Large Language Models for Automated Open-domain Scientific Hypotheses Discovery
2309.02726
2
0
💬
Abstract
Hypothetical induction is recognized as the main reasoning type when scientists make observations about the world and try to propose hypotheses to explain those observations. Past research on hypothetical induction is under a constrained setting: (1) the observation annotations in the dataset are carefully manually handpicked sentences (resulting in a close-domain setting); and (2) the ground truth hypotheses are mostly commonsense knowledge, making the task less challenging. In this work, we tackle these problems by proposing the first dataset for social science academic hypotheses discovery, with the final goal to create systems that automatically generate valid, novel, and helpful scientific hypotheses, given only a pile of raw web corpus. Unlike previous settings, the new dataset requires (1) using open-domain data (raw web corpus) as observations; and (2) proposing hypotheses even new to humanity. A multi-module framework is developed for the task, including three different feedback mechanisms to boost performance, which exhibits superior performance in terms of both GPT-4 based and expert-based evaluation. To the best of our knowledge, this is the first work showing that LLMs are able to generate novel (''not existing in literature'') and valid (''reflecting reality'') scientific hypotheses.
Create account to get full access
Overview
- This paper tackles the challenge of getting large language models (LLMs) to generate novel and valid scientific hypotheses from raw web data, rather than just summarizing existing knowledge.
- The authors create a new dataset focused on social science academic hypotheses, which requires generating hypotheses that may be new to humanity, rather than just common sense knowledge.
- A multi-module framework is developed to generate these novel hypotheses, with several feedback mechanisms to improve performance.
- The authors claim this is the first work showing that LLMs can generate truly novel and valid scientific hypotheses.
Plain English Explanation
Hypothetical induction is the main way scientists try to explain observations about the world by proposing new hypotheses. Previous research on this has been limited, either focusing on a narrow domain of observations or just generating common sense knowledge.
In this new work, the researchers are tackling more challenging, open-domain hypothesis generation. They created a dataset of social science academic hypotheses, where the goal is to propose hypotheses that may be entirely new to humanity, not just restate existing knowledge. This is important because it pushes language models to go beyond summarizing what's already known and try to generate genuinely novel and useful scientific ideas.
To do this, the researchers developed a multi-part system that takes in raw web data as observations and tries to output novel, valid hypotheses. They used several feedback mechanisms to improve the model's performance, such as having it assess its own outputs.
The key claim is that this is the first work showing that large language models can generate hypotheses that are both new to science and accurately reflect reality, rather than just regurgitating existing knowledge. This suggests language models may be able to learn general rules and principles that allow them to reason about the world in more sophisticated ways, with potential applications in automating the scientific process.
Technical Explanation
The key innovation in this work is the introduction of a new dataset for scientific hypothesis generation, focused on the social sciences. Unlike previous datasets, this one requires the model to propose hypotheses that are not just common sense, but potentially novel and unknown to humanity.
To tackle this challenge, the researchers developed a multi-module framework. The first module takes in raw web data as "observations" and encodes them. The second module then generates candidate hypotheses based on these observations. A third module assesses the quality of the hypotheses, providing feedback to the generator.
The researchers experimented with three different feedback mechanisms: (1) a binary classifier to assess if a hypothesis is valid, (2) a language model to score the "interestingness" of a hypothesis, and (3) a module that checks if a hypothesis is novel by comparing it to a database of existing hypotheses.
Through extensive experiments, the researchers show that this multi-module approach significantly outperforms simpler baselines in generating hypotheses that are judged to be both novel and valid by both GPT-4-based and human expert evaluations. This is a notable advancement over prior work in this area.
Critical Analysis
While this research represents an important step forward in getting language models to engage in more sophisticated scientific reasoning, there are some caveats to consider.
First, the dataset is still limited to the social sciences, and it's unclear how well the approach would generalize to the natural sciences or other domains. The observations are also still drawn from web data, which may not fully capture the depth and nuance of academic research.
Additionally, the evaluation of novelty relies on comparing generated hypotheses to a database - but this database may be incomplete, and some genuinely novel ideas could be missed. There are also challenges in precisely defining and measuring the "validity" of hypotheses, which ultimately require empirical testing to verify.
