Scientific Hypothesis Generation by a Large Language Model: Laboratory Validation in Breast Cancer Treatment
2405.12258
0
0
🛸
Abstract
Large language models (LLMs) have transformed AI and achieved breakthrough performance on a wide range of tasks that require human intelligence. In science, perhaps the most interesting application of LLMs is for hypothesis formation. A feature of LLMs, which results from their probabilistic structure, is that the output text is not necessarily a valid inference from the training text. These are 'hallucinations', and are a serious problem in many applications. However, in science, hallucinations may be useful: they are novel hypotheses whose validity may be tested by laboratory experiments. Here we experimentally test the use of LLMs as a source of scientific hypotheses using the domain of breast cancer treatment. We applied the LLM GPT4 to hypothesize novel pairs of FDA-approved non-cancer drugs that target the MCF7 breast cancer cell line relative to the non-tumorigenic breast cell line MCF10A. In the first round of laboratory experiments GPT4 succeeded in discovering three drug combinations (out of 12 tested) with synergy scores above the positive controls. These combinations were itraconazole + atenolol, disulfiram + simvastatin and dipyridamole + mebendazole. GPT4 was then asked to generate new combinations after considering its initial results. It then discovered three more combinations with positive synergy scores (out of four tested), these were disulfiram + fulvestrant, mebendazole + quinacrine and disulfiram + quinacrine. A limitation of GPT4 as a generator of hypotheses was that its explanations for them were formulaic and unconvincing. We conclude that LLMs are an exciting novel source of scientific hypotheses.
Create account to get full access
Overview
- Large language models (LLMs) have made significant advancements in AI and can perform a wide range of tasks that require human intelligence, including hypothesis formation.
- LLMs can "hallucinate" or generate text that is not necessarily a valid inference from their training data, which is often seen as a problem in many applications.
- However, in the scientific domain, these hallucinations may be useful as they can represent novel hypotheses that can be tested through laboratory experiments.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that have made remarkable progress in recent years. These models can perform a wide variety of tasks that require human-like intelligence, such as understanding and generating natural language, recognizing patterns, and even generating new ideas.
One of the most exciting applications of LLMs in science is their potential to generate new hypotheses. These models have a probabilistic structure, which means that the text they generate may not always be a direct inference from their training data. These "hallucinations" are often seen as a problem in many real-world applications, as they can be inaccurate or misleading.
However, in the context of scientific research, these hallucinations may actually be useful. They can represent novel ideas or hypotheses that researchers can then test through laboratory experiments. This is particularly relevant in the field of cancer research, where new treatment approaches are sorely needed.
Technical Explanation
The researchers in this study wanted to explore the use of LLMs, specifically the GPT-4 model, as a source of scientific hypotheses in the domain of breast cancer treatment. They applied GPT-4 to generate novel pairs of FDA-approved non-cancer drugs that could potentially target the MCF7 breast cancer cell line while leaving the non-tumorigenic MCF10A cell line unaffected.
In the first round of experiments, GPT-4 successfully discovered three drug combinations (out of 12 tested) that showed synergistic effects, meaning the combination was more effective than the individual drugs. These combinations were itraconazole + atenolol, disulfiram + simvastatin, and dipyridamole + mebendazole.
The researchers then asked GPT-4 to generate new combinations after considering the initial results. This led to the discovery of three more combinations with positive synergy scores (out of four tested): disulfiram + fulvestrant, mebendazole + quinacrine, and disulfiram + quinacrine.
One limitation of using GPT-4 for hypothesis generation was that the explanations it provided for the drug combinations were somewhat formulaic and unconvincing. Despite this, the researchers concluded that LLMs are an exciting new source of scientific hypotheses that can be tested through further experimentation.
Critical Analysis
The research presented in this paper demonstrates the potential of using large language models, such as GPT-4, to generate novel scientific hypotheses. This is a promising approach, as it can help researchers explore new avenues of investigation that they may not have considered otherwise.
