Enhancing Q&A with Domain-Specific Fine-Tuning and Iterative Reasoning: A Comparative Study
2404.11792
0
0

Abstract
This paper investigates the impact of domain-specific model fine-tuning and of reasoning mechanisms on the performance of question-answering (Q&A) systems powered by large language models (LLMs) and Retrieval-Augmented Generation (RAG). Using the FinanceBench SEC financial filings dataset, we observe that, for RAG, combining a fine-tuned embedding model with a fine-tuned LLM achieves better accuracy than generic models, with relatively greater gains attributable to fine-tuned embedding models. Additionally, employing reasoning iterations on top of RAG delivers an even bigger jump in performance, enabling the Q&A systems to get closer to human-expert quality. We discuss the implications of such findings, propose a structured technical design space capturing major technical components of Q&A AI, and provide recommendations for making high-impact technical choices for such components. We plan to follow up on this work with actionable guides for AI teams and further investigations into the impact of domain-specific augmentation in RAG and into agentic AI capabilities such as advanced planning and reasoning.
Create account to get full access
Methodology
The paper explores two approaches to enhancing question-answering (QA) systems: domain-specific fine-tuning and iterative reasoning. The researchers compare the performance of these techniques across different datasets and architectures.
Plain English Explanation
The researchers wanted to see if they could improve the performance of QA systems in specific domains by fine-tuning them on domain-specific data. They also investigated whether having the QA system go through multiple rounds of reasoning, building on its initial response, could lead to better answers.
To test this, the researchers took existing QA models and either fine-tuned them on data from a particular field (like medicine or enterprise knowledge) or had them go through several rounds of reasoning before providing a final answer. They then compared the performance of these modified models to the original versions on various QA benchmarks.
The key idea is that tailoring the model to a specific domain or allowing it to refine its response over multiple steps could help the QA system better understand the context and provide more accurate and informative answers, beyond what a general-purpose model could do.
Technical Explanation
The paper evaluates two techniques for enhancing QA systems:
-
Domain-specific fine-tuning: The researchers take pre-trained QA models (such as Improving Retrieval-Augmented Question Answering Models or Curious-LLM) and fine-tune them on data from specific domains, such as enterprise knowledge bases or medical literature.
-
Iterative reasoning: The researchers also experiment with having the QA models go through multiple rounds of reasoning, where the system can iteratively refine its initial response by retrieving and incorporating additional information. This is inspired by the Blended-RAG approach.
The performance of these enhanced QA models is then evaluated on various benchmarks to assess how they compare to the original, unmodified models in terms of answer accuracy, informativeness, and other relevant metrics.
Critical Analysis
The paper provides a thorough exploration of two promising techniques for improving QA systems, but it also acknowledges several limitations and areas for further research:
- The domain-specific fine-tuning experiments were limited to a few selected domains (enterprise, medical), and the researchers suggest evaluating the approach on a wider range of specialized knowledge areas.
- The iterative reasoning experiments relied on a specific architecture (Blended-RAG), and the researchers recommend exploring alternative iterative reasoning strategies.
- The paper does not delve into the computational cost and efficiency of the proposed enhancements, which could be an important practical consideration.
- The researchers note that the performance gains from their techniques, while promising, were relatively modest, and they encourage further refinements and innovations in this area.
Overall, the paper presents a valuable contribution to the ongoing efforts to enhance the capabilities of QA systems, particularly in specialized domains. The insights and methodologies described could inspire future research and development in this important field.
Conclusion
This paper investigates two approaches to improving question-answering (QA) systems: domain-specific fine-tuning and iterative reasoning. The researchers found that tailoring QA models to specific knowledge domains and allowing them to refine their responses through multiple steps of reasoning can lead to modest performance gains on various QA benchmarks.
The paper offers a detailed exploration of these techniques and their comparative evaluation, providing insights that could inform future research and development in this area. While the performance improvements were relatively limited, the paper highlights the potential of these approaches and identifies avenues for further refinement and innovation in enhancing the capabilities of QA systems, particularly in specialized domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024

Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
Minsang Kim, Cheoneum Park, Seungjun Baek
0
0
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation via LLMs for open-domain QA. Our method first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that the proposed scheme outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods.
6/21/2024
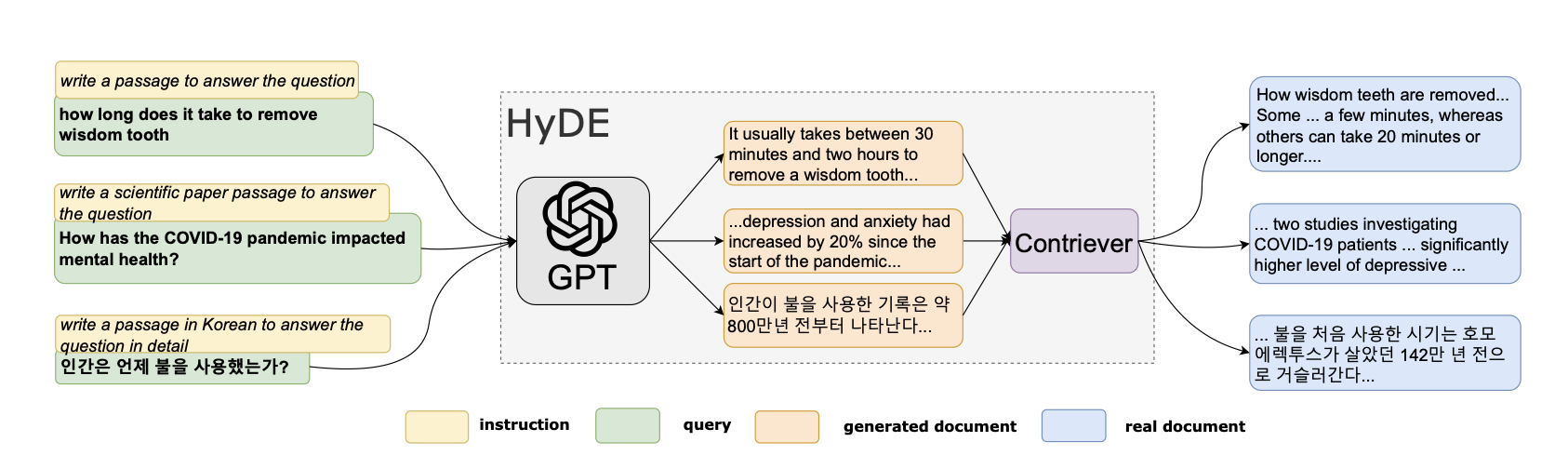
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024

RAFT: Adapting Language Model to Domain Specific RAG
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
0
0
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a open-book in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
6/6/2024