PrivImage: Differentially Private Synthetic Image Generation using Diffusion Models with Semantic-Aware Pretraining
2311.12850
0
0
🖼️
Abstract
Differential Privacy (DP) image data synthesis, which leverages the DP technique to generate synthetic data to replace the sensitive data, allowing organizations to share and utilize synthetic images without privacy concerns. Previous methods incorporate the advanced techniques of generative models and pre-training on a public dataset to produce exceptional DP image data, but suffer from problems of unstable training and massive computational resource demands. This paper proposes a novel DP image synthesis method, termed PRIVIMAGE, which meticulously selects pre-training data, promoting the efficient creation of DP datasets with high fidelity and utility. PRIVIMAGE first establishes a semantic query function using a public dataset. Then, this function assists in querying the semantic distribution of the sensitive dataset, facilitating the selection of data from the public dataset with analogous semantics for pre-training. Finally, we pre-train an image generative model using the selected data and then fine-tune this model on the sensitive dataset using Differentially Private Stochastic Gradient Descent (DP-SGD). PRIVIMAGE allows us to train a lightly parameterized generative model, reducing the noise in the gradient during DP-SGD training and enhancing training stability. Extensive experiments demonstrate that PRIVIMAGE uses only 1% of the public dataset for pre-training and 7.6% of the parameters in the generative model compared to the state-of-the-art method, whereas achieves superior synthetic performance and conserves more computational resources. On average, PRIVIMAGE achieves 30.1% lower FID and 12.6% higher Classification Accuracy than the state-of-the-art method. The replication package and datasets can be accessed online.
Create account to get full access
Overview
- This paper proposes a novel method called PRIVIMAGE for differentially private (DP) image data synthesis.
- DP is a technique to generate synthetic data that can replace sensitive data, allowing organizations to share and use the synthetic data without privacy concerns.
- Previous methods have had issues with unstable training and high computational resource demands.
- PRIVIMAGE addresses these challenges by carefully selecting pre-training data to improve the efficiency and performance of DP image synthesis.
Plain English Explanation
Differential Privacy (DP) for Image Data DP image data synthesis is a way to create fake image data that can be used instead of real, sensitive image data. This allows organizations to share and use the synthetic data without worrying about people's privacy being violated.
Previous Challenges Previous methods that used advanced techniques like generative models and pre-training have produced high-quality synthetic data. However, they have faced problems with the training process being unstable and requiring massive computational resources.
PRIVIMAGE Approach PRIVIMAGE aims to address these challenges by carefully selecting the pre-training data. It first uses a public dataset to establish a way to understand the semantic, or meaning-based, distribution of the sensitive dataset. It then selects similar data from the public dataset to pre-train the image generation model.
This pre-training process allows PRIVIMAGE to use a smaller, more lightweight generation model, which reduces the amount of noise needed during the final DP training. This makes the training more stable and efficient, requiring fewer computational resources.
Technical Explanation
PRIVIMAGE starts by establishing a "semantic query function" using a public dataset. This function helps the method understand the semantic distribution of the sensitive dataset that needs to be protected. PRIVIMAGE then uses this function to select data from the public dataset that has similar semantics to the sensitive dataset.
The method then pre-trains an image generation model using this selected public data. This pre-trained model is then fine-tuned on the sensitive dataset using Differentially Private Stochastic Gradient Descent (DP-SGD).
The key innovation of PRIVIMAGE is that it can use a smaller, more lightweight generation model compared to previous state-of-the-art methods. This is because the careful pre-training data selection allows the model to capture the necessary semantics with fewer parameters. As a result, there is less noise introduced during the DP-SGD fine-tuning process, leading to more stable training and better synthetic performance.
Critical Analysis
The paper provides a thorough evaluation of PRIVIMAGE, demonstrating its efficiency and effectiveness compared to prior work. However, the authors acknowledge that the method still requires access to a public dataset that is semantically similar to the sensitive dataset. In some cases, finding such a public dataset may be challenging.
Additionally, the paper does not address the potential for biases or skewed representation in the synthetic data produced by PRIVIMAGE, which is an important consideration for real-world applications. Further research may be needed to stress test the models and ensure the synthetic data is representative and unbiased.
