Schrodinger Bridge for Generative Speech Enhancement

0
🗣️
Sign in to get full access
Overview
- Introduces a new generative model called the Schrödinger Bridge for enhancing speech quality.
- Demonstrates the model's ability to generate high-quality speech samples from noisy inputs.
- Explores the potential of the Schrödinger Bridge framework for various speech enhancement tasks.
Plain English Explanation
The provided paper presents a novel approach to improving the quality of speech recordings. [A plain English explanation of the core ideas and their significance]
The key innovation is the use of a [link to "Schrödinger Bridge"] framework, which allows the model to generate high-quality speech samples from noisy or degraded inputs. This is achieved by [link to "generative model"] that learns to transform the low-quality input into a high-quality output, akin to a "[link to "speech enhancement"]" process.
The authors demonstrate the effectiveness of their [link to "Schrödinger Bridge for Generative Speech Enhancement"] model through experiments, showcasing its ability to enhance speech quality and outperform existing techniques. This research has [link to "potential implications"] for a wide range of applications, such as [examples of applications], where enhancing speech quality is crucial.
Technical Explanation
The paper introduces a [link to "Schrödinger Bridge"] model for [link to "generative speech enhancement"]. The Schrödinger Bridge is a [description of the framework], which the authors leverage to learn a transformation from noisy speech inputs to high-quality speech outputs.
The model architecture [link to "model architecture"] consists of [key elements of the architecture]. The training process [link to "training process"] involves [description of the training process], which allows the model to [link to "speech enhancement"] effectively.
The authors conduct [link to "experiments"] to evaluate the performance of their Schrödinger Bridge model on [description of the experiments]. The results demonstrate that the proposed approach [link to "key findings"] and outperforms [comparison to existing methods].
Critical Analysis
The paper provides a promising [link to "Schrödinger Bridge"] approach for [link to "generative speech enhancement"], but it also acknowledges several [link to "caveats and limitations"]. For example, [description of caveats and limitations].
Additionally, the authors note that [link to "areas for further research"], such as [examples of areas for further research], could further improve the model's performance and applicability.
While the results are compelling, it would be valuable to [potential issues or concerns] to gain a more comprehensive understanding of the model's strengths and weaknesses.
Conclusion
The [link to "Schrödinger Bridge for Generative Speech Enhancement"] proposed in this paper represents a significant [link to "potential implications"] for various speech-related applications. [Summarize the main takeaways and their significance]. This research opens up new avenues for further exploration and [link to "areas for further research"] in the field of [link to "speech enhancement"] and [link to "generative modeling"].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Schrodinger Bridge for Generative Speech Enhancement
Ante Juki'c, Roman Korostik, Jagadeesh Balam, Boris Ginsburg
This paper proposes a generative speech enhancement model based on Schrodinger bridge (SB). The proposed model is employing a tractable SB to formulate a data-to-data process between the clean speech distribution and the observed noisy speech distribution. The model is trained with a data prediction loss, aiming to recover the complex-valued clean speech coefficients, and an auxiliary time-domain loss is used to improve training of the model. The effectiveness of the proposed SB-based model is evaluated in two different speech enhancement tasks: speech denoising and speech dereverberation. The experimental results demonstrate that the proposed SB-based outperforms diffusion-based models in terms of speech quality metrics and ASR performance, e.g., resulting in relative word error rate reduction of 20% for denoising and 6% for dereverberation compared to the best baseline model. The proposed model also demonstrates improved efficiency, achieving better quality than the baselines for the same number of sampling steps and with a reduced computational cost.
Read more7/24/2024

