SciDaSynth: Interactive Structured Knowledge Extraction and Synthesis from Scientific Literature with Large Language Model

0
Sign in to get full access
Overview
- This paper presents a system called "SynthesisAI" that uses large language models to automatically extract and synthesize structured knowledge from scientific literature.
- The system allows users to interactively query the extracted knowledge and receive concise, human-readable summaries.
- The approach leverages pre-trained language models to understand the content of research papers and build a knowledge graph that can be queried.
Plain English Explanation
The SynthesisAI system is designed to make it easier for researchers and the general public to access and understand the key insights from scientific literature. It uses large language models to read through research papers, extract the most important facts and relationships, and organize this information into a structured knowledge base.
This knowledge base can then be queried by users through a simple interface. For example, someone could ask "What are the main factors that influence the effectiveness of COVID-19 vaccines?" and the system would provide a concise, easy-to-understand summary of the relevant findings from the scientific literature.
The key innovation is the ability to automatically convert the unstructured information in research papers into a structured knowledge graph that can be queried. This allows users to quickly find the information they need without having to read through entire papers themselves.
Technical Explanation
The SynthesisAI system uses a multi-stage process to extract and synthesize knowledge from scientific literature:
-
Paper Extraction: The system first collects and organizes a corpus of research papers, leveraging techniques like citation parsing to identify relevant publications.
-
Knowledge Extraction: A large language model is used to read through the papers and extract key facts, entities, and relationships, building a structured knowledge graph.
-
Interactive Querying: Users can then query the knowledge graph through a natural language interface, and the system generates concise, human-readable summaries of the relevant information.
The core technical innovation is the ability to reliably extract structured knowledge from unstructured text using large language models. This allows the system to quickly synthesize insights from a large corpus of scientific literature and provide users with the information they need.
Critical Analysis
The SynthesisAI system represents an impressive advance in the field of automated research synthesis. However, it's important to note that the accuracy and completeness of the extracted knowledge will depend on the quality and coverage of the underlying corpus of research papers.
Additionally, while the system is designed to provide concise, human-readable summaries, there may be cases where the summaries oversimplify complex scientific concepts or fail to capture nuances in the original research. Users should still be encouraged to refer to the original papers for a more detailed understanding.
Finally, the SynthesisAI system is currently focused on textual information, but future versions could potentially integrate multimodal data, such as images and figures, to provide a more comprehensive understanding of the scientific literature.
Conclusion
The SynthesisAI system represents a significant step forward in the field of interactive knowledge extraction and synthesis from scientific literature. By leveraging the power of large language models, the system can quickly and automatically distill the key insights from a vast corpus of research papers, making this knowledge more accessible to researchers, policymakers, and the general public. As the technology continues to evolve, tools like SynthesisAI have the potential to dramatically accelerate the pace of scientific discovery and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SciDaSynth: Interactive Structured Knowledge Extraction and Synthesis from Scientific Literature with Large Language Model
Xingbo Wang, Samantha L. Huey, Rui Sheng, Saurabh Mehta, Fei Wang
Extraction and synthesis of structured knowledge from extensive scientific literature are crucial for advancing and disseminating scientific progress. Although many existing systems facilitate literature review and digest, they struggle to process multimodal, varied, and inconsistent information within and across the literature into structured data. We introduce SciDaSynth, a novel interactive system powered by large language models (LLMs) that enables researchers to efficiently build structured knowledge bases from scientific literature at scale. The system automatically creates data tables to organize and summarize users' interested knowledge in literature via question-answering. Furthermore, it provides multi-level and multi-faceted exploration of the generated data tables, facilitating iterative validation, correction, and refinement. Our within-subjects study with researchers demonstrates the effectiveness and efficiency of SciDaSynth in constructing quality scientific knowledge bases. We further discuss the design implications for human-AI interaction tools for data extraction and structuring.
Read more4/23/2024
💬
0
From Text to Insight: Large Language Models for Materials Science Data Extraction
Mara Schilling-Wilhelmi, Marti~no R'ios-Garc'ia, Sherjeel Shabih, Mar'ia Victoria Gil, Santiago Miret, Christoph T. Koch, Jos'e A. M'arquez, Kevin Maik Jablonka
The vast majority of materials science knowledge exists in unstructured natural language, yet structured data is crucial for innovative and systematic materials design. Traditionally, the field has relied on manual curation and partial automation for data extraction for specific use cases. The advent of large language models (LLMs) represents a significant shift, potentially enabling efficient extraction of structured, actionable data from unstructured text by non-experts. While applying LLMs to materials science data extraction presents unique challenges, domain knowledge offers opportunities to guide and validate LLM outputs. This review provides a comprehensive overview of LLM-based structured data extraction in materials science, synthesizing current knowledge and outlining future directions. We address the lack of standardized guidelines and present frameworks for leveraging the synergy between LLMs and materials science expertise. This work serves as a foundational resource for researchers aiming to harness LLMs for data-driven materials research. The insights presented here could significantly enhance how researchers across disciplines access and utilize scientific information, potentially accelerating the development of novel materials for critical societal needs.
