Scholarly Question Answering using Large Language Models in the NFDI4DataScience Gateway
2406.07257
0
0

Abstract
This paper introduces a scholarly Question Answering (QA) system on top of the NFDI4DataScience Gateway, employing a Retrieval Augmented Generation-based (RAG) approach. The NFDI4DS Gateway, as a foundational framework, offers a unified and intuitive interface for querying various scientific databases using federated search. The RAG-based scholarly QA, powered by a Large Language Model (LLM), facilitates dynamic interaction with search results, enhancing filtering capabilities and fostering a conversational engagement with the Gateway search. The effectiveness of both the Gateway and the scholarly QA system is demonstrated through experimental analysis.
Create account to get full access
Overview
- This paper presents a framework for scholarly question answering using large language models in the NFDI4DataScience Gateway, a platform for federated search and retrieval of scientific literature.
- The framework combines retrieval-augmented generation and iterative fine-tuning techniques to provide high-quality answers to questions about scientific topics.
- It builds on previous work on scientific question answering and tool-calling for medication consultations.
- The framework also explores the application of dynamic document relevance to improve the quality of retrieved information.
Plain English Explanation
This paper describes a new way to help people find answers to questions about scientific topics. It uses large language models, which are powerful AI systems that can understand and generate human-like text. The researchers combined several different techniques to create a framework that can provide high-quality answers to questions.
The key idea is to use a combination of information retrieval and text generation. First, the system searches through a large database of scientific literature to find the most relevant documents. Then, it uses the information in those documents to generate a well-written answer to the original question. This approach helps ensure that the answers are accurate and tailored to the specific question being asked.
The framework was developed as part of the NFDI4DataScience Gateway, a platform that allows researchers to search and access scientific information from different sources. By integrating this question-answering system, the gateway can provide users with more helpful and informative responses to their queries.
The researchers built on previous work in areas like scientific question answering and medical consultation tools. They also explored how to make the system better at determining which documents are most relevant to the question at hand. This helps the system provide more accurate and useful information.
Technical Explanation
The paper presents a framework for scholarly question answering that combines retrieval-augmented generation and iterative fine-tuning techniques. The goal is to provide high-quality answers to questions about scientific topics within the NFDI4DataScience Gateway, a platform for federated search and retrieval of academic literature.
The framework first uses a retrieval model to identify the most relevant documents from the gateway's database in response to a user's query. It then employs a generation model to synthesize a coherent, informative answer based on the retrieved information. This two-step process allows the system to leverage the strengths of both retrieval and generation approaches.
The researchers further enhance the framework by applying dynamic document relevance techniques, which assess the relevance of documents to the specific question at hand rather than using a static relevance score. This helps the system provide more targeted and useful information.
The framework builds on previous work in scientific question answering and tool-calling for medication consultations, adapting and extending these approaches to the scholarly domain.
Critical Analysis
The paper presents a well-designed framework that leverages state-of-the-art techniques in information retrieval and text generation to address the challenge of providing high-quality answers to questions about scientific topics. The integration of dynamic document relevance is a particularly noteworthy contribution, as it helps the system better understand the context and intent behind the user's query.
However, the paper does not provide a detailed evaluation of the framework's performance, which would be necessary to fully assess its effectiveness. Additionally, the authors acknowledge that the framework's performance may be sensitive to the specific language model and retrieval system used, and further research is needed to understand the optimal configuration.
Another potential limitation is the reliance on the NFDI4DataScience Gateway's database of scientific literature. While this provides a comprehensive source of information, the system's performance may be constrained by the coverage and quality of the available data. Exploring ways to expand the data sources or incorporate external knowledge sources could be a fruitful area for future research.
Overall, the paper presents a promising approach to scholarly question answering that could have significant implications for researchers, students, and anyone seeking to deepen their understanding of scientific topics. Further development and evaluation of the framework will be important to fully realize its potential.
Conclusion
The paper proposes a framework for scholarly question answering that combines retrieval-augmented generation and iterative fine-tuning techniques within the NFDI4DataScience Gateway. By leveraging large language models and dynamic document relevance, the framework aims to provide high-quality answers to questions about scientific topics.
This work builds on previous research in areas like scientific question answering and medical consultation tools, demonstrating the potential for these techniques to be adapted and applied to the scholarly domain. The integration of the framework into the NFDI4DataScience Gateway also highlights the importance of developing innovative solutions that can enhance the discoverability and accessibility of scientific information.