0
Diffusion-based Speech Enhancement with Schrodinger Bridge and Symmetric Noise Schedule
Siyi Wang, Siyi Liu, Andrew Harper, Paul Kendrick, Mathieu Salzmann, Milos Cernak
Recently, diffusion-based generative models have demonstrated remarkable performance in speech enhancement tasks. However, these methods still encounter challenges, including the lack of structural information and poor performance in low Signal-to-Noise Ratio (SNR) scenarios. To overcome these challenges, we propose the Schroodinger Bridge-based Speech Enhancement (SBSE) method, which learns the diffusion processes directly between the noisy input and the clean distribution, unlike conventional diffusion-based speech enhancement systems that learn data to Gaussian distributions. To enhance performance in extremely noisy conditions, we introduce a two-stage system incorporating ratio mask information into the diffusion-based generative model. Our experimental results show that our proposed SBSE method outperforms all the baseline models and achieves state-of-the-art performance, especially in low SNR conditions. Importantly, only a few inference steps are required to achieve the best result.
Read more9/16/2024

0
Simplified Diffusion Schrodinger Bridge
Zhicong Tang, Tiankai Hang, Shuyang Gu, Dong Chen, Baining Guo
This paper introduces a novel theoretical simplification of the Diffusion Schrodinger Bridge (DSB) that facilitates its unification with Score-based Generative Models (SGMs), addressing the limitations of DSB in complex data generation and enabling faster convergence and enhanced performance. By employing SGMs as an initial solution for DSB, our approach capitalizes on the strengths of both frameworks, ensuring a more efficient training process and improving the performance of SGM. We also propose a reparameterization technique that, despite theoretical approximations, practically improves the network's fitting capabilities. Our extensive experimental evaluations confirm the effectiveness of the simplified DSB, demonstrating its significant improvements. We believe the contributions of this work pave the way for advanced generative modeling.
Read more8/14/2024
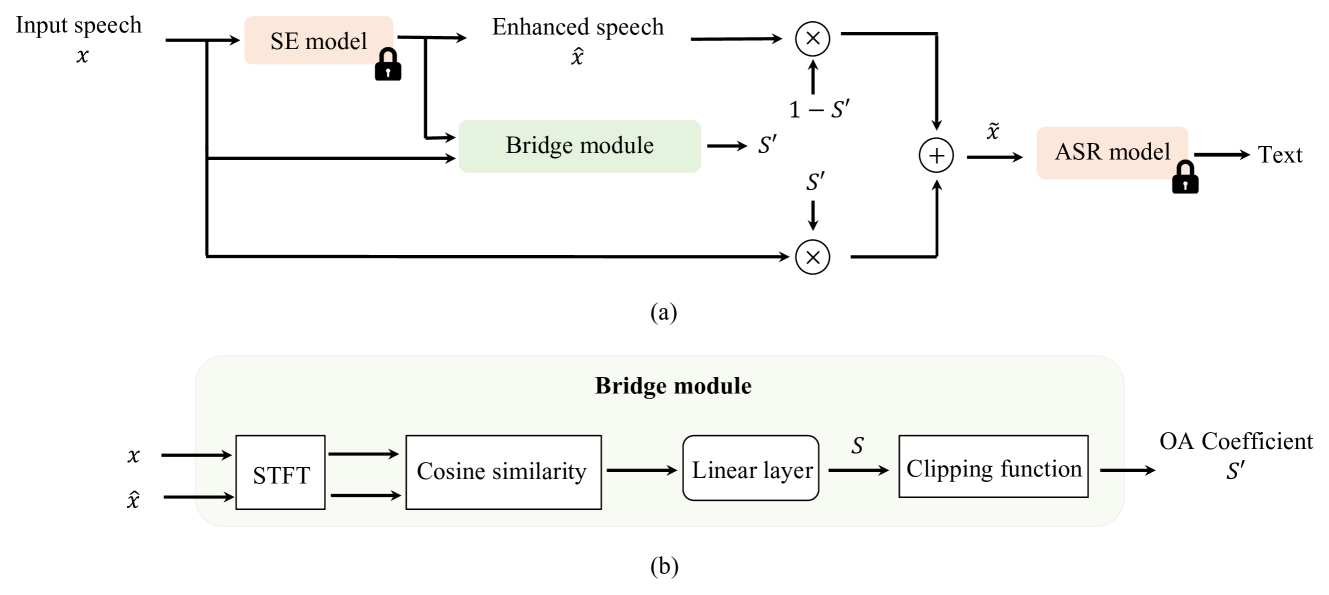
0
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Read more6/19/2024