Conclusion
The PRIVIMAGE method presented in this paper offers a promising approach to differentially private image data synthesis. By carefully selecting pre-training data, the method can generate high-quality synthetic images while using fewer computational resources and achieving more stable training than previous state-of-the-art techniques. This advance could make DP-based data sharing more practical and accessible for organizations that need to protect sensitive image data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Differentially Private Fine-Tuning of Diffusion Models
Yu-Lin Tsai, Yizhe Li, Zekai Chen, Po-Yu Chen, Chia-Mu Yu, Xuebin Ren, Francois Buet-Golfouse
0
0
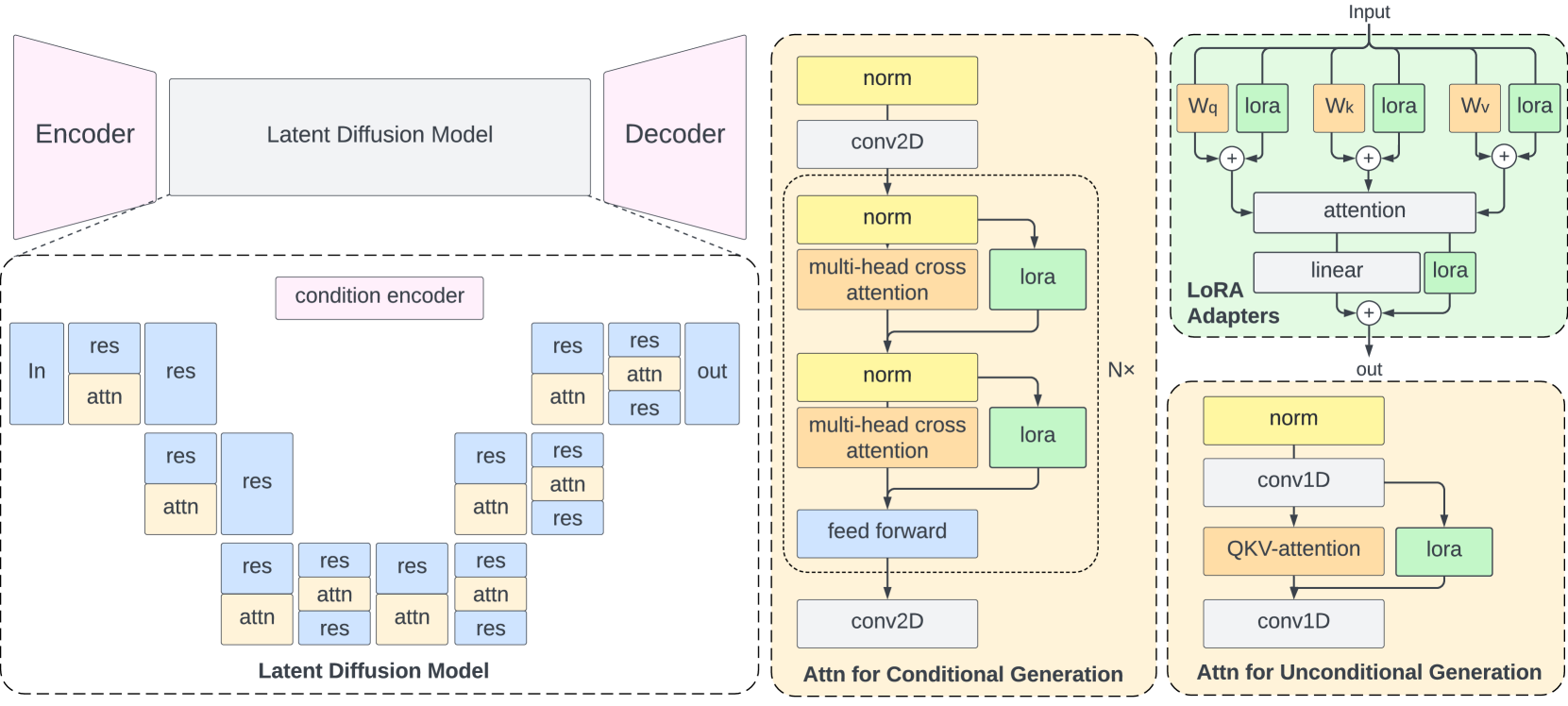
The integration of Differential Privacy (DP) with diffusion models (DMs) presents a promising yet challenging frontier, particularly due to the substantial memorization capabilities of DMs that pose significant privacy risks. Differential privacy offers a rigorous framework for safeguarding individual data points during model training, with Differential Privacy Stochastic Gradient Descent (DP-SGD) being a prominent implementation. Diffusion method decomposes image generation into iterative steps, theoretically aligning well with DP's incremental noise addition. Despite the natural fit, the unique architecture of DMs necessitates tailored approaches to effectively balance privacy-utility trade-off. Recent developments in this field have highlighted the potential for generating high-quality synthetic data by pre-training on public data (i.e., ImageNet) and fine-tuning on private data, however, there is a pronounced gap in research on optimizing the trade-offs involved in DP settings, particularly concerning parameter efficiency and model scalability. Our work addresses this by proposing a parameter-efficient fine-tuning strategy optimized for private diffusion models, which minimizes the number of trainable parameters to enhance the privacy-utility trade-off. We empirically demonstrate that our method achieves state-of-the-art performance in DP synthesis, significantly surpassing previous benchmarks on widely studied datasets (e.g., with only 0.47M trainable parameters, achieving a more than 35% improvement over the previous state-of-the-art with a small privacy budget on the CelebA-64 dataset). Anonymous codes available at https://anonymous.4open.science/r/DP-LORA-F02F.
