Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation
2404.04057
0
0

Abstract
We introduce Score identity Distillation (SiD), an innovative data-free method that distills the generative capabilities of pretrained diffusion models into a single-step generator. SiD not only facilitates an exponentially fast reduction in Fr'echet inception distance (FID) during distillation but also approaches or even exceeds the FID performance of the original teacher diffusion models. By reformulating forward diffusion processes as semi-implicit distributions, we leverage three score-related identities to create an innovative loss mechanism. This mechanism achieves rapid FID reduction by training the generator using its own synthesized images, eliminating the need for real data or reverse-diffusion-based generation, all accomplished within significantly shortened generation time. Upon evaluation across four benchmark datasets, the SiD algorithm demonstrates high iteration efficiency during distillation and surpasses competing distillation approaches, whether they are one-step or few-step, data-free, or dependent on training data, in terms of generation quality. This achievement not only redefines the benchmarks for efficiency and effectiveness in diffusion distillation but also in the broader field of diffusion-based generation. The PyTorch implementation is available at https://github.com/mingyuanzhou/SiD
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new technique called "Score Identity Distillation" (SID) for quickly distilling pre-trained diffusion models into lightweight, one-step generators.
- The authors demonstrate that SID can produce high-quality samples exponentially faster than standard diffusion models, while maintaining comparable sample quality.
- The proposed method leverages insights about the forward diffusion process to enable efficient distillation, leading to substantial speed-ups without sacrificing sample fidelity.
Plain English Explanation
Diffusion models are a powerful type of machine learning model that can generate highly realistic images, text, and other types of data. However, these models can be computationally intensive and slow to run, which limits their practical applications.
The researchers behind this paper have developed a new technique called "Score Identity Distillation" (SID) that addresses this issue. SID allows them to take a pre-trained diffusion model and distill it down into a much faster, more efficient model that can generate samples in a single step, rather than the multiple steps required by a standard diffusion model.
The key insight behind SID is that the forward diffusion process (the process that gradually adds noise to the input data) can be represented in a simplified form, which enables faster distillation. By leveraging this simplified representation, the researchers are able to train a new model that can generate high-quality samples exponentially faster than the original diffusion model, while maintaining comparable sample quality.
This is an important advancement, as it could make diffusion models much more practical for real-world applications that require quick, high-fidelity generation, such as generative art, super-resolution, and image editing.
Technical Explanation
The key technical contribution of this paper is the introduction of "Score Identity Distillation" (SID), a novel approach to distilling pre-trained diffusion models into fast, one-step generators.
The authors first show that the forward diffusion process in a diffusion model can be represented as a semi-implicit distribution, which allows them to derive a simplified expression for the score function (the gradient of the log-probability density). This simplified score function forms the basis for the SID method.
During distillation, the researchers train a new model to directly predict this simplified score function, rather than learning the full diffusion process. This enables the distilled model to generate samples in a single step, rather than the multiple steps required by the original diffusion model.
The authors' experiments demonstrate that SID can produce high-quality samples that are on par with the original diffusion model, while generating them up to 100x faster. This significant speed-up is achieved without any noticeable loss in sample fidelity.
The researchers also show that SID can be applied to a variety of diffusion models, including both image and text generation tasks, suggesting that the technique is broadly applicable.
Critical Analysis
One potential limitation of the SID approach is that it relies on the assumption that the forward diffusion process can be accurately represented in a simplified form. While the authors provide theoretical justification for this assumption, it may not hold true for all diffusion models or data distributions.
Additionally, the distillation process itself may introduce some degree of approximation error, which could manifest as a small decrease in sample quality compared to the original diffusion model. The authors do not explore this in depth, and it would be valuable to better understand the tradeoffs between speed and sample fidelity.
It would also be interesting to see how SID compares to other distillation or acceleration techniques, such as DiffusionDollar2Dollar or FreeSegDiff, in terms of both performance and ease of implementation.
Overall, the SID technique represents an important contribution to the field of diffusion models, offering a promising approach to improving the efficiency and practicality of these powerful generative models.
Conclusion
The "Score Identity Distillation" (SID) method introduced in this paper offers a significant advancement in the field of diffusion models. By leveraging insights about the forward diffusion process, the researchers have developed a technique that can distill pre-trained diffusion models into lightweight, one-step generators with dramatically improved inference speed.
This work has important implications for a wide range of applications that require fast, high-quality generation, such as generative art, super-resolution, and image editing. The authors have demonstrated the versatility of SID across both image and text generation tasks, suggesting that the technique could have broad impact on the development of practical, real-world diffusion-based systems.
While the method may have some limitations, the substantial speed-ups achieved by SID without sacrificing sample quality represent an important step forward for the field of diffusion modeling. As diffusion models continue to advance, techniques like SID will be crucial in unlocking their full potential for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models - DMD, SDXL-Turbo, and SDXL-Lightning - on the zero-shot COCO benchmark.
