SCDNet: Self-supervised Learning Feature-based Speaker Change Detection

0

Sign in to get full access
Overview
- This paper presents a novel self-supervised learning approach called SCDNet for speaker change detection in audio recordings.
- The key idea is to leverage self-supervised feature representations to identify speaker transitions without needing labeled training data.
- The approach builds on recent advancements in self-supervised multi-view contrastive learning and self-supervised speaker verification.
Plain English Explanation
The paper describes a new way to automatically detect when speakers change in an audio recording, without needing a lot of labeled training data. The core idea is to use "self-supervised learning" to extract useful features from the audio that can identify speaker transitions.
Self-supervised learning is a powerful technique where the model learns useful representations of the data by solving a related "pretext" task, rather than being trained directly on the main task. In this case, the pretext task is to learn audio features that can be used to distinguish between different speakers.
Once the model has learned these speaker-discriminative features, it can then be applied to the main task of detecting when the speaker changes. This avoids the need for manually labeling large amounts of training data, which is often a bottleneck for supervised approaches.
The authors show that their SCDNet model achieves strong performance on speaker change detection benchmarks, outperforming previous self-supervised and supervised methods. This demonstrates the potential of self-supervised learning to enable robust speaker change detection without extensive data annotation.
Technical Explanation
The key technical contributions of the paper are:
-
Self-Supervised Feature Learning: The authors propose a self-supervised contrastive learning framework to learn discriminative audio features for speaker change detection. This builds on recent work in self-supervised multi-view contrastive learning and self-supervised speaker verification.
-
SCDNet Architecture: The SCDNet model consists of a feature encoder network that learns the self-supervised audio representations, and a speaker change detection head that uses these features to predict speaker transitions. The architecture allows end-to-end training of the entire system.
-
Experiments: The authors evaluate SCDNet on standard speaker change detection benchmarks, including the AMI and ICSI meeting corpora. They show that SCDNet outperforms previous self-supervised and supervised baselines, demonstrating the effectiveness of the self-supervised feature learning approach.
The technical details of the self-supervised contrastive learning objective and network architecture are described in the paper. The authors also discuss how SCDNet can be further extended to incorporate additional contextual information, such as semantic distance metric learning and speaker-adaptive modeling.
Critical Analysis
The paper presents a strong technical contribution in the area of self-supervised learning for speaker change detection. The authors demonstrate the effectiveness of their approach on standard benchmarks, outperforming previous methods.
One potential limitation is that the experiments are conducted on meeting recordings, which may not fully capture the diversity of real-world audio data. Further evaluation on a broader range of scenarios, such as conversational speech, would help validate the generalization of the approach.
Additionally, while the self-supervised feature learning is a core innovation, the authors could explore ways to further improve the speaker change detection performance, such as incorporating additional contextual cues or developing more sophisticated modeling techniques.
Overall, the paper makes a compelling case for the use of self-supervised learning to enable robust speaker change detection without extensive data annotation, and opens up interesting directions for future research in this area.
Conclusion
This paper presents a novel self-supervised learning approach called SCDNet for speaker change detection in audio recordings. By leveraging self-supervised feature representations, the model can effectively identify speaker transitions without needing labeled training data.
The key technical contributions include the self-supervised contrastive learning framework for audio feature extraction, the SCDNet architecture that integrates the feature encoder and speaker change detection components, and the strong empirical results on standard benchmarks.
The work demonstrates the potential of self-supervised learning to enable robust speaker change detection in real-world scenarios, and suggests promising avenues for further research in this area, such as exploring more advanced modeling techniques and expanding the evaluation to a broader range of audio data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SCDNet: Self-supervised Learning Feature-based Speaker Change Detection
Yue Li, Xinsheng Wang, Li Zhang, Lei Xie
Speaker Change Detection (SCD) is to identify boundaries among speakers in a conversation. Motivated by the success of fine-tuning wav2vec 2.0 models for the SCD task, a further investigation of self-supervised learning (SSL) features for SCD is conducted in this work. Specifically, an SCD model, named SCDNet, is proposed. With this model, various state-of-the-art SSL models, including Hubert, wav2vec 2.0, and WavLm are investigated. To discern the most potent layer of SSL models for SCD, a learnable weighting method is employed to analyze the effectiveness of intermediate representations. Additionally, a fine-tuning-based approach is also implemented to further compare the characteristics of SSL models in the SCD task. Furthermore, a contrastive learning method is proposed to mitigate the overfitting tendencies in the training of both the fine-tuning-based method and SCDNet. Experiments showcase the superiority of WavLm in the SCD task and also demonstrate the good design of SCDNet.
Read more6/13/2024