However, the researchers acknowledge that the explanations provided by GPT-4 for the proposed drug combinations were not entirely convincing. This is a common limitation of large language models in the context of multimodal tasks, as they may struggle to provide clear, coherent reasoning for their outputs.
Additionally, while the researchers were able to validate some of the hypotheses generated by GPT-4 through laboratory experiments, it is important to consider the potential limitations and biases inherent in these models. Large language models can sometimes exhibit biases or make mistakes in their outputs, which could lead to the generation of hypotheses that are not scientifically sound.
Further research is needed to fully understand the capabilities and limitations of using LLMs for scientific hypothesis generation, as well as to develop techniques for improving the interpretability and reliability of their outputs.
Conclusion
This research demonstrates the exciting potential of using large language models as a source of novel scientific hypotheses. By leveraging the probabilistic nature of these models, researchers were able to uncover several promising drug combinations for breast cancer treatment that warrant further investigation.
While there are still some limitations to address, such as the need for more convincing explanations, this work represents an important step forward in the application of advanced AI techniques to scientific discovery. As the field of large language models continues to evolve, we can expect to see even more exciting developments in the use of AI for scientific research and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
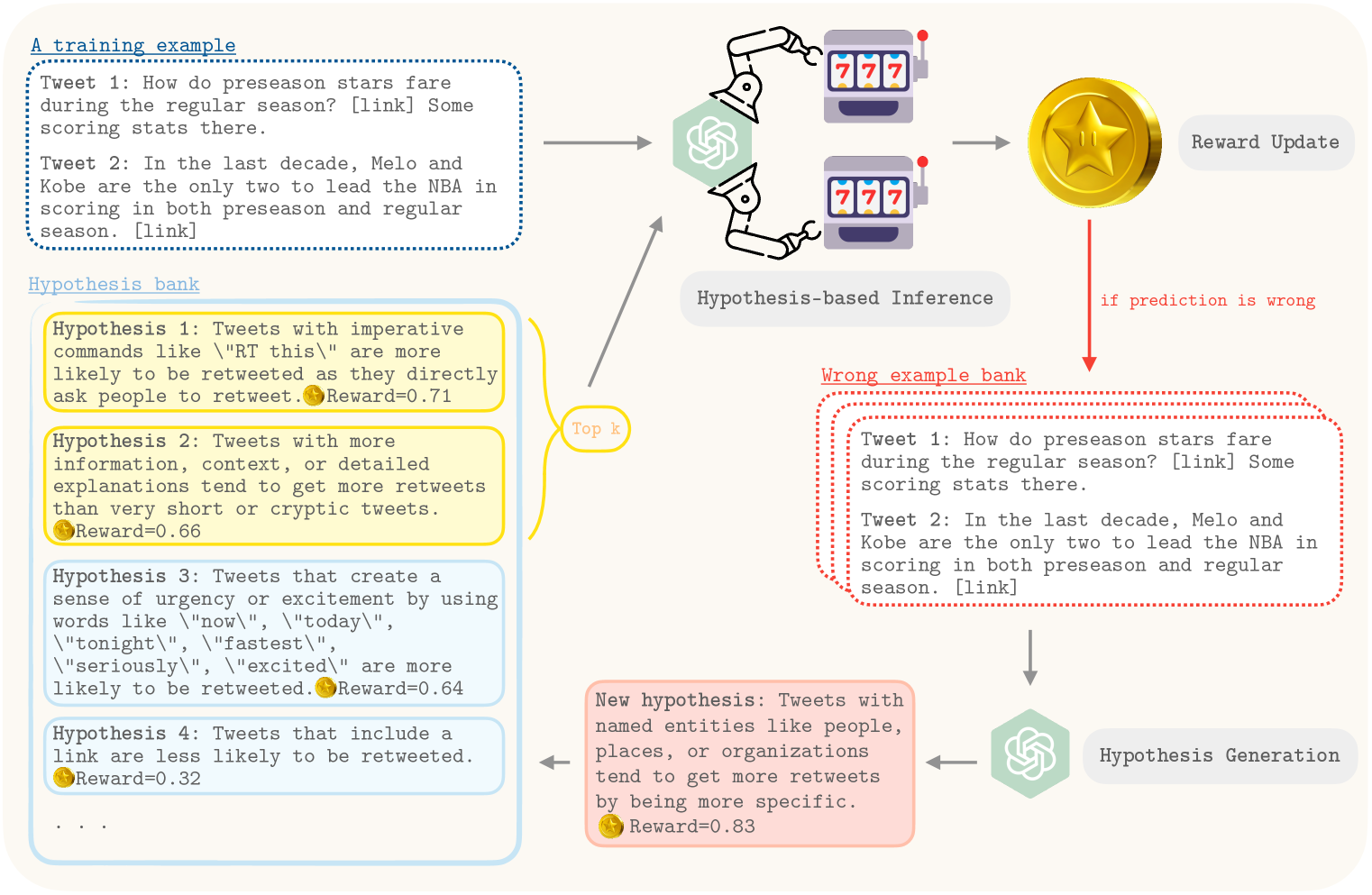
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
0
0
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
4/9/2024
💬
Large Language Models for Automated Open-domain Scientific Hypotheses Discovery
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Soujanya Poria, Erik Cambria
0
0
Hypothetical induction is recognized as the main reasoning type when scientists make observations about the world and try to propose hypotheses to explain those observations. Past research on hypothetical induction is under a constrained setting: (1) the observation annotations in the dataset are carefully manually handpicked sentences (resulting in a close-domain setting); and (2) the ground truth hypotheses are mostly commonsense knowledge, making the task less challenging. In this work, we tackle these problems by proposing the first dataset for social science academic hypotheses discovery, with the final goal to create systems that automatically generate valid, novel, and helpful scientific hypotheses, given only a pile of raw web corpus. Unlike previous settings, the new dataset