FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models

0
Sign in to get full access
Overview
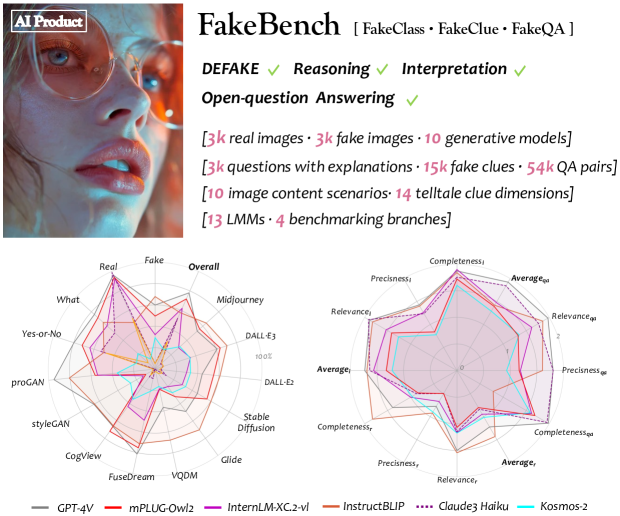
- This paper introduces FakeBench, a new benchmark dataset and evaluation framework for assessing the capabilities of large multimodal models in detecting fake images.
- The dataset includes a diverse collection of real and synthetic images, along with detailed annotations and metadata to support comprehensive evaluation.
- The researchers explore the reasoning and interpretation abilities of these models, aiming to uncover their potential Achilles' heels when it comes to identifying manipulated or generated images.
Plain English Explanation
The researchers have created a new dataset called FakeBench to help test the abilities of powerful AI models that can process both images and text. These large multimodal models are becoming increasingly advanced, but the researchers want to understand their limitations when it comes to detecting fake or manipulated images.
The FakeBench dataset includes a wide variety of real and synthetic images, along with detailed information about each one. This allows the researchers to thoroughly assess how well the AI models can reason about and interpret the images, and identify any weaknesses or 'Achilles' heels' in their ability to spot fakes.
By using this comprehensive benchmark, the researchers aim to gain insights into the current state of these advanced AI systems and identify areas where they may still struggle, which could inform future model development and deployment.
Technical Explanation
The paper introduces the FakeBench dataset and evaluation framework for assessing the capabilities of large multimodal models in detecting fake images. The dataset includes a diverse collection of real and synthetic images, with detailed annotations and metadata to support comprehensive evaluation.
The researchers explore the reasoning and interpretation abilities of these models, aiming to uncover their potential Achilles' heels when it comes to identifying manipulated or generated images. The dataset is designed to challenge the models across a range of factors, such as image fidelity, semantic consistency, and contextual cues, to gain insights into their strengths and weaknesses.
By leveraging the FakeBench benchmark, the researchers seek to better understand the current state of these advanced AI systems and identify areas where they may still struggle in accurately distinguishing real from fake images. This knowledge could help guide future model development and deployment, ensuring these powerful tools are able to reliably detect and mitigate the growing threat of sophisticated image manipulation techniques.
Critical Analysis
The FakeBench dataset and evaluation framework presented in this paper provide a valuable contribution to the field of fake image detection. By assembling a diverse and well-annotated collection of real and synthetic images, the researchers have created a comprehensive testbed for assessing the capabilities of large multimodal models.
One potential limitation of the study is the reliance on current state-of-the-art models, which may not fully represent the rapid pace of progress in this area. As these models continue to evolve, the findings from FakeBench may become outdated relatively quickly. The authors acknowledge this challenge and suggest the need for ongoing benchmark updates to keep pace with advancements in the field.
Additionally, while the dataset covers a wide range of image manipulation techniques, there may be emerging or novel methods that are not yet represented. Maintaining the relevance and comprehensiveness of the FakeBench benchmark will be an important consideration for future research.
Despite these caveats, the insights gained from the FakeBench evaluation can still provide valuable guidance for model developers and researchers working to improve the reliability and robustness of fake image detection systems. Continued efforts to push the boundaries of these capabilities will be crucial as the threat of AI-generated misinformation continues to evolve.
Conclusion
The FakeBench dataset and evaluation framework introduced in this paper represent a significant step forward in assessing the abilities of large multimodal models to detect fake images. By assembling a diverse and well-annotated collection of real and synthetic images, the researchers have created a comprehensive testbed for exploring the reasoning and interpretation capabilities of these advanced AI systems.
The findings from the FakeBench evaluation can help guide the development of more reliable and robust fake image detection models, which will be essential in mitigating the growing threat of sophisticated image manipulation techniques. As these models continue to evolve, maintaining the relevance and comprehensiveness of the FakeBench benchmark will be an ongoing challenge, but one that is vital to ensuring the integrity of visual information in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, Weisi Lin
The ability to distinguish whether an image is generated by artificial intelligence (AI) is a crucial ingredient in human intelligence, usually accompanied by a complex and dialectical forensic and reasoning process. However, current fake image detection models and databases focus on binary classification without understandable explanations for the general populace. This weakens the credibility of authenticity judgment and may conceal potential model biases. Meanwhile, large multimodal models (LMMs) have exhibited immense visual-text capabilities on various tasks, bringing the potential for explainable fake image detection. Therefore, we pioneer the probe of LMMs for explainable fake image detection by presenting a multimodal database encompassing textual authenticity descriptions, the FakeBench. For construction, we first introduce a fine-grained taxonomy of generative visual forgery concerning human perception, based on which we collect forgery descriptions in human natural language with a human-in-the-loop strategy. FakeBench examines LMMs with four evaluation criteria: detection, reasoning, interpretation and fine-grained forgery analysis, to obtain deeper insights into image authenticity-relevant capabilities. Experiments on various LMMs confirm their merits and demerits in different aspects of fake image detection tasks. This research presents a paradigm shift towards transparency for the fake image detection area and reveals the need for greater emphasis on forensic elements in visual-language research and AI risk control. FakeBench will be available at https://github.com/Yixuan423/FakeBench.
Read more9/10/2024

