Uni-SMART: Universal Science Multimodal Analysis and Research Transformer

0
Sign in to get full access
Overview
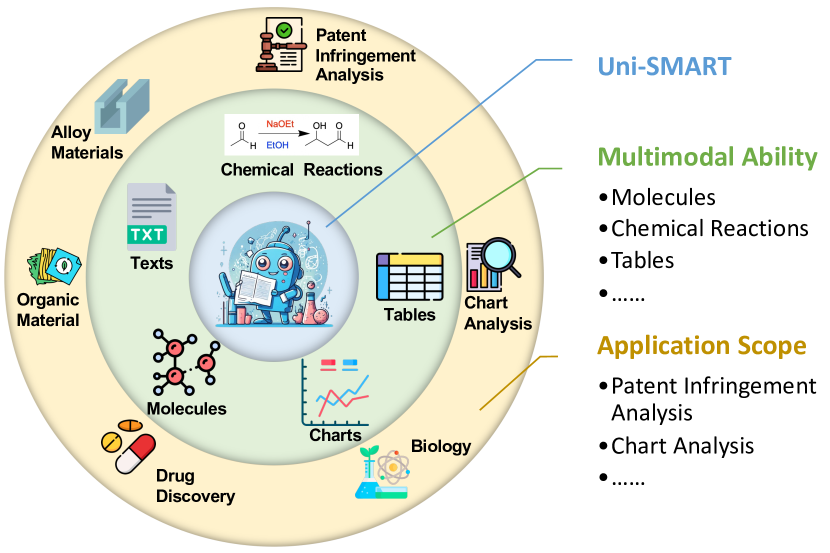
- Presents a novel language model called Uni-SMART that can perform a wide range of scientific tasks across multiple modalities (text, images, etc.)
- Demonstrates strong performance on various scientific benchmarks, including SciAssess for evaluating language model capabilities on scientific literature analysis
- Contributes to the growing body of research on multimodal large language models and their applications in science and research
Plain English Explanation
Uni-SMART is a powerful artificial intelligence (AI) model that can work with different types of data, like text and images, to help with a variety of scientific tasks. The researchers who created Uni-SMART wanted to develop an AI system that could understand and analyze scientific information more effectively than previous models.
One of the key things Uni-SMART can do is evaluate how well other AI language models (like the ones used for text-centric multimodal tasks) are able to understand and work with scientific literature. This is important because these language models are increasingly being used in scientific research and applications, and it's crucial to understand their strengths and limitations.
By testing Uni-SMART on various scientific benchmarks, the researchers showed that it can perform these tasks very well, often outperforming other state-of-the-art models. This suggests that Uni-SMART could be a valuable tool for scientists and researchers, helping them to more effectively analyze and understand scientific information, whether it's in the form of text, images, or other data.
Technical Explanation
The Uni-SMART model is built upon a large language model architecture that has been pre-trained on a diverse corpus of scientific literature and multimodal data. It uses a transformer-based encoder-decoder structure to enable it to process and generate scientific text, as well as reason about and manipulate scientific images and other modalities.
The researchers evaluate Uni-SMART's performance on a range of scientific benchmarks, including SciAssess, which tests a model's ability to understand and analyze scientific literature. They find that Uni-SMART achieves state-of-the-art results on these benchmarks, demonstrating its strong capabilities in scientific reasoning, analysis, and generation across multiple modalities.
Critical Analysis
The paper provides a robust evaluation of Uni-SMART's capabilities, but it's important to note that the model's performance may be limited to the specific tasks and datasets used in the experiments. Additionally, the researchers acknowledge that further work is needed to understand the model's biases and limitations, as well as to explore its generalizability to a wider range of scientific domains and applications.
It would also be valuable to see more detailed analysis of Uni-SMART's inner workings and the specific architectural choices that contribute to its strong performance. This could help inform the development of future multimodal language models for scientific tasks.
Conclusion
The Uni-SMART model represents an important step forward in the development of powerful multimodal language models that can tackle a wide range of scientific challenges. By demonstrating strong performance on benchmarks like SciAssess, Uni-SMART shows the potential for these models to revolutionize how scientific research and analysis is conducted. As the field of scientific large language models continues to evolve, Uni-SMART's contributions could have far-reaching implications for the advancement of science and knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
Hengxing Cai, Xiaochen Cai, Shuwen Yang, Jiankun Wang, Lin Yao, Zhifeng Gao, Junhan Chang, Sihang Li, Mingjun Xu, Changxin Wang, Hongshuai Wang, Yongge Li, Mujie Lin, Yaqi Li, Yuqi Yin, Linfeng Zhang, Guolin Ke
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as tables, charts, and molecule, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present textbf{Uni-SMART} (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over other text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.
Read more6/18/2024

0
Exploring the Potential of Multimodal LLM with Knowledge-Intensive Multimodal ASR
Minghan Wang, Yuxia Wang, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
Recent advancements in multimodal large language models (MLLMs) have made significant progress in integrating information across various modalities, yet real-world applications in educational and scientific domains remain challenging. This paper introduces the Multimodal Scientific ASR (MS-ASR) task, which focuses on transcribing scientific conference videos by leveraging visual information from slides to enhance the accuracy of technical terminologies. Realized that traditional metrics like WER fall short in assessing performance accurately, prompting the proposal of severity-aware WER (SWER) that considers the content type and severity of ASR errors. We propose the Scientific Vision Augmented ASR (SciVASR) framework as a baseline method, enabling MLLMs to improve transcript quality through post-editing. Evaluations of state-of-the-art MLLMs, including GPT-4o, show a 45% improvement over speech-only baselines, highlighting the importance of multimodal information integration.
Read more6/18/2024

0
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Zekun Li, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim, Sungyoung Ji, Byungju Lee, Xifeng Yan, Linda Ruth Petzold, Stephen D. Wilson, Woosang Lim, William Yang Wang
The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
Read more7/9/2024

0
SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding
Sihang Li, Jin Huang, Jiaxi Zhuang, Yaorui Shi, Xiaochen Cai, Mingjun Xu, Xiang Wang, Linfeng Zhang, Guolin Ke, Hengxing Cai
Scientific literature understanding is crucial for extracting targeted information and garnering insights, thereby significantly advancing scientific discovery. Despite the remarkable success of Large Language Models (LLMs), they face challenges in scientific literature understanding, primarily due to (1) a lack of scientific knowledge and (2) unfamiliarity with specialized scientific tasks. To develop an LLM specialized in scientific literature understanding, we propose a hybrid strategy that integrates continual pre-training (CPT) and supervised fine-tuning (SFT), to simultaneously infuse scientific domain knowledge and enhance instruction-following capabilities for domain-specific tasks.cIn this process, we identify two key challenges: (1) constructing high-quality CPT corpora, and (2) generating diverse SFT instructions. We address these challenges through a meticulous pipeline, including PDF text extraction, parsing content error correction, quality filtering, and synthetic instruction creation. Applying this strategy, we present a suite of LLMs: SciLitLLM, specialized in scientific literature understanding. These models demonstrate promising performance on scientific literature understanding benchmarks. Our contributions are threefold: (1) We present an effective framework that integrates CPT and SFT to adapt LLMs to scientific literature understanding, which can also be easily adapted to other domains. (2) We propose an LLM-based synthesis method to generate diverse and high-quality scientific instructions, resulting in a new instruction set -- SciLitIns -- for supervised fine-tuning in less-represented scientific domains. (3) SciLitLLM achieves promising performance improvements on scientific literature understanding benchmarks.
Read more9/2/2024