SDFR: Synthetic Data for Face Recognition Competition

0

Sign in to get full access
Overview
- The paper describes a competition called "Synthetic Data for Face Recognition (SDFR)" that aims to advance the development of face recognition systems using synthetic data.
- The competition tasks include face recognition, face verification, and face detection using synthetic face images.
- The goal is to promote research on using synthetic data to improve the robustness and fairness of face recognition systems.
Plain English Explanation
The "Synthetic Data for Face Recognition (SDFR)" competition is an effort to advance the development of face recognition systems. Face recognition is a technology that can automatically identify or verify a person's identity from a digital image or video frame.
Traditionally, face recognition systems have been trained on real-world photos of people's faces. However, collecting and annotating large datasets of real faces can be challenging. This is where synthetic data comes in. Synthetic data refers to computer-generated images that are designed to mimic real-world data.
The SDFR competition aims to encourage researchers to explore the use of synthetic face images to improve the performance and fairness of face recognition systems. The competition tasks include face recognition, face verification, and face detection using these synthetic face images.
The goal is to see if synthetic data can be used effectively to train more robust and unbiased face recognition models, which could have important implications for various applications of this technology.
Technical Explanation
The "Synthetic Data for Face Recognition (SDFR)" competition is designed to advance research on using synthetic data to improve face recognition systems. The competition includes three main tasks:
-
Face Recognition: Participants must develop models that can accurately identify the identity of a person from a synthetic face image.
-
Face Verification: Participants must create models that can determine whether two synthetic face images belong to the same person.
-
Face Detection: Participants must build models that can accurately locate and detect faces within synthetic face images.
The goal of the competition is to promote the development of face recognition systems that are more robust and fair by leveraging the use of synthetic data. Synthetic data refers to computer-generated images that are designed to mimic real-world data, in this case, face images.
Using synthetic data has several potential advantages over relying solely on real-world face datasets. First, synthetic data can be generated in large quantities and with precise annotations, which can be challenging and expensive to obtain with real-world data. Second, synthetic data can be customized to address specific biases or gaps in real-world face datasets, potentially leading to more unbiased and fairer face recognition models.
By encouraging researchers to leverage synthetic face images in the development of face recognition systems, the SDFR competition aims to advance the field and explore the potential benefits of using synthetic data for this important application.
Critical Analysis
The SDFR competition presents an interesting approach to addressing some of the challenges associated with training face recognition systems. By focusing on the use of synthetic data, the competition organizers are attempting to capitalize on the potential advantages of computer-generated face images, such as the ability to create large and diverse datasets with precise annotations.
However, it is important to note that the effectiveness of synthetic data for training face recognition models is still an active area of research. While some studies have shown promising results, there may be potential limitations or biases that need to be carefully considered when relying on synthetic data.
Additionally, the competition tasks, while relevant, may not fully capture the complexity of real-world face recognition scenarios. For example, the competition does not address the challenge of adapting face recognition models to different environments or domains, which can be a significant hurdle in practical applications.
Further research is needed to thoroughly evaluate the long-term effectiveness and generalizability of face recognition models trained on synthetic data. Careful consideration should also be given to the potential ethical and societal implications of deploying such systems, particularly in sensitive applications.
Conclusion
The "Synthetic Data for Face Recognition (SDFR)" competition represents an innovative approach to advancing the development of face recognition systems. By focusing on the use of synthetic data, the competition aims to address some of the challenges associated with real-world face datasets and promote the creation of more robust and fair face recognition models.
While the potential benefits of synthetic data are promising, further research is needed to fully understand the long-term implications and limitations of this approach. Careful consideration of ethical and societal concerns should also be a priority as the field of face recognition continues to evolve.
Overall, the SDFR competition provides a valuable platform for researchers to explore new frontiers in the use of synthetic data for improving face recognition technology, with the ultimate goal of developing systems that are more accurate, unbiased, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SDFR: Synthetic Data for Face Recognition Competition
Hatef Otroshi Shahreza, Christophe Ecabert, Anjith George, Alexander Unnervik, S'ebastien Marcel, Nicol`o Di Domenico, Guido Borghi, Davide Maltoni, Fadi Boutros, Julia Vogel, Naser Damer, 'Angela S'anchez-P'erez, EnriqueMas-Candela, Jorge Calvo-Zaragoza, Bernardo Biesseck, Pedro Vidal, Roger Granada, David Menotti, Ivan DeAndres-Tame, Simone Maurizio La Cava, Sara Concas, Pietro Melzi, Ruben Tolosana, Ruben Vera-Rodriguez, Gianpaolo Perelli, Giulia Orr`u, Gian Luca Marcialis, Julian Fierrez
Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Read more4/10/2024

