Diffusion-based Speech Enhancement with Schrodinger Bridge and Symmetric Noise Schedule

0

Sign in to get full access
Overview
- This paper proposes a diffusion-based speech enhancement model that leverages the Schrödinger bridge and a symmetric noise schedule.
- The model aims to improve speech quality and intelligibility by removing noise and distortion from degraded audio signals.
- Key techniques include the Schrödinger bridge, a generative model that learns the transition between clean and noisy audio, and a symmetric noise schedule that stabilizes the training process.
Plain English Explanation
The paper introduces a new way to enhance speech quality by removing background noise and distortion from recorded audio. At the heart of this approach is a diffusion-based model that learns to transition between clean and noisy audio signals.
The key innovation is the use of the Schrödinger bridge, a type of generative model that can capture the complex relationship between clean and degraded speech. This allows the model to effectively "undo" the noise and distortion process.
Additionally, the researchers employ a symmetric noise schedule during training, which helps stabilize the model and improve its performance.
The end result is a speech enhancement system that can take low-quality audio recordings and output cleaner, more intelligible speech. This has many potential applications, such as improving voice assistants, teleconferencing, and hearing aids.
Technical Explanation
The core of the proposed approach is a diffusion-based speech enhancement model that leverages the Schrödinger bridge and a symmetric noise schedule.
Diffusion models work by adding progressive noise to clean data, then learning to reverse this noising process to generate new samples. The Schrödinger bridge is a type of diffusion model that can capture the complex transition between clean and noisy audio signals.
To train the model, the researchers use a symmetric noise schedule, where the amount of noise added during the forward process is mirrored in the reverse process. This helps stabilize training and improve the model's ability to denoise the audio.
The model is trained on pairs of clean and noisy speech samples. During inference, the model takes a degraded audio input and iteratively removes the noise to produce an enhanced, higher-quality output.
Experiments show that this diffusion-based approach with the Schrödinger bridge and symmetric noise schedule outperforms previous state-of-the-art speech enhancement methods in terms of speech quality and intelligibility metrics.
Critical Analysis
The paper presents a compelling and well-designed speech enhancement system that builds upon recent advances in diffusion-based generative models. The use of the Schrödinger bridge and symmetric noise schedule are novel contributions that help stabilize training and improve performance.
However, the paper does not address certain limitations or potential issues. For example, the model may struggle with certain types of noise or distortion, and its performance may degrade on low-resource or non-English speech data. Additionally, the computational and memory requirements of the diffusion-based approach could be a concern for real-time or embedded applications.
Further research is needed to understand the model's robustness, generalization capabilities, and trade-offs between performance and efficiency. Exploring ways to integrate pre-trained speech enhancement models could also be a fruitful direction.
Overall, this paper presents a promising new approach to diffusion-based speech enhancement that merits further investigation and development.
Conclusion
This paper introduces a novel diffusion-based speech enhancement model that leverages the Schrödinger bridge and a symmetric noise schedule. The key innovations enable the model to effectively remove noise and distortion from degraded audio signals, resulting in improved speech quality and intelligibility.
The proposed approach represents a significant advance in the field of speech enhancement, with potential applications in voice assistants, teleconferencing, and hearing aids. While the paper highlights several strengths of the model, further research is needed to address its limitations and explore ways to improve its robustness and efficiency.
By continuing to build upon this work, researchers can unlock new possibilities for enhancing the quality and accessibility of speech-based technologies, ultimately benefiting a wide range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion-based Speech Enhancement with Schrodinger Bridge and Symmetric Noise Schedule
Siyi Wang, Siyi Liu, Andrew Harper, Paul Kendrick, Mathieu Salzmann, Milos Cernak
Recently, diffusion-based generative models have demonstrated remarkable performance in speech enhancement tasks. However, these methods still encounter challenges, including the lack of structural information and poor performance in low Signal-to-Noise Ratio (SNR) scenarios. To overcome these challenges, we propose the Schroodinger Bridge-based Speech Enhancement (SBSE) method, which learns the diffusion processes directly between the noisy input and the clean distribution, unlike conventional diffusion-based speech enhancement systems that learn data to Gaussian distributions. To enhance performance in extremely noisy conditions, we introduce a two-stage system incorporating ratio mask information into the diffusion-based generative model. Our experimental results show that our proposed SBSE method outperforms all the baseline models and achieves state-of-the-art performance, especially in low SNR conditions. Importantly, only a few inference steps are required to achieve the best result.
