods use mathematical adjustments to account for the difference between the data collection policies and the agent's policy. However, these adjustments can sometimes lead to high variability in the learning process, which can make it difficult to learn effectively.
An alternative to IS-based methods is called "n-step Q-learning." In this approach, the agent looks ahead n time steps in the data and uses that information directly, without any additional adjustments. This can work well for certain choices of n. However, the paper shows that n-step Q-learning tends to underestimate the optimal value function, especially when n is large.
To address this issue, the paper introduces a new, IS-free, multi-step off-policy method that avoids the underestimation problem and converges to the optimal value function. At the core of this method is a "highway gate" that controls the flow of information from the distant future, comparing it to a threshold. This highway gate ensures that the method can learn effectively even when n is very large, allowing the agent to quickly assign credit from distant rewards to past actions.
The new methods proposed in this paper can be particularly useful for tasks with greatly delayed rewards, such as video games where the reward is only given at the end of the game. In these scenarios, the paper's techniques can outperform many existing multi-step off-policy algorithms.
Technical Explanation
The paper introduces a novel, IS-free, multi-step off-policy reinforcement learning method that overcomes the underestimation issue of typical n-step Q-learning approaches.
The core of the method is a "highway gate" that controls the flow of information from the distant future. This gate compares the value of the distant future to a threshold and adjusts the credit assignment accordingly. This ensures that the method can effectively utilize information from the far future, even when the lookahead depth n is very large.
The highway gate guarantees convergence to the optimal value function for arbitrary n and arbitrary behavioral policies. This gives rise to a new family of off-policy RL algorithms that can safely learn even when n is large, enabling rapid credit assignment from the distant future to the past.
The authors evaluate their new methods on tasks with greatly delayed rewards, including video games where the reward is only given at the end of the game. They show that their techniques outperform many existing multi-step off-policy algorithms in these challenging scenarios.
Critical Analysis
The paper presents a novel and promising approach to addressing the underestimation issue in n-step Q-learning. The introduction of the "highway gate" mechanism is a clever solution that allows the method to effectively utilize information from the distant future, even when the lookahead depth n is large.
One potential limitation of the approach is that the choice of the threshold for the highway gate may require careful tuning or adaptation to different problem domains. The paper does not provide extensive guidance on how to set this threshold or how sensitive the method is to this parameter.
Additionally, while the paper demonstrates the benefits of the new method on tasks with delayed rewards, it would be valuable to see a more comprehensive evaluation across a broader range of RL benchmarks and use cases. This could help assess the generalizability and robustness of the approach.
Further research could also explore ways to automatically adapt the highway gate threshold or incorporate it into the overall optimization process, potentially improving the method's performance and ease of use.
Conclusion
The paper presents a novel, IS-free, multi-step off-policy reinforcement learning method that addresses the underestimation issue of typical n-step Q-learning approaches. The key innovation is the "highway gate" mechanism, which controls the flow of information from the distant future and ensures convergence to the optimal value function, even with large lookahead depths.
This new family of off-policy RL algorithms can learn effectively from data collected by a variety of policies, making them particularly useful for tasks with greatly delayed rewards, such as video games. The authors demonstrate the advantages of their approach on these challenging scenarios, opening up new possibilities for applying reinforcement learning to complex, real-world problems.
While the method shows promise, further research is needed to explore its adaptability, robustness, and broader applicability across a wider range of RL domains. By addressing the limitations of existing off-policy learning techniques, this work represents an important step forward in the field of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Highway Graph to Accelerate Reinforcement Learning
Zidu Yin, Zhen Zhang, Dong Gong, Stefano V. Albrecht, Javen Q. Shi
0
0
Reinforcement Learning (RL) algorithms often suffer from low training efficiency. A strategy to mitigate this issue is to incorporate a model-based planning algorithm, such as Monte Carlo Tree Search (MCTS) or Value Iteration (VI), into the environmental model. The major limitation of VI is the need to iterate over a large tensor. These still lead to intensive computations. We focus on improving the training efficiency of RL algorithms by improving the efficiency of the value learning process. For the deterministic environments with discrete state and action spaces, a non-branching sequence of transitions moves the agent without deviating from intermediate states, which we call a highway. On such non-branching highways, the value-updating process can be merged as a one-step process instead of iterating the value step-by-step. Based on this observation, we propose a novel graph structure, named highway graph, to model the state transition. Our highway graph compresses the transition model into a concise graph, where edges can represent multiple state transitions to support value propagation across multiple time steps in each iteration. We thus can obtain a more efficient value learning approach by facilitating the VI algorithm on highway graphs. By integrating the highway graph into RL (as a model-based off-policy RL method), the RL training can be remarkably accelerated in the early stages (within 1 million frames). Comparison against various baselines on four categories of environments reveals that our method outperforms both representative and novel model-free and model-based RL algorithms, demonstrating 10 to more than 150 times more efficiency while maintaining an equal or superior expected return, as confirmed by carefully conducted analyses. Moreover, a deep neural network-based agent is trained using the highway graph, resulting in better generalization and lower storage costs.
5/21/2024
🤷
Policy Gradient with Active Importance Sampling
Matteo Papini, Giorgio Manganini, Alberto Maria Metelli, Marcello Restelli
0
0
Importance sampling (IS) represents a fundamental technique for a large surge of off-policy reinforcement learning approaches. Policy gradient (PG) methods, in particular, significantly benefit from IS, enabling the effective reuse of previously collected samples, thus increasing sample efficiency. However, classically, IS is employed in RL as a passive tool for re-weighting historical samples. However, the statistical community employs IS as an active tool combined with the use of behavioral distributions that allow the reduction of the estimate variance even below the sample mean one. In this paper, we focus on this second setting by addressing the behavioral policy optimization (BPO) problem. We look for the best behavioral policy from which to collect samples to reduce the policy gradient variance as much as possible. We provide an iterative algorithm that alternates between the cross-entropy estimation of the minimum-variance behavioral policy and the actual policy optimization, leveraging on defensive IS. We theoretically analyze such an algorithm, showing that it enjoys a convergence rate of order $O(epsilon^{-4})$ to a stationary point, but depending on a more convenient variance term w.r.t. standard PG methods. We then provide a practical version that is numerically validated, showing the advantages in the policy gradient estimation variance and on the learning speed.
5/10/2024
🏅
Reinforcement Learning with Lookahead Information
Nadav Merlis
0
0
We study reinforcement learning (RL) problems in which agents observe the reward or transition realizations at their current state before deciding which action to take. Such observations are available in many applications, including transactions, navigation and more. When the environment is known, previous work shows that this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing approaches for interacting with unknown environments are not well-adapted to these observations. In this work, we close this gap and design provably-efficient learning algorithms able to incorporate lookahead information. To achieve this, we perform planning using the empirical distribution of the reward and transition observations, in contrast to vanilla approaches that only rely on estimated expectations. We prove that our algorithms achieve tight regret versus a baseline that also has access to lookahead information - linearly increasing the amount of collected reward compared to agents that cannot handle lookahead information.
6/5/2024

Highway Value Iteration Networks
Yuhui Wang, Weida Li, Francesco Faccio, Qingyuan Wu, Jurgen Schmidhuber
0
0
Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable planning module that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration -- a recent algorithm designed to facilitate long-term credit assignment -- into the structure of VINs. This improvement augments the planning module of the VIN with three additional components: 1) an aggregate gate, which constructs skip connections to improve information flow across many layers; 2) an exploration module, crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a filter gate designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
6/6/2024