SciFIBench: Benchmarking Large Multimodal Models for Scientific Figure Interpretation

0

Sign in to get full access
Overview
• This paper introduces SciFIBench, a new benchmark for evaluating the performance of large multimodal models (LMMs) on the task of scientific figure interpretation. • The benchmark includes diverse datasets and tasks related to recognizing figure components, classifying figure types, and answering questions about scientific figures. • The authors evaluate several state-of-the-art LMMs on SciFIBench and provide insights into the strengths and weaknesses of these models for scientific figure understanding.
Plain English Explanation
The paper presents a new benchmark called SciFIBench that is designed to test how well large AI models can understand and interpret scientific figures, such as graphs, charts, and diagrams. These types of figures are commonly used in scientific papers and presentations to convey important information and insights.
The key idea behind SciFIBench is to provide a comprehensive set of tasks and datasets that can be used to evaluate the performance of large multimodal models (LMMs) – AI models that can process and combine both text and visual information. The benchmark includes tasks such as recognizing the different components of a figure (e.g., axes, legends, data points), classifying the type of figure (e.g., bar graph, scatter plot, flow diagram), and answering questions about the content and meaning of the figure.
By evaluating the performance of state-of-the-art LMMs on this benchmark, the authors aim to uncover the strengths and limitations of these models when it comes to understanding and interpreting scientific figures. This information can then be used to guide the development of more capable and reliable AI systems for scientific figure interpretation, which could have important implications for fields like scientific literature analysis, data visualization, and scientific communication.
Technical Explanation
The paper introduces SciFIBench, a new benchmark for evaluating the performance of large multimodal models (LMMs) on scientific figure interpretation tasks. The benchmark includes several datasets and tasks:
- Figure Component Recognition: Identifying the different elements of a scientific figure, such as axes, legends, and data points.
- Figure Type Classification: Classifying the type of figure, such as bar graph, scatter plot, or flow diagram.
- Figure Question Answering: Answering questions about the content and meaning of a scientific figure.
The authors evaluate the performance of several state-of-the-art LMMs, including [link to FakeBench paper], [link to MMBench paper], and [link to GlitchBench paper], on the SciFIBench tasks. They find that while these models perform well on some tasks, they struggle with others, particularly when it comes to understanding the more complex and domain-specific aspects of scientific figures.
The authors also analyze the strengths and weaknesses of the different models, providing insights into the types of figure understanding capabilities that current LMMs possess and the areas where further research and development are needed.
Critical Analysis
The SciFIBench benchmark presented in this paper is a valuable contribution to the field of scientific figure interpretation, as it provides a standardized and comprehensive way to evaluate the performance of large multimodal models in this domain. The inclusion of diverse datasets and tasks reflects the complex and multifaceted nature of figure understanding, which is an important skill for AI systems to possess in order to support scientific research and communication.
However, the paper does acknowledge several limitations and caveats of the current benchmark. For example, the datasets used in SciFIBench may not fully capture the diversity and complexity of scientific figures encountered in the real world, and the evaluation tasks may not fully capture all the nuances of figure understanding. Additionally, the paper does not address the potential biases or fairness issues that may arise when deploying these models in real-world settings.
Further research is needed to address these limitations and to explore other aspects of scientific figure interpretation, such as the role of domain-specific knowledge, the integration of figure understanding with other scientific reasoning tasks, and the development of more interpretable and explainable AI models for this domain. [link to MILEBench paper] and [link to VisualWebBench paper] may provide valuable insights in these areas.
Conclusion
The SciFIBench benchmark introduced in this paper represents an important step forward in the assessment of large multimodal models for scientific figure interpretation. By providing a standardized and comprehensive set of tasks and datasets, the benchmark can help drive the development of more capable and reliable AI systems for this critical task.