Further research is needed to push the boundaries of what language models can do in terms of scientific discovery. Potential directions include integrating the model with real-world data sources, developing more robust novelty and validity assessments, and exploring how these systems could complement and augment human researchers rather than fully replace them.
Overall, this work represents an exciting development, but there is still much to explore in getting machines to engage in open-ended, creative scientific reasoning.
Conclusion
This paper presents a novel approach to getting large language models to generate scientifically valid and novel hypotheses, going beyond just summarizing existing knowledge. By creating a challenging new dataset focused on social science hypotheses, and developing a multi-module framework with various feedback mechanisms, the researchers have demonstrated significant progress in this area.
While there are still limitations and open questions, this research suggests that language models may be capable of more sophisticated reasoning about the world than previously believed. With further development, systems like this could potentially assist or even automate certain aspects of the scientific process, accelerating discovery and understanding. However, the role of human researchers and empirical validation will remain crucial even as these technologies advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
0
0
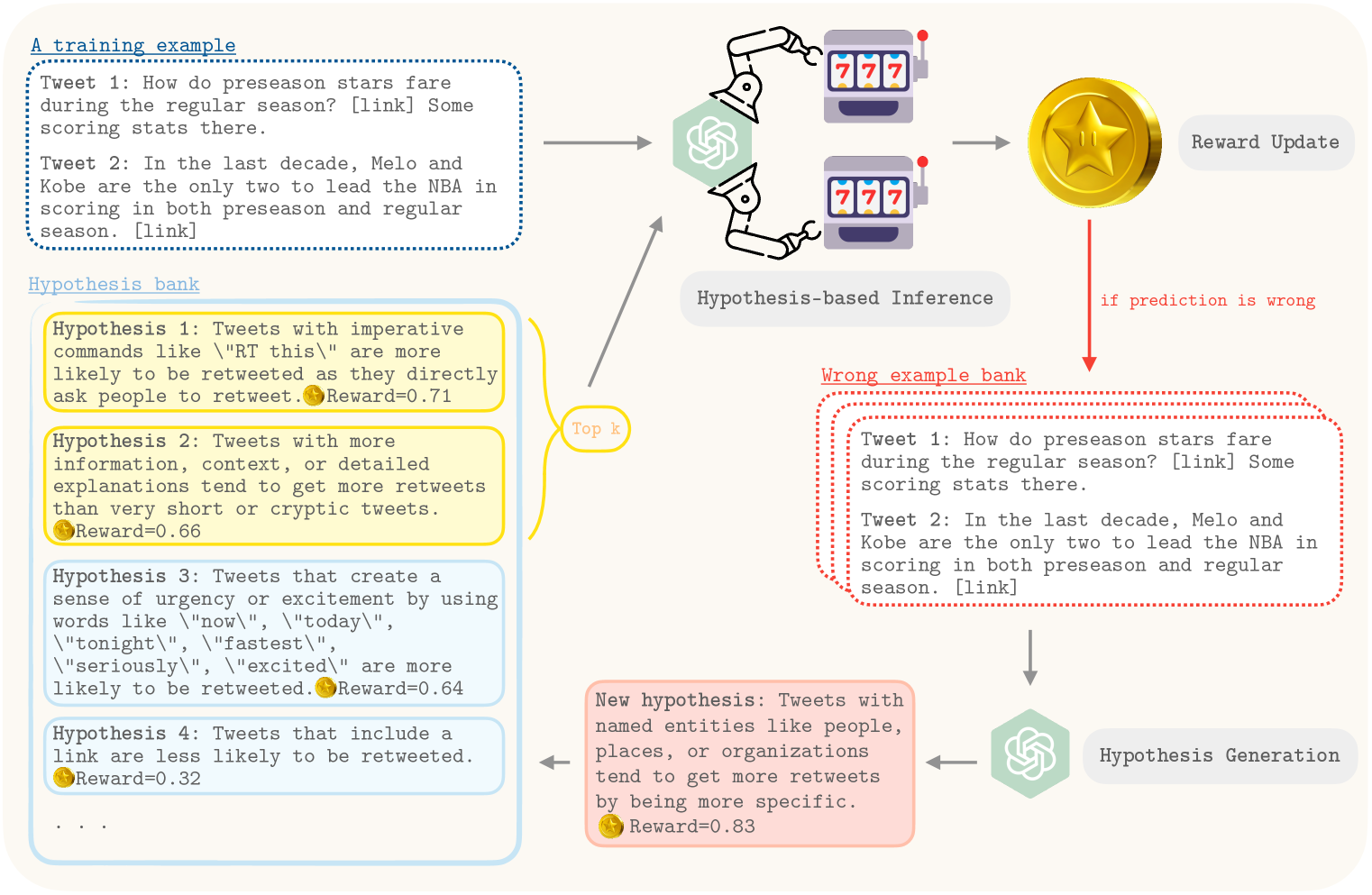
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
4/9/2024
💬
Hypothesis Search: Inductive Reasoning with Language Models
Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, Noah D. Goodman
0
0
Inductive reasoning is a core problem-solving capacity: humans can identify underlying principles from a few examples, which robustly generalize to novel scenarios. Recent work evaluates large language models (LLMs) on inductive reasoning tasks by directly prompting them yielding in context learning. This works well for straightforward inductive tasks but performs poorly on complex tasks such as the Abstraction and Reasoning Corpus (ARC). In this work, we propose to improve the inductive reasoning ability of LLMs by generating explicit hypotheses at multiple levels of abstraction: we prompt the LLM to propose multiple abstract hypotheses about the problem, in natural language, then implement the natural language hypotheses as concrete Python programs. These programs can be verified by running on observed examples and generalized to novel inputs. To reduce the hypothesis search space, we explore steps to filter the set of hypotheses to implement: we either