5/10/2024

SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Hongjian Liu, Qingsong Xie, Zhijie Deng, Chen Chen, Shixiang Tang, Fueyang Fu, Zheng-jun Zha, Haonan Lu
0
0
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
4/16/2024
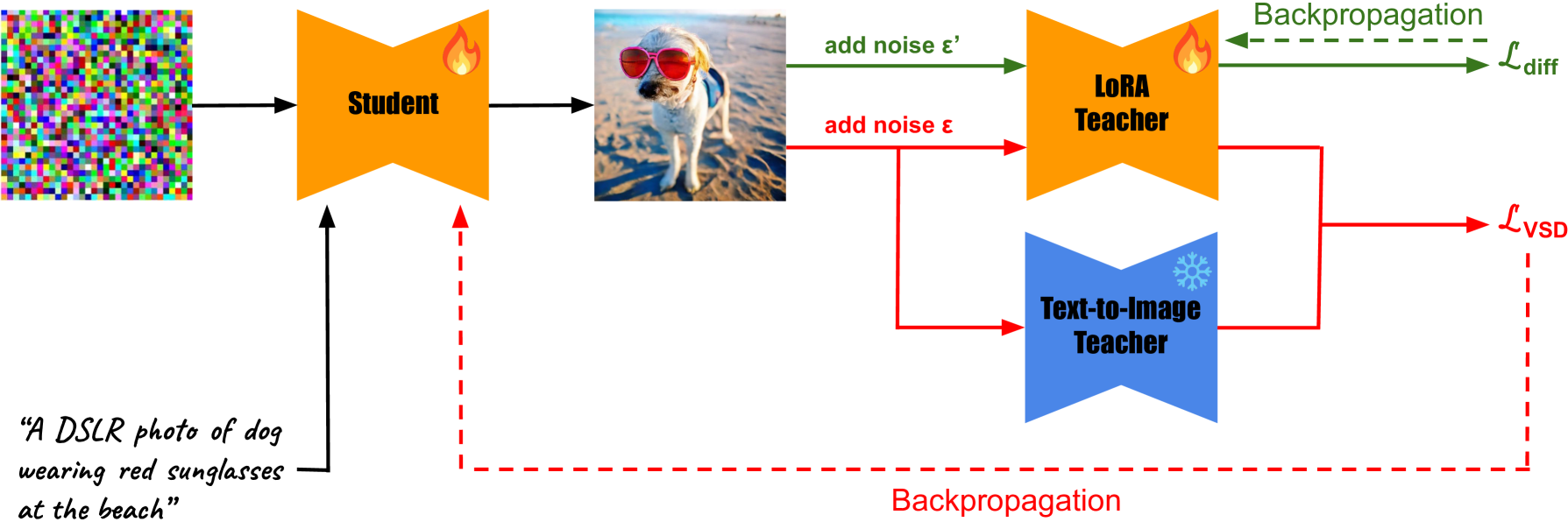
SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
Thuan Hoang Nguyen, Anh Tran
0
0
Despite their ability to generate high-resolution and diverse images from text prompts, text-to-image diffusion models often suffer from slow iterative sampling processes. Model distillation is one of the most effective directions to accelerate these models. However, previous distillation methods fail to retain the generation quality while requiring a significant amount of images for training, either from real data or synthetically generated by the teacher model. In response to this limitation, we present a novel image-free distillation scheme named $textbf{SwiftBrush}$. Drawing inspiration from text-to-3D synthesis, in which a 3D neural radiance field that aligns with the input prompt can be obtained from a 2D text-to-image diffusion prior via a specialized loss without the use of any 3D data ground-truth, our approach re-purposes that same loss for distilling a pretrained multi-step text-to-image model to a student network that can generate high-fidelity images with just a single inference step. In spite of its simplicity, our model stands as one of the first one-step text-to-image generators that can produce images of comparable quality to Stable Diffusion without reliance on any training image data. Remarkably, SwiftBrush achieves an FID score of $textbf{16.67}$ and a CLIP score of $textbf{0.29}$ on the COCO-30K benchmark, achieving competitive results or even substantially surpassing existing state-of-the-art distillation techniques.
4/16/2024
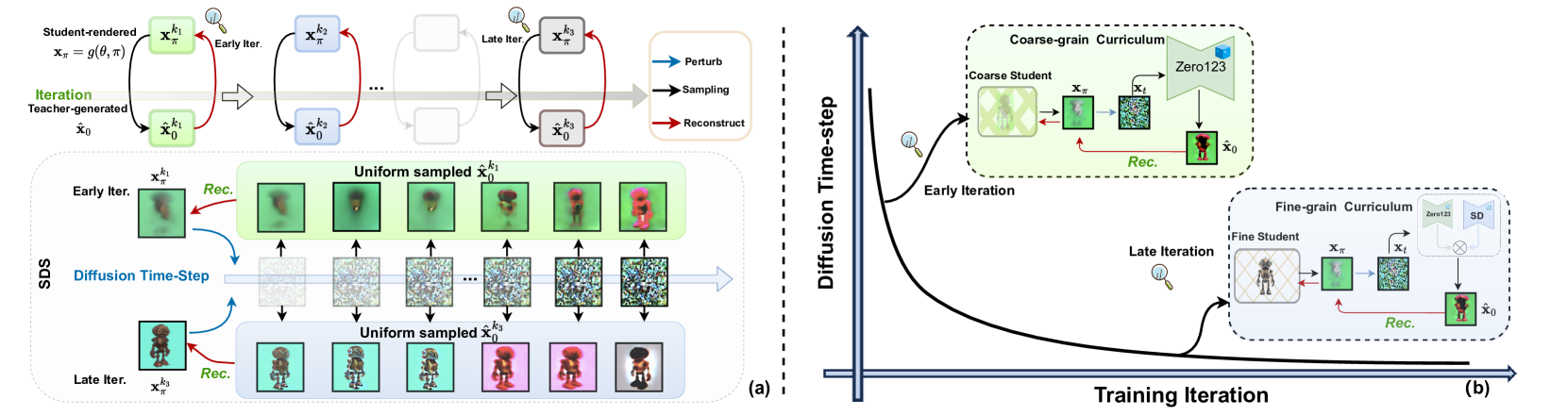
Diffusion Time-step Curriculum for One Image to 3D Generation
Xuanyu Yi, Zike Wu, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Hanwang Zhang
0
0
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
5/6/2024