0
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Ivan DeAndres-Tame, Ruben Tolosana, Pietro Melzi, Ruben Vera-Rodriguez, Minchul Kim, Christian Rathgeb, Xiaoming Liu, Aythami Morales, Julian Fierrez, Javier Ortega-Garcia, Zhizhou Zhong, Yuge Huang, Yuxi Mi, Shouhong Ding, Shuigeng Zhou, Shuai He, Lingzhi Fu, Heng Cong, Rongyu Zhang, Zhihong Xiao, Evgeny Smirnov, Anton Pimenov, Aleksei Grigorev, Denis Timoshenko, Kaleb Mesfin Asfaw, Cheng Yaw Low, Hao Liu, Chuyi Wang, Qing Zuo, Zhixiang He, Hatef Otroshi Shahreza, Anjith George, Alexander Unnervik, Parsa Rahimi, S'ebastien Marcel, Pedro C. Neto, Marco Huber, Jan Niklas Kolf, Naser Damer, Fadi Boutros, Jaime S. Cardoso, Ana F. Sequeira, Andrea Atzori, Gianni Fenu, Mirko Marras, Vitomir v{S}truc, Jiang Yu, Zhangjie Li, Jichun Li, Weisong Zhao, Zhen Lei, Xiangyu Zhu, Xiao-Yu Zhang, Bernardo Biesseck, Pedro Vidal, Luiz Coelho, Roger Granada, David Menotti
Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
Read more4/17/2024
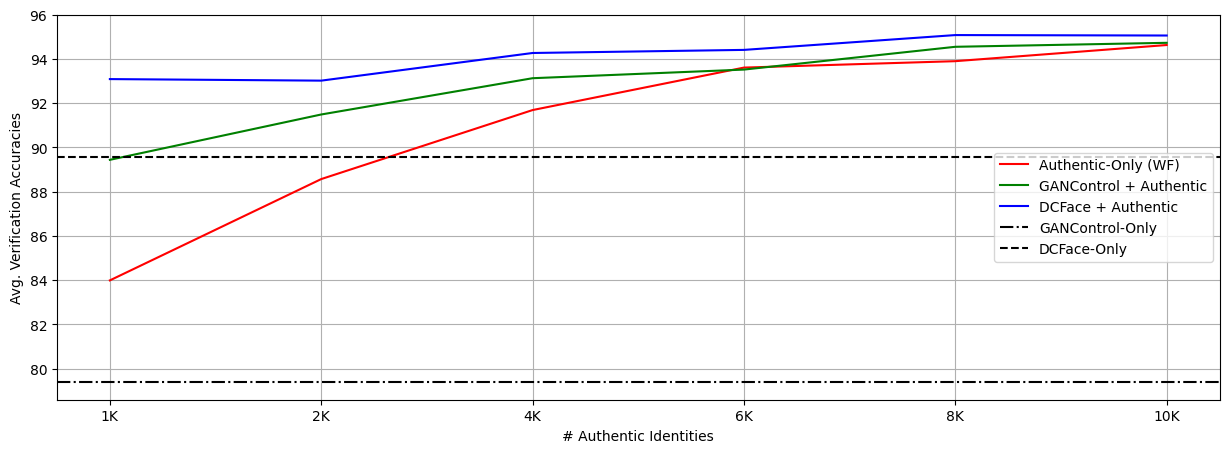
0
If It's Not Enough, Make It So: Reducing Authentic Data Demand in Face Recognition through Synthetic Faces
Andrea Atzori, Fadi Boutros, Naser Damer, Gianni Fenu, Mirko Marras
Recent advances in deep face recognition have spurred a growing demand for large, diverse, and manually annotated face datasets. Acquiring authentic, high-quality data for face recognition has proven to be a challenge, primarily due to privacy concerns. Large face datasets are primarily sourced from web-based images, lacking explicit user consent. In this paper, we examine whether and how synthetic face data can be used to train effective face recognition models with reduced reliance on authentic images, thereby mitigating data collection concerns. First, we explored the performance gap among recent state-of-the-art face recognition models, trained with synthetic data only and authentic (scarce) data only. Then, we deepened our analysis by training a state-of-the-art backbone with various combinations of synthetic and authentic data, gaining insights into optimizing the limited use of the latter for verification accuracy. Finally, we assessed the effectiveness of data augmentation approaches on synthetic and authentic data, with the same goal in mind. Our results highlighted the effectiveness of FR trained on combined datasets, particularly when combined with appropriate augmentation techniques.
Read more4/29/2024
🛸
0
Synthetic Face Datasets Generation via Latent Space Exploration from Brownian Identity Diffusion
David Geissbuhler, Hatef Otroshi Shahreza, S'ebastien Marcel
Face Recognition (FR) models are trained on large-scale datasets, which have privacy and ethical concerns. Lately, the use of synthetic data to complement or replace genuine data for the training of FR models has been proposed. While promising results have been obtained, it still remains unclear if generative models can yield diverse enough data for such tasks. In this work, we introduce a new method, inspired by the physical motion of soft particles subjected to stochastic Brownian forces, allowing us to sample identities distributions in a latent space under various constraints. With this in hands, we generate several face datasets and benchmark them by training FR models, showing that data generated with our method exceeds the performance of previously GAN-based datasets and achieves competitive performance with state-of-the-art diffusion-based synthetic datasets. We also show that this method can be used to mitigate leakage from the generator's training set and explore the ability of generative models to generate data beyond it.
Read more5/2/2024