The authors' evaluation of several state-of-the-art LMMs on SciFIBench provides valuable insights into the current strengths and limitations of these models, and highlights the need for further research and development to address the complex and domain-specific challenges of scientific figure understanding. As AI systems continue to play an increasingly important role in scientific research and communication, the continued advancement of technologies for scientific figure interpretation will be crucial for supporting the progress of science and the dissemination of scientific knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SciFIBench: Benchmarking Large Multimodal Models for Scientific Figure Interpretation
Jonathan Roberts, Kai Han, Neil Houlsby, Samuel Albanie
Large multimodal models (LMMs) have proven flexible and generalisable across many tasks and fields. Although they have strong potential to aid scientific research, their capabilities in this domain are not well characterised. A key aspect of scientific research is the ability to understand and interpret figures, which serve as a rich, compressed source of complex information. In this work, we present SciFIBench, a scientific figure interpretation benchmark. Our main benchmark consists of a 1000-question gold set of multiple-choice questions split between two tasks across 12 categories. The questions are curated from CS arXiv paper figures and captions, using adversarial filtering to find hard negatives and human verification for quality control. We evaluate 26 LMMs on SciFIBench, finding it to be a challenging benchmark. Finally, we investigate the alignment and reasoning faithfulness of the LMMs on augmented question sets from our benchmark. We release SciFIBench to encourage progress in this domain.
Read more5/15/2024
0
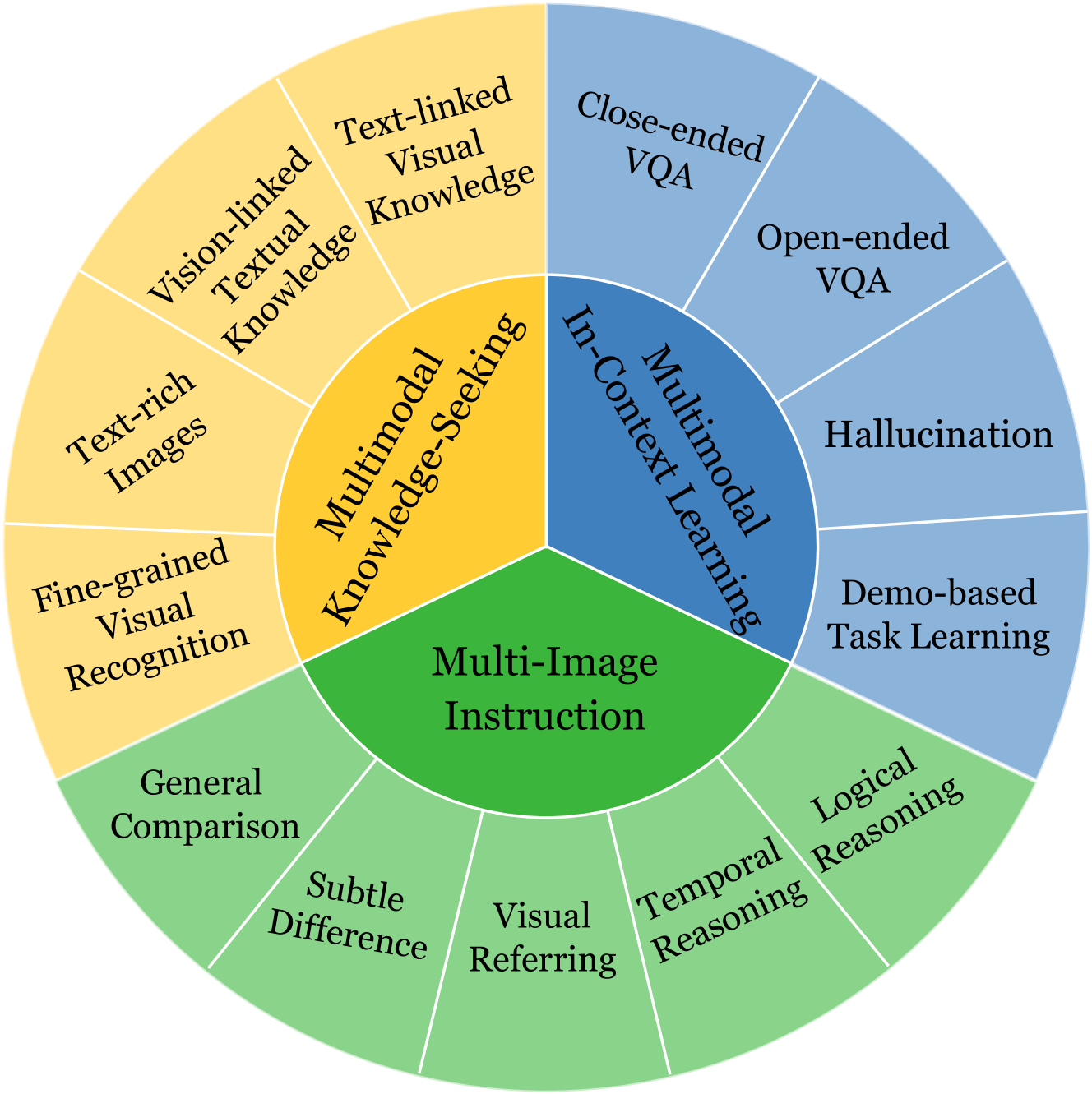
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024

0