requires (1) using open-domain data (raw web corpus) as observations; and (2) proposing hypotheses even new to humanity. A multi-module framework is developed for the task, including three different feedback mechanisms to boost performance, which exhibits superior performance in terms of both GPT-4 based and expert-based evaluation. To the best of our knowledge, this is the first work showing that LLMs are able to generate novel (''not existing in literature'') and valid (''reflecting reality'') scientific hypotheses.
6/13/2024
🤯
D-NLP at SemEval-2024 Task 2: Evaluating Clinical Inference Capabilities of Large Language Models
Duygu Altinok
0
0
Large language models (LLMs) have garnered significant attention and widespread usage due to their impressive performance in various tasks. However, they are not without their own set of challenges, including issues such as hallucinations, factual inconsistencies, and limitations in numerical-quantitative reasoning. Evaluating LLMs in miscellaneous reasoning tasks remains an active area of research. Prior to the breakthrough of LLMs, Transformers had already proven successful in the medical domain, effectively employed for various natural language understanding (NLU) tasks. Following this trend, LLMs have also been trained and utilized in the medical domain, raising concerns regarding factual accuracy, adherence to safety protocols, and inherent limitations. In this paper, we focus on evaluating the natural language inference capabilities of popular open-source and closed-source LLMs using clinical trial reports as the dataset. We present the performance results of each LLM and further analyze their performance on a development set, particularly focusing on challenging instances that involve medical abbreviations and require numerical-quantitative reasoning. Gemini, our leading LLM, achieved a test set F1-score of 0.748, securing the ninth position on the task scoreboard. Our work is the first of its kind, offering a thorough examination of the inference capabilities of LLMs within the medical domain.
5/8/2024

Tx-LLM: A Large Language Model for Therapeutics
Juan Manuel Zambrano Chaves, Eric Wang, Tao Tu, Eeshit Dhaval Vaishnav, Byron Lee, S. Sara Mahdavi, Christopher Semturs, David Fleet, Vivek Natarajan, Shekoofeh Azizi
0
0
Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable. However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities. Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities(small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22. Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining. We observe evidence of positive transfer between tasks with diverse drug types (e.g.,tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance. We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
6/11/2024