Read more7/25/2024
0
Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
Teo Susnjak, Peter Hwang, Napoleon H. Reyes, Andre L. C. Barczak, Timothy R. McIntosh, Surangika Ranathunga
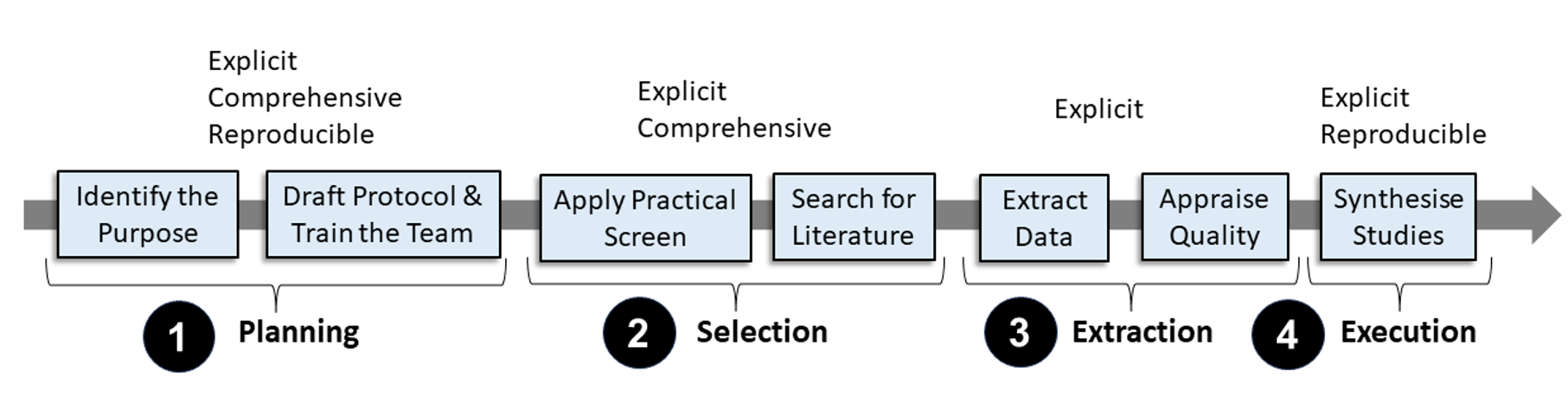
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
Read more4/16/2024
0
Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
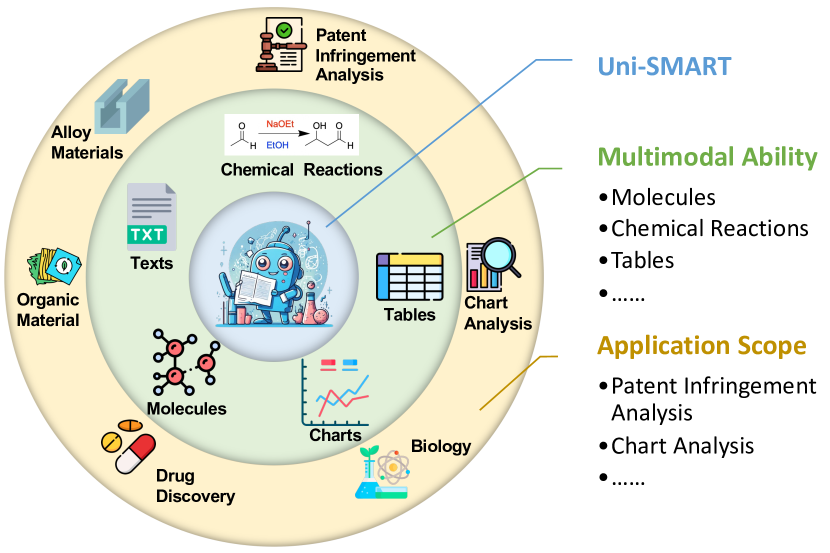
Hengxing Cai, Xiaochen Cai, Shuwen Yang, Jiankun Wang, Lin Yao, Zhifeng Gao, Junhan Chang, Sihang Li, Mingjun Xu, Changxin Wang, Hongshuai Wang, Yongge Li, Mujie Lin, Yaqi Li, Yuqi Yin, Linfeng Zhang, Guolin Ke
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as tables, charts, and molecule, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present textbf{Uni-SMART} (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over other text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.
Read more6/18/2024