ask the LLM to summarize them into a smaller set of hypotheses or ask human annotators to select a subset. We verify our pipeline's effectiveness on the ARC visual inductive reasoning benchmark, its variant 1D-ARC, string transformation dataset SyGuS, and list transformation dataset List Functions. On a random 100-problem subset of ARC, our automated pipeline using LLM summaries achieves 30% accuracy, outperforming the direct prompting baseline (accuracy of 17%). With the minimal human input of selecting from LLM-generated candidates, performance is boosted to 33%. Our ablations show that both abstract hypothesis generation and concrete program representations benefit LLMs on inductive reasoning tasks.
6/3/2024
🛸
Scientific Hypothesis Generation by a Large Language Model: Laboratory Validation in Breast Cancer Treatment
Abbi Abdel-Rehim, Hector Zenil, Oghenejokpeme Orhobor, Marie Fisher, Ross J. Collins, Elizabeth Bourne, Gareth W. Fearnley, Emma Tate, Holly X. Smith, Larisa N. Soldatova, Ross D. King
0
0
Large language models (LLMs) have transformed AI and achieved breakthrough performance on a wide range of tasks that require human intelligence. In science, perhaps the most interesting application of LLMs is for hypothesis formation. A feature of LLMs, which results from their probabilistic structure, is that the output text is not necessarily a valid inference from the training text. These are 'hallucinations', and are a serious problem in many applications. However, in science, hallucinations may be useful: they are novel hypotheses whose validity may be tested by laboratory experiments. Here we experimentally test the use of LLMs as a source of scientific hypotheses using the domain of breast cancer treatment. We applied the LLM GPT4 to hypothesize novel pairs of FDA-approved non-cancer drugs that target the MCF7 breast cancer cell line relative to the non-tumorigenic breast cell line MCF10A. In the first round of laboratory experiments GPT4 succeeded in discovering three drug combinations (out of 12 tested) with synergy scores above the positive controls. These combinations were itraconazole + atenolol, disulfiram + simvastatin and dipyridamole + mebendazole. GPT4 was then asked to generate new combinations after considering its initial results. It then discovered three more combinations with positive synergy scores (out of four tested), these were disulfiram + fulvestrant, mebendazole + quinacrine and disulfiram + quinacrine. A limitation of GPT4 as a generator of hypotheses was that its explanations for them were formulaic and unconvincing. We conclude that LLMs are an exciting novel source of scientific hypotheses.