While further evaluation and refinement may be needed, the presented framework represents a significant step forward in addressing the challenge of providing accurate and informative answers to questions about complex scientific subjects. As large language models and other AI technologies continue to advance, the potential for such systems to support and empower scholarly research and education is likely to grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024

Enhancing Q&A with Domain-Specific Fine-Tuning and Iterative Reasoning: A Comparative Study
Zooey Nguyen, Anthony Annunziata, Vinh Luong, Sang Dinh, Quynh Le, Anh Hai Ha, Chanh Le, Hong An Phan, Shruti Raghavan, Christopher Nguyen
0
0
This paper investigates the impact of domain-specific model fine-tuning and of reasoning mechanisms on the performance of question-answering (Q&A) systems powered by large language models (LLMs) and Retrieval-Augmented Generation (RAG). Using the FinanceBench SEC financial filings dataset, we observe that, for RAG, combining a fine-tuned embedding model with a fine-tuned LLM achieves better accuracy than generic models, with relatively greater gains attributable to fine-tuned embedding models. Additionally, employing reasoning iterations on top of RAG delivers an even bigger jump in performance, enabling the Q&A systems to get closer to human-expert quality. We discuss the implications of such findings, propose a structured technical design space capturing major technical components of Q&A AI, and provide recommendations for making high-impact technical choices for such components. We plan to follow up on this work with actionable guides for AI teams and further investigations into the impact of domain-specific augmentation in RAG and into agentic AI capabilities such as advanced planning and reasoning.
4/23/2024
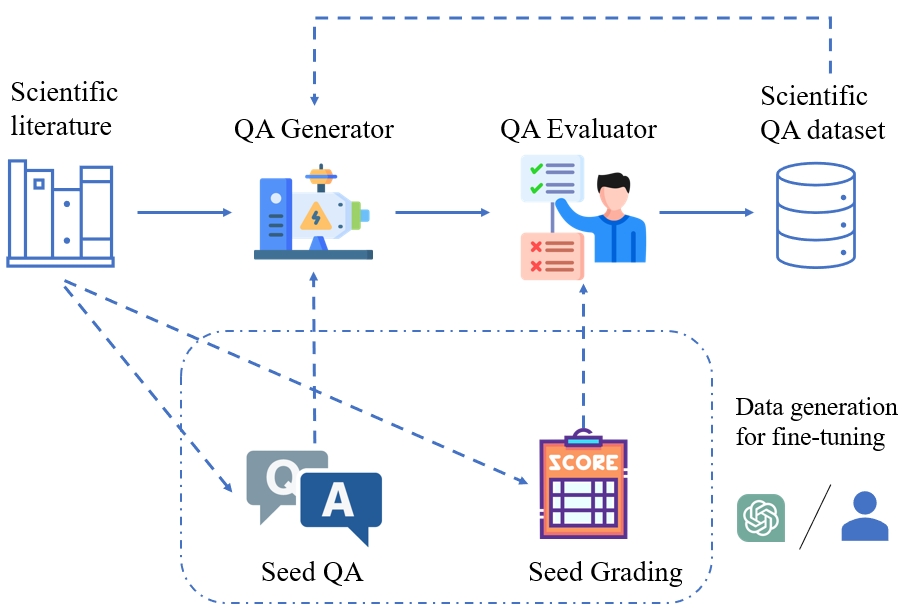
SciQAG: A Framework for Auto-Generated Scientific Question Answering Dataset with Fine-grained Evaluation
Yuwei Wan, Aswathy Ajith, Yixuan Liu, Ke Lu, Clara Grazian, Bram Hoex, Wenjie Zhang, Chunyu Kit, Tong Xie, Ian Foster
0
0
The use of question-answer (QA) pairs for training and evaluating large language models (LLMs) has attracted considerable attention. Yet few available QA datasets are based on knowledge from the scientific literature. Here we bridge this gap by presenting Automatic Generation of Scientific Question Answers (SciQAG), a framework for automatic generation and evaluation of scientific QA pairs sourced from published scientific literature. We fine-tune an open-source LLM to generate num{960000} scientific QA pairs from full-text scientific papers and propose a five-dimensional metric to evaluate the quality of the generated QA pairs. We show via LLM-based evaluation that the generated QA pairs consistently achieve an average score of 2.5 out of 3 across five dimensions, indicating that our framework can distill key knowledge from papers into high-quality QA pairs at scale. We make the dataset, models, and evaluation codes publicly available.
5/17/2024
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
0
0
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
4/30/2024