6/4/2024
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Jonathan Lebensold, Maziar Sanjabi, Pietro Astolfi, Adriana Romero-Soriano, Kamalika Chaudhuri, Mike Rabbat, Chuan Guo
0
0
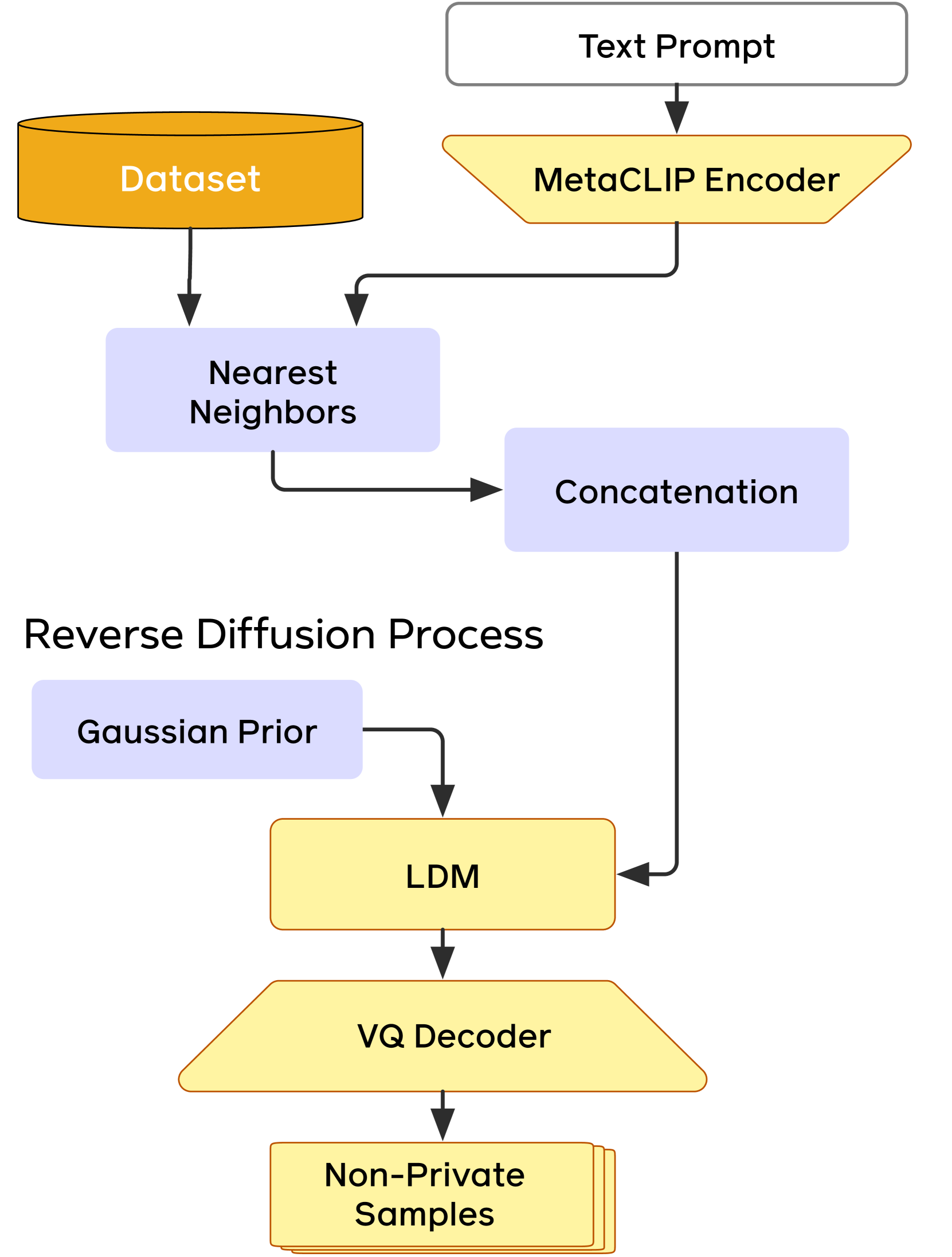
Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
5/14/2024
PATE-TripleGAN: Privacy-Preserving Image Synthesis with Gaussian Differential Privacy
Zepeng Jiang, Weiwei Ni, Yifan Zhang
0
0
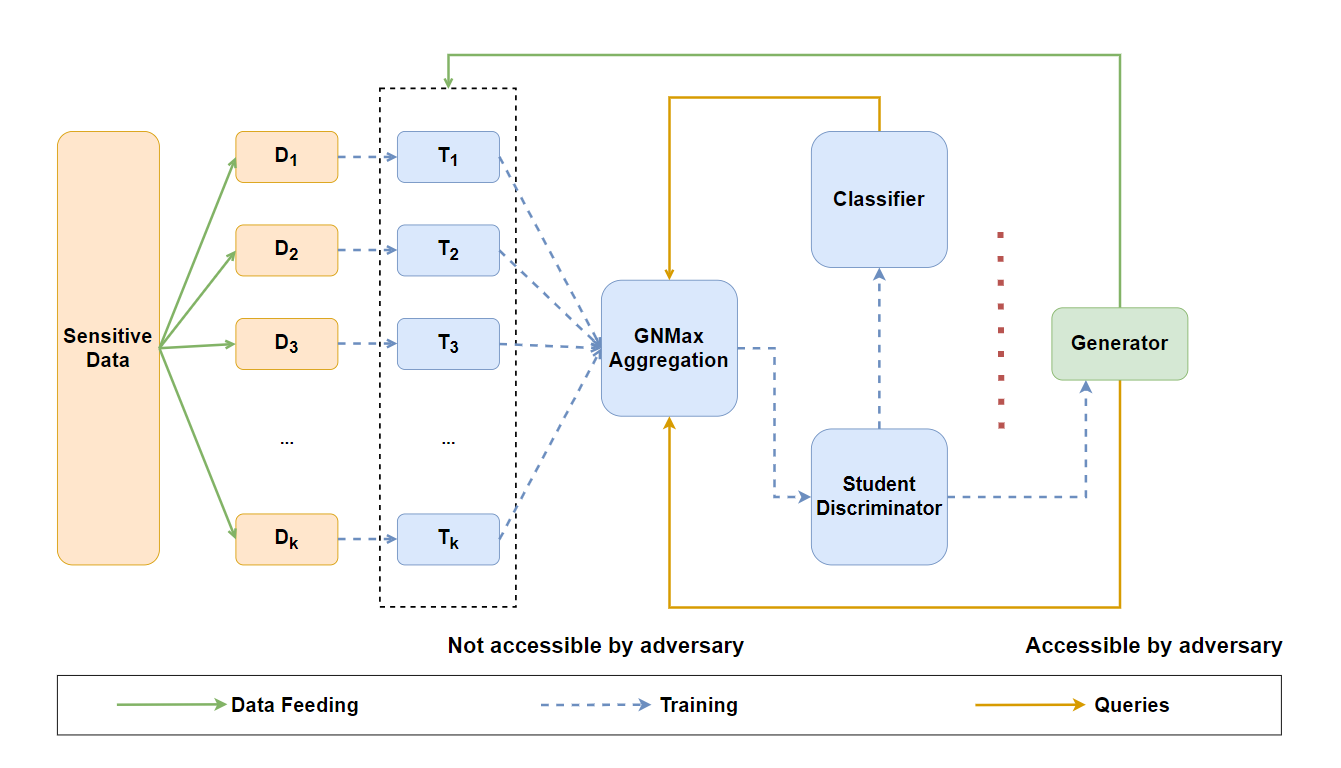
Conditional Generative Adversarial Networks (CGANs) exhibit significant potential in supervised learning model training by virtue of their ability to generate realistic labeled images. However, numerous studies have indicated the privacy leakage risk in CGANs models. The solution DPCGAN, incorporating the differential privacy framework, faces challenges such as heavy reliance on labeled data for model training and potential disruptions to original gradient information due to excessive gradient clipping, making it difficult to ensure model accuracy. To address these challenges, we present a privacy-preserving training framework called PATE-TripleGAN. This framework incorporates a classifier to pre-classify unlabeled data, establishing a three-party min-max game to reduce dependence on labeled data. Furthermore, we present a hybrid gradient desensitization algorithm based on the Private Aggregation of Teacher Ensembles (PATE) framework and Differential Private Stochastic Gradient Descent (DPSGD) method. This algorithm allows the model to retain gradient information more effectively while ensuring privacy protection, thereby enhancing the model's utility. Privacy analysis and extensive experiments affirm that the PATE-TripleGAN model can generate a higher quality labeled image dataset while ensuring the privacy of the training data.