0
MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs
Xuannan Liu, Zekun Li, Peipei Li, Shuhan Xia, Xing Cui, Linzhi Huang, Huaibo Huang, Weihong Deng, Zhaofeng He
Current multimodal misinformation detection (MMD) methods often assume a single source and type of forgery for each sample, which is insufficient for real-world scenarios where multiple forgery sources coexist. The lack of a benchmark for mixed-source misinformation has hindered progress in this field. To address this, we introduce MMFakeBench, the first comprehensive benchmark for mixed-source MMD. MMFakeBench includes 3 critical sources: textual veracity distortion, visual veracity distortion, and cross-modal consistency distortion, along with 12 sub-categories of misinformation forgery types. We further conduct an extensive evaluation of 6 prevalent detection methods and 15 large vision-language models (LVLMs) on MMFakeBench under a zero-shot setting. The results indicate that current methods struggle under this challenging and realistic mixed-source MMD setting. Additionally, we propose an innovative unified framework, which integrates rationales, actions, and tool-use capabilities of LVLM agents, significantly enhancing accuracy and generalization. We believe this study will catalyze future research into more realistic mixed-source multimodal misinformation and provide a fair evaluation of misinformation detection methods.
Read more8/22/2024

0
A-Bench: Are LMMs Masters at Evaluating AI-generated Images?
Zicheng Zhang, Haoning Wu, Chunyi Li, Yingjie Zhou, Wei Sun, Xiongkuo Min, Zijian Chen, Xiaohong Liu, Weisi Lin, Guangtao Zhai
How to accurately and efficiently assess AI-generated images (AIGIs) remains a critical challenge for generative models. Given the high costs and extensive time commitments required for user studies, many researchers have turned towards employing large multi-modal models (LMMs) as AIGI evaluators, the precision and validity of which are still questionable. Furthermore, traditional benchmarks often utilize mostly natural-captured content rather than AIGIs to test the abilities of LMMs, leading to a noticeable gap for AIGIs. Therefore, we introduce A-Bench in this paper, a benchmark designed to diagnose whether LMMs are masters at evaluating AIGIs. Specifically, A-Bench is organized under two key principles: 1) Emphasizing both high-level semantic understanding and low-level visual quality perception to address the intricate demands of AIGIs. 2) Various generative models are utilized for AIGI creation, and various LMMs are employed for evaluation, which ensures a comprehensive validation scope. Ultimately, 2,864 AIGIs from 16 text-to-image models are sampled, each paired with question-answers annotated by human experts, and tested across 18 leading LMMs. We hope that A-Bench will significantly enhance the evaluation process and promote the generation quality for AIGIs. The benchmark is available at https://github.com/Q-Future/A-Bench.
Read more6/6/2024
🚀
0
GlitchBench: Can large multimodal models detect video game glitches?
Mohammad Reza Taesiri, Tianjun Feng, Anh Nguyen, Cor-Paul Bezemer
Large multimodal models (LMMs) have evolved from large language models (LLMs) to integrate multiple input modalities, such as visual inputs. This integration augments the capacity of LLMs for tasks requiring visual comprehension and reasoning. However, the extent and limitations of their enhanced abilities are not fully understood, especially when it comes to real-world tasks. To address this gap, we introduce GlitchBench, a novel benchmark derived from video game quality assurance tasks, to test and evaluate the reasoning capabilities of LMMs. Our benchmark is curated from a variety of unusual and glitched scenarios from video games and aims to challenge both the visual and linguistic reasoning powers of LMMs in detecting and interpreting out-of-the-ordinary events. We evaluate multiple state-of-the-art LMMs, and we show that GlitchBench presents a new challenge for these models. Code and data are available at: https://glitchbench.github.io/
Read more4/1/2024