UNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents

0

Sign in to get full access
Overview
- Introduces UNER, a novel approach for named entity recognition (NER) in visually-rich documents
- Proposes a unified prediction head that can handle different types of entities and visual features
- Shows improvements over state-of-the-art models on various datasets
Plain English Explanation
UNER is a new method for automatically identifying and classifying important information, like names, locations, and organizations, in documents that contain both text and visual elements. Many documents, like webpages or PDF files, have a mix of text and images, tables, or other visual components. Traditional NER models struggle with these types of "visually-rich" documents.
The key idea behind UNER is to use a unified prediction head that can handle different types of entities (e.g. people, places, companies) as well as incorporate visual information from the document. This allows the model to better understand the context and layout of the document, not just the text alone. The researchers show that UNER outperforms existing state-of-the-art NER models on several benchmark datasets, demonstrating the benefits of this unified approach.
Technical Explanation
The UNER model takes a multi-modal approach to NER, leveraging both textual and visual features from visually-rich documents. At the core of UNER is a unified prediction head that can handle different types of entities (e.g. person, location, organization) as well as visual elements like layout, formatting, and images.
The model first encodes the textual and visual inputs using a transformer-based backbone. It then feeds these contextual representations into the unified prediction head, which outputs entity labels for each token. This head is designed to be agnostic to the entity type, allowing the model to seamlessly handle a diverse set of entities.
The researchers evaluate UNER on several NER datasets, including FUNSD and XFUND, which contain visually-rich documents. They show that UNER outperforms state-of-the-art models like LayoutLM and VisualBERT, demonstrating the benefits of the unified prediction head approach.
Critical Analysis
The UNER paper presents a promising direction for NER in visually-rich documents, but there are a few areas that could be explored further:
-
Generalization to More Entity Types: While UNER is designed to be entity-agnostic, the experiments only consider a limited set of entities (person, location, organization). It would be valuable to test the model's performance on a wider range of entity types, including more domain-specific ones.
-
Interpretability and Explainability: The paper does not provide much insight into how the unified prediction head is able to effectively leverage both textual and visual features. Incorporating more interpretability could help users understand the model's decision-making process.
-
Scalability to Larger Documents: The datasets used in the evaluation are relatively small in size. Assessing UNER's performance on larger, more complex visually-rich documents would be an important next step.
Despite these potential avenues for improvement, the UNER paper represents an important advancement in the field of document understanding and sets the stage for further research on multi-modal approaches to named entity recognition.
Conclusion
The UNER paper introduces a novel approach for named entity recognition in visually-rich documents. By proposing a unified prediction head that can handle different entity types and visual features, the researchers demonstrate improved performance over state-of-the-art models on several benchmark datasets.
This work highlights the importance of considering both textual and visual information when working with complex, multi-modal documents. As the volume of visually-rich content continues to grow, techniques like UNER will become increasingly crucial for effectively extracting and organizing important information from these documents. The paper lays the groundwork for further advancements in document understanding and multi-modal natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents
Yi Tu, Chong Zhang, Ya Guo, Huan Chen, Jinyang Tang, Huijia Zhu, Qi Zhang
The recognition of named entities in visually-rich documents (VrD-NER) plays a critical role in various real-world scenarios and applications. However, the research in VrD-NER faces three major challenges: complex document layouts, incorrect reading orders, and unsuitable task formulations. To address these challenges, we propose a query-aware entity extraction head, namely UNER, to collaborate with existing multi-modal document transformers to develop more robust VrD-NER models. The UNER head considers the VrD-NER task as a combination of sequence labeling and reading order prediction, effectively addressing the issues of discontinuous entities in documents. Experimental evaluations on diverse datasets demonstrate the effectiveness of UNER in improving entity extraction performance. Moreover, the UNER head enables a supervised pre-training stage on various VrD-NER datasets to enhance the document transformer backbones and exhibits substantial knowledge transfer from the pre-training stage to the fine-tuning stage. By incorporating universal layout understanding, a pre-trained UNER-based model demonstrates significant advantages in few-shot and cross-linguistic scenarios and exhibits zero-shot entity extraction abilities.