0
SSLChange: A Self-supervised Change Detection Framework Based on Domain Adaptation
Yitao Zhao, Turgay Celik, Nanqing Liu, Feng Gao, Heng-Chao Li
In conventional remote sensing change detection (RS CD) procedures, extensive manual labeling for bi-temporal images is first required to maintain the performance of subsequent fully supervised training. However, pixel-level labeling for CD tasks is very complex and time-consuming. In this paper, we explore a novel self-supervised contrastive framework applicable to the RS CD task, which promotes the model to accurately capture spatial, structural, and semantic information through domain adapter and hierarchical contrastive head. The proposed SSLChange framework accomplishes self-learning only by taking a single-temporal sample and can be flexibly transferred to main-stream CD baselines. With self-supervised contrastive learning, feature representation pre-training can be performed directly based on the original data even without labeling. After a certain amount of labels are subsequently obtained, the pre-trained features will be aligned with the labels for fully supervised fine-tuning. Without introducing any additional data or labels, the performance of downstream baselines will experience a significant enhancement. Experimental results on 2 entire datasets and 6 diluted datasets show that our proposed SSLChange improves the performance and stability of CD baseline in data-limited situations. The code of SSLChange will be released at url{https://github.com/MarsZhaoYT/SSLChange}
Read more5/29/2024
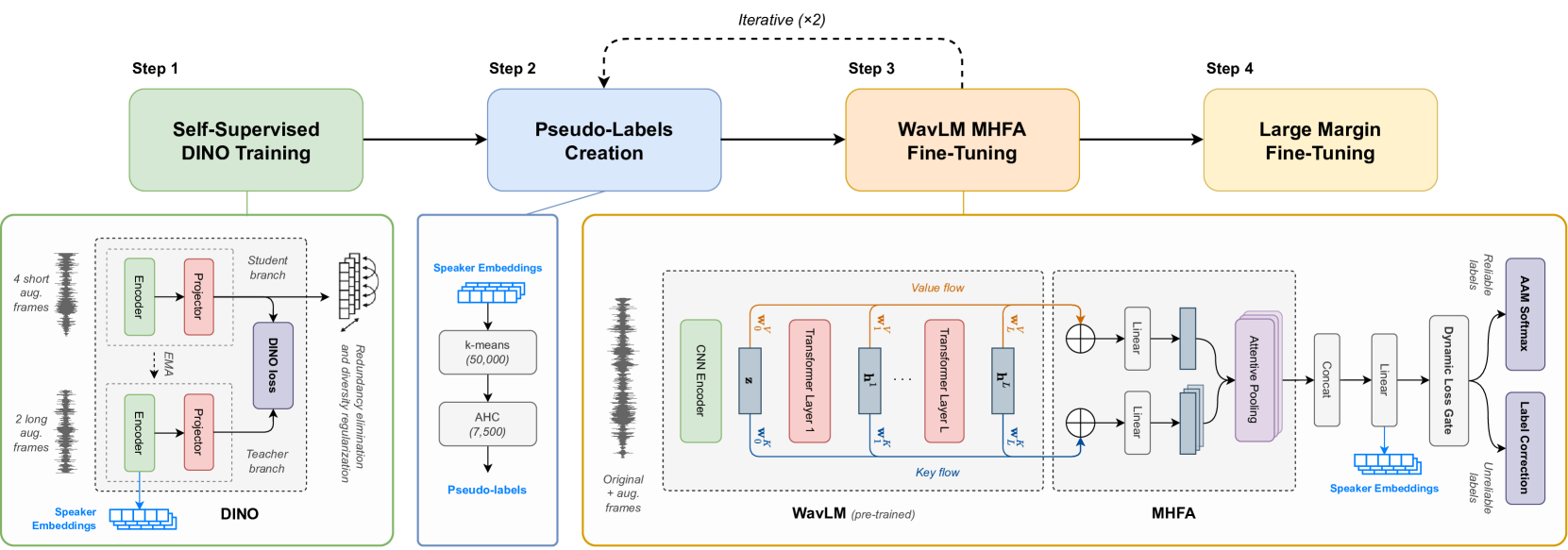
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more9/17/2024

0
New!Self-Supervised Syllable Discovery Based on Speaker-Disentangled HuBERT
Ryota Komatsu, Takahiro Shinozaki
Self-supervised speech representation learning has become essential for extracting meaningful features from untranscribed audio. Recent advances highlight the potential of deriving discrete symbols from the features correlated with linguistic units, which enables text-less training across diverse tasks. In particular, sentence-level Self-Distillation of the pretrained HuBERT (SD-HuBERT) induces syllabic structures within latent speech frame representations extracted from an intermediate Transformer layer. In SD-HuBERT, sentence-level representation is accumulated from speech frame features through self-attention layers using a special CLS token. However, we observe that the information aggregated in the CLS token correlates more with speaker identity than with linguistic content. To address this, we propose a speech-only self-supervised fine-tuning approach that separates syllabic units from speaker information. Our method introduces speaker perturbation as data augmentation and adopts a frame-level training objective to prevent the CLS token from aggregating paralinguistic information. Experimental results show that our approach surpasses the current state-of-the-art method in most syllable segmentation and syllabic unit quality metrics on Librispeech, underscoring its effectiveness in promoting syllabic organization within speech-only models.
Read more9/17/2024