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Zekun Li, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim, Sungyoung Ji, Byungju Lee, Xifeng Yan, Linda Ruth Petzold, Stephen D. Wilson, Woosang Lim, William Yang Wang
The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
Read more7/9/2024
0
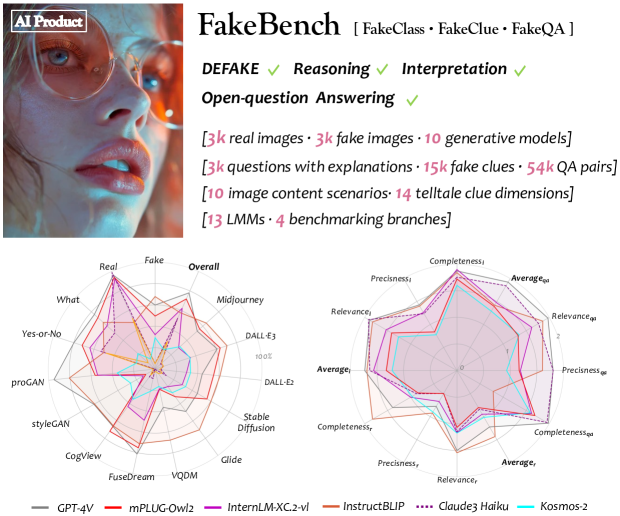
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, Weisi Lin
The ability to distinguish whether an image is generated by artificial intelligence (AI) is a crucial ingredient in human intelligence, usually accompanied by a complex and dialectical forensic and reasoning process. However, current fake image detection models and databases focus on binary classification without understandable explanations for the general populace. This weakens the credibility of authenticity judgment and may conceal potential model biases. Meanwhile, large multimodal models (LMMs) have exhibited immense visual-text capabilities on various tasks, bringing the potential for explainable fake image detection. Therefore, we pioneer the probe of LMMs for explainable fake image detection by presenting a multimodal database encompassing textual authenticity descriptions, the FakeBench. For construction, we first introduce a fine-grained taxonomy of generative visual forgery concerning human perception, based on which we collect forgery descriptions in human natural language with a human-in-the-loop strategy. FakeBench examines LMMs with four evaluation criteria: detection, reasoning, interpretation and fine-grained forgery analysis, to obtain deeper insights into image authenticity-relevant capabilities. Experiments on various LMMs confirm their merits and demerits in different aspects of fake image detection tasks. This research presents a paradigm shift towards transparency for the fake image detection area and reveals the need for greater emphasis on forensic elements in visual-language research and AI risk control. FakeBench will be available at https://github.com/Yixuan423/FakeBench.
Read more9/10/2024