Read more9/16/2024
🗣️
0
Schrodinger Bridge for Generative Speech Enhancement
Ante Juki'c, Roman Korostik, Jagadeesh Balam, Boris Ginsburg
This paper proposes a generative speech enhancement model based on Schrodinger bridge (SB). The proposed model is employing a tractable SB to formulate a data-to-data process between the clean speech distribution and the observed noisy speech distribution. The model is trained with a data prediction loss, aiming to recover the complex-valued clean speech coefficients, and an auxiliary time-domain loss is used to improve training of the model. The effectiveness of the proposed SB-based model is evaluated in two different speech enhancement tasks: speech denoising and speech dereverberation. The experimental results demonstrate that the proposed SB-based outperforms diffusion-based models in terms of speech quality metrics and ASR performance, e.g., resulting in relative word error rate reduction of 20% for denoising and 6% for dereverberation compared to the best baseline model. The proposed model also demonstrates improved efficiency, achieving better quality than the baselines for the same number of sampling steps and with a reduced computational cost.
Read more7/24/2024
🗣️
0
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Yuchen Hu, Chen Chen, Ruizhe Li, Qiushi Zhu, Eng Siong Chng
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech, underexploiting the varying noise information in real world. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner to guide the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks to enhance the noise specificity of conditioner. NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiments on VB-DEMAND dataset show that NASE effectively improves multiple mainstream diffusion SE models, especially on unseen noises.
Read more6/5/2024
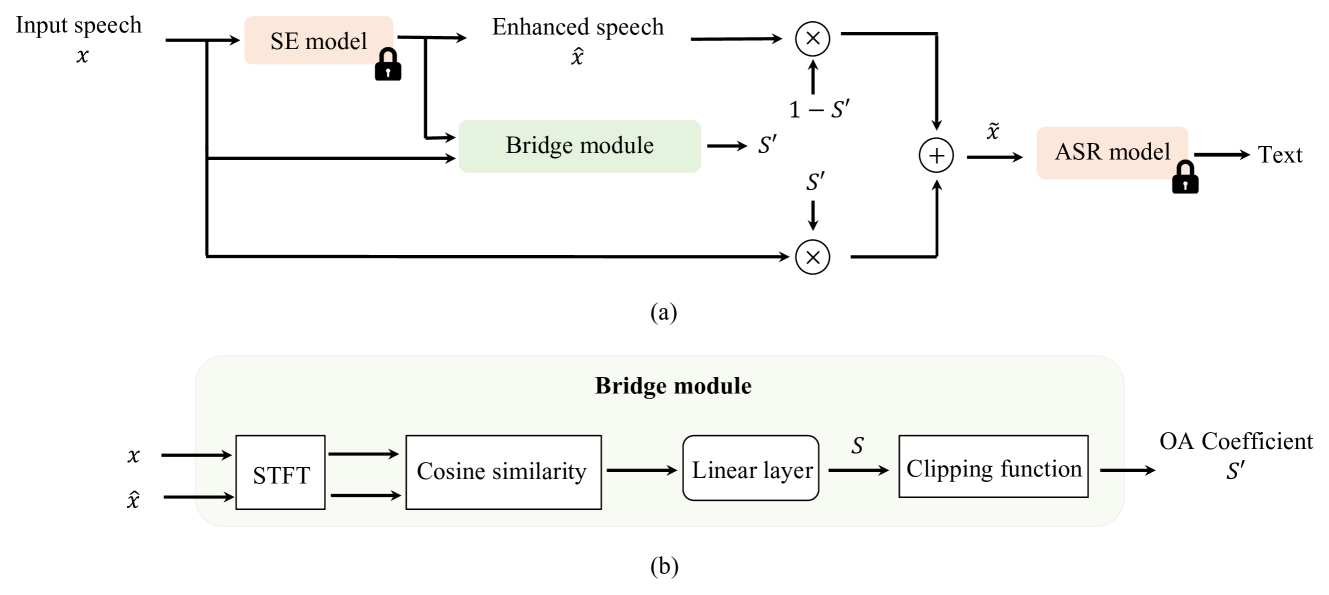
0
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Read more6/19/2024