4/22/2024
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
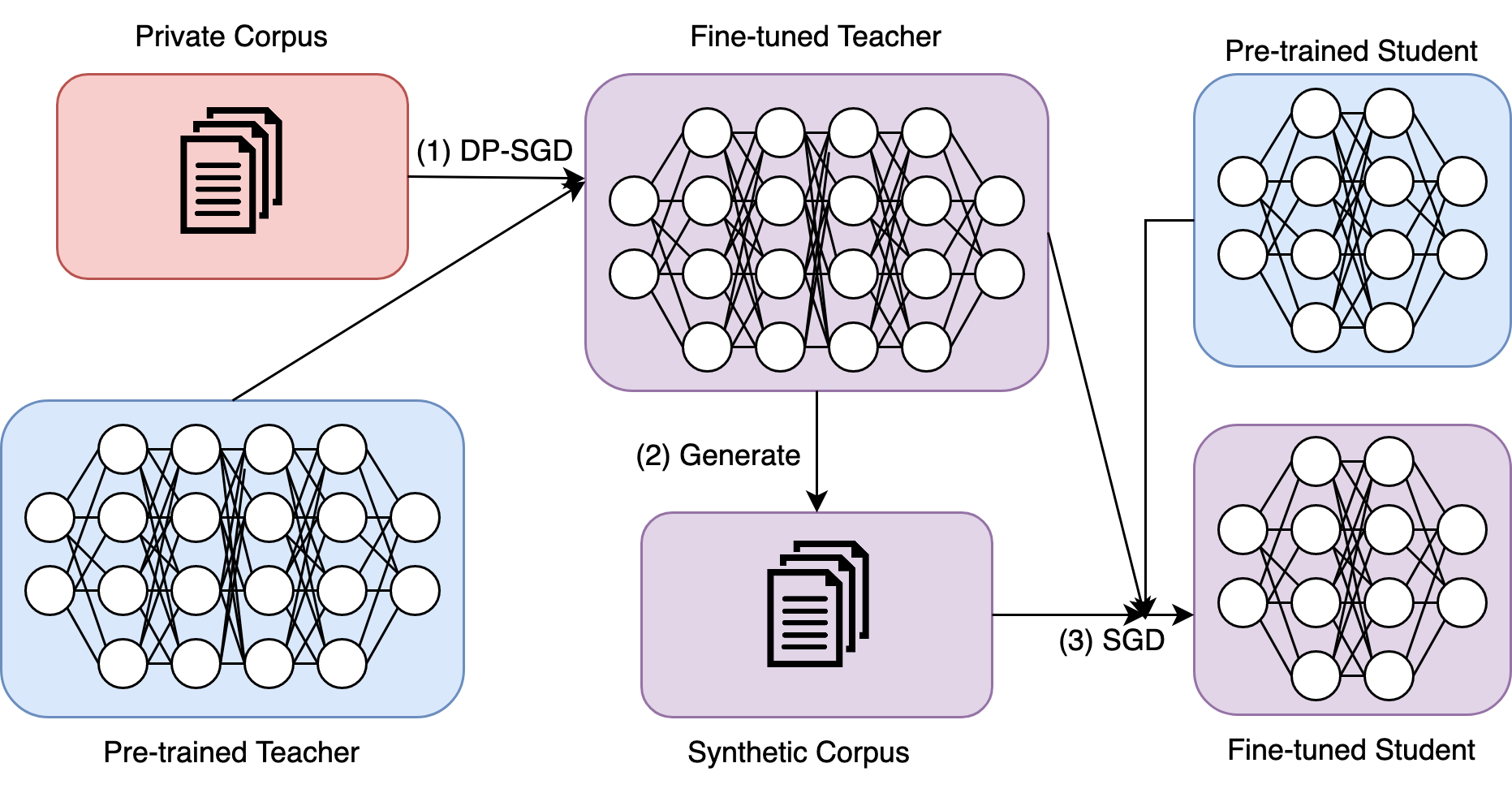
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024