6/6/2024
Large Language Models can Learn Rules
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
0
0
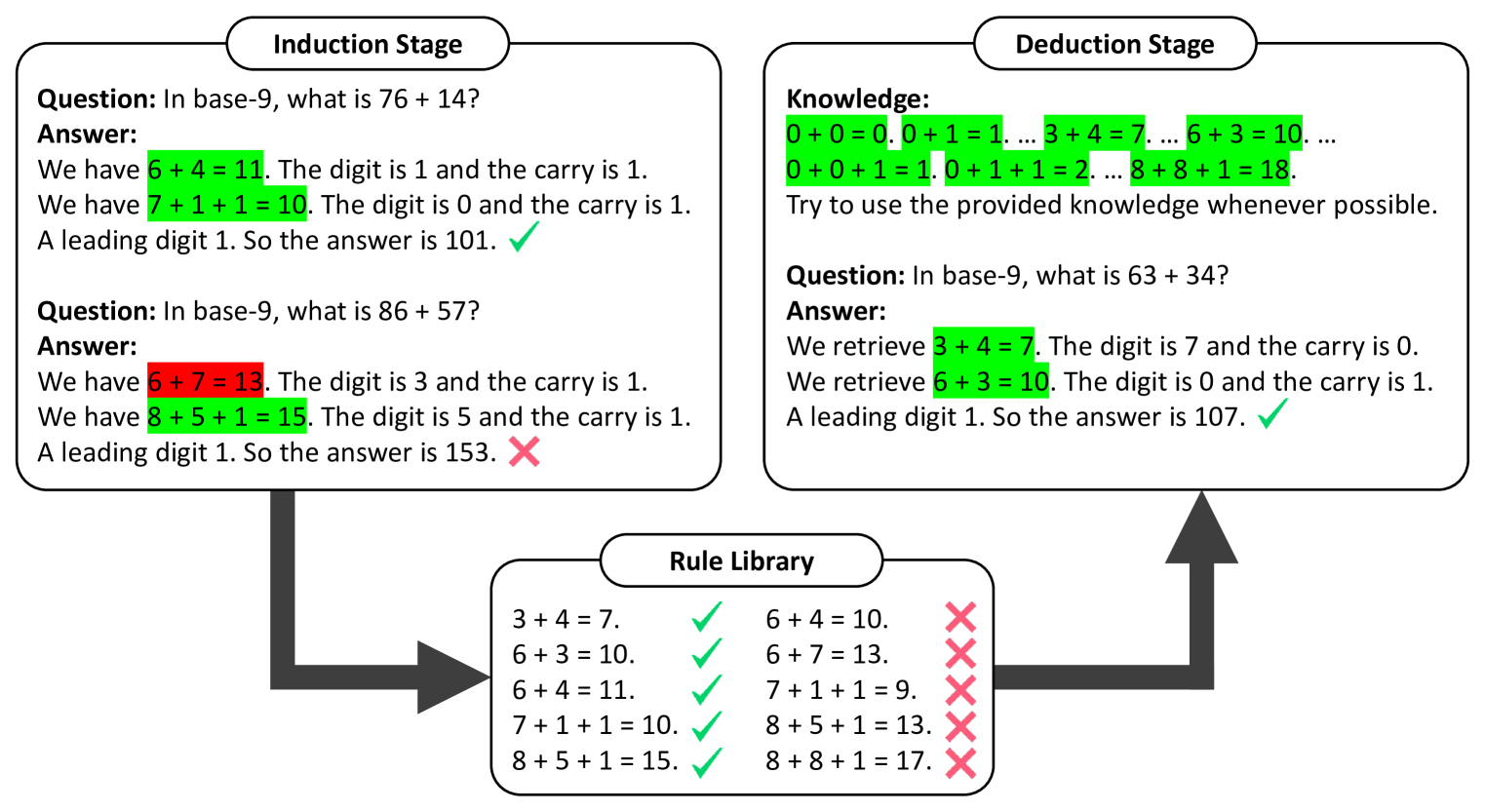
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
4/26/2024