Read more8/13/2024
👁️
0
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Stephen Mayhew, Terra Blevins, Shuheng Liu, Marek v{S}uppa, Hila Gonen, Joseph Marvin Imperial, Borje F. Karlsson, Peiqin Lin, Nikola Ljubev{s}i'c, LJ Miranda, Barbara Plank, Arij Riabi, Yuval Pinter
We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
Read more7/2/2024
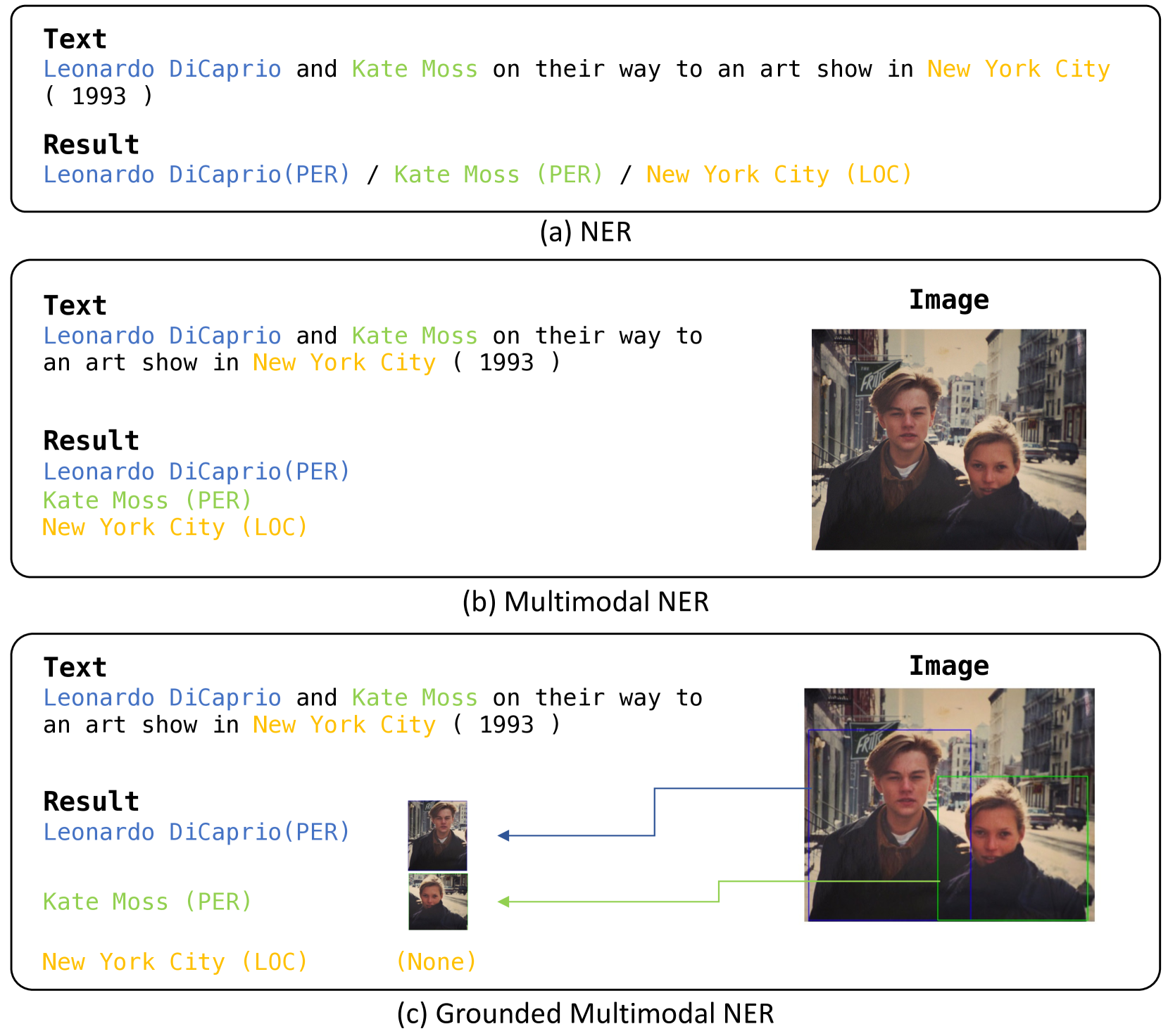
0
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Hyunjong Ok, Taeho Kil, Sukmin Seo, Jaeho Lee
Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
Read more4/3/2024
👁️
0
A Unified Label-Aware Contrastive Learning Framework for Few-Shot Named Entity Recognition
Haojie Zhang, Yimeng Zhuang
Few-shot Named Entity Recognition (NER) aims to extract named entities using only a limited number of labeled examples. Existing contrastive learning methods often suffer from insufficient distinguishability in context vector representation because they either solely rely on label semantics or completely disregard them. To tackle this issue, we propose a unified label-aware token-level contrastive learning framework. Our approach enriches the context by utilizing label semantics as suffix prompts. Additionally, it simultaneously optimizes context-context and context-label contrastive learning objectives to enhance generalized discriminative contextual representations.Extensive experiments on various traditional test domains (OntoNotes, CoNLL'03, WNUT'17, GUM, I2B2) and the large-scale few-shot NER dataset (FEWNERD) demonstrate the effectiveness of our approach. It outperforms prior state-of-the-art models by a significant margin, achieving an average absolute gain of 7% in micro F1 scores across most scenarios. Further analysis reveals that our model benefits from its powerful transfer capability and improved contextual representations.
Read more5/9/2024