SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration

0

Sign in to get full access
Overview
- The paper introduces SE3ET, a novel SE(3)-equivariant transformer architecture for low-overlap point cloud registration.
- SE3ET leverages symmetry properties to achieve improved performance on challenging point cloud registration tasks with low overlap between the input point clouds.
- The key innovations include SE(3)-equivariant self-attention and a new registration head that directly predicts the 6D rigid transformation.
Plain English Explanation
The paper presents a new AI model called SE3ET, which is designed to work with 3D point cloud data. Point clouds are collections of 3D points that represent the surface of an object or environment. Registration is the process of aligning two different point clouds so they match up.
SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration is particularly useful for situations where there is only a small amount of overlap between the two point clouds being registered. This can happen when capturing data from different viewpoints or at different times.
The key idea behind SE3ET is that it uses a special type of neural network layer called an "SE(3)-equivariant self-attention" module. This allows the model to be aware of the 3D rotations and translations of the point cloud data, which helps it better align the two point clouds even when there is little overlap.
SE3ET also has a novel "registration head" that directly predicts the 6 degrees of freedom (3 rotations, 3 translations) needed to align the two point clouds. This is more efficient than having the model first predict some intermediate representation and then converting that to the final alignment.
Overall, SE3ET represents an advance in point cloud registration technology, making it more robust to challenging real-world situations with limited overlap between the input data.
Technical Explanation
The core of SE3ET is an SE(3)-equivariant transformer architecture, which is designed to be invariant to the 3D rotations and translations of the input point cloud data. This is achieved through the use of SE(3)-equivariant self-attention layers that preserve the 3D symmetries of the point cloud.
The transformer encoder takes in the raw point cloud data and produces a set of point-wise feature embeddings. These embeddings are then fed into a novel registration head that directly predicts the 6D rigid transformation (3 rotations, 3 translations) needed to align the two point clouds. This avoids the need for an additional conversion step compared to approaches that first predict an intermediate representation.
The authors evaluate SE3ET on several standard point cloud registration benchmarks, including scenes with low overlap between the input clouds. They find that SE3ET outperforms previous state-of-the-art methods, demonstrating the benefits of the SE(3)-equivariant design and direct 6D transformation prediction.
Critical Analysis
The key strength of SE3ET is its ability to handle point cloud registration in challenging low-overlap scenarios, which is an important practical consideration. The use of SE(3)-equivariant self-attention is a well-motivated technical innovation that aligns with the underlying geometry of the problem.
However, the paper does not provide a detailed analysis of the registration performance on extremely low-overlap cases, where only a small fraction of the points overlap between the two clouds. It would be valuable to understand the limits of SE3ET's capabilities in these extreme situations.
Additionally, the authors do not compare SE3ET to other recent advances in point cloud registration, such as PointDiffFormer or L-PR, which may offer complementary strengths. A more comprehensive benchmarking against the latest methods would help better situate the contributions of SE3ET.
Overall, SE3ET represents an interesting and promising approach to the problem of low-overlap point cloud registration, but further research is needed to fully understand its capabilities and limitations.
Conclusion
The SE3ET model presented in this paper is a significant advancement in point cloud registration, particularly for scenarios with limited overlap between the input data. By leveraging SE(3)-equivariant self-attention and a novel registration head, SE3ET demonstrates improved performance over previous state-of-the-art methods.
This work highlights the value of incorporating the underlying geometric properties of point cloud data into the neural network architecture. The SE(3)-equivariant design allows SE3ET to be more robust to the 3D transformations commonly encountered in real-world point cloud registration tasks.
As 3D sensing technologies continue to advance, the ability to accurately and efficiently register point clouds will become increasingly important for a wide range of applications, from robotics and autonomous vehicles to augmented reality and digital twinning. The innovations introduced by SE3ET represent an important step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SE3ET: SE(3)-Equivariant Transformer for Low-Overlap Point Cloud Registration
Chien Erh Lin, Minghan Zhu, Maani Ghaffari
Partial point cloud registration is a challenging problem in robotics, especially when the robot undergoes a large transformation, causing a significant initial pose error and a low overlap between measurements. This work proposes exploiting equivariant learning from 3D point clouds to improve registration robustness. We propose SE3ET, an SE(3)-equivariant registration framework that employs equivariant point convolution and equivariant transformer designs to learn expressive and robust geometric features. We tested the proposed registration method on indoor and outdoor benchmarks where the point clouds are under arbitrary transformations and low overlapping ratios. We also provide generalization tests and run-time performance.
Read more7/25/2024

0
SE(3)-bi-equivariant Transformers for Point Cloud Assembly
Ziming Wang, Rebecka Jornsten
Given a pair of point clouds, the goal of assembly is to recover a rigid transformation that aligns one point cloud to the other. This task is challenging because the point clouds may be non-overlapped, and they may have arbitrary initial positions. To address these difficulties, we propose a method, called SE(3)-bi-equivariant transformer (BITR), based on the SE(3)-bi-equivariance prior of the task: it guarantees that when the inputs are rigidly perturbed, the output will transform accordingly. Due to its equivariance property, BITR can not only handle non-overlapped PCs, but also guarantee robustness against initial positions. Specifically, BITR first extracts features of the inputs using a novel $SE(3) times SE(3)$-transformer, and then projects the learned feature to group SE(3) as the output. Moreover, we theoretically show that swap and scale equivariances can be incorporated into BITR, thus it further guarantees stable performance under scaling and swapping the inputs. We experimentally show the effectiveness of BITR in practical tasks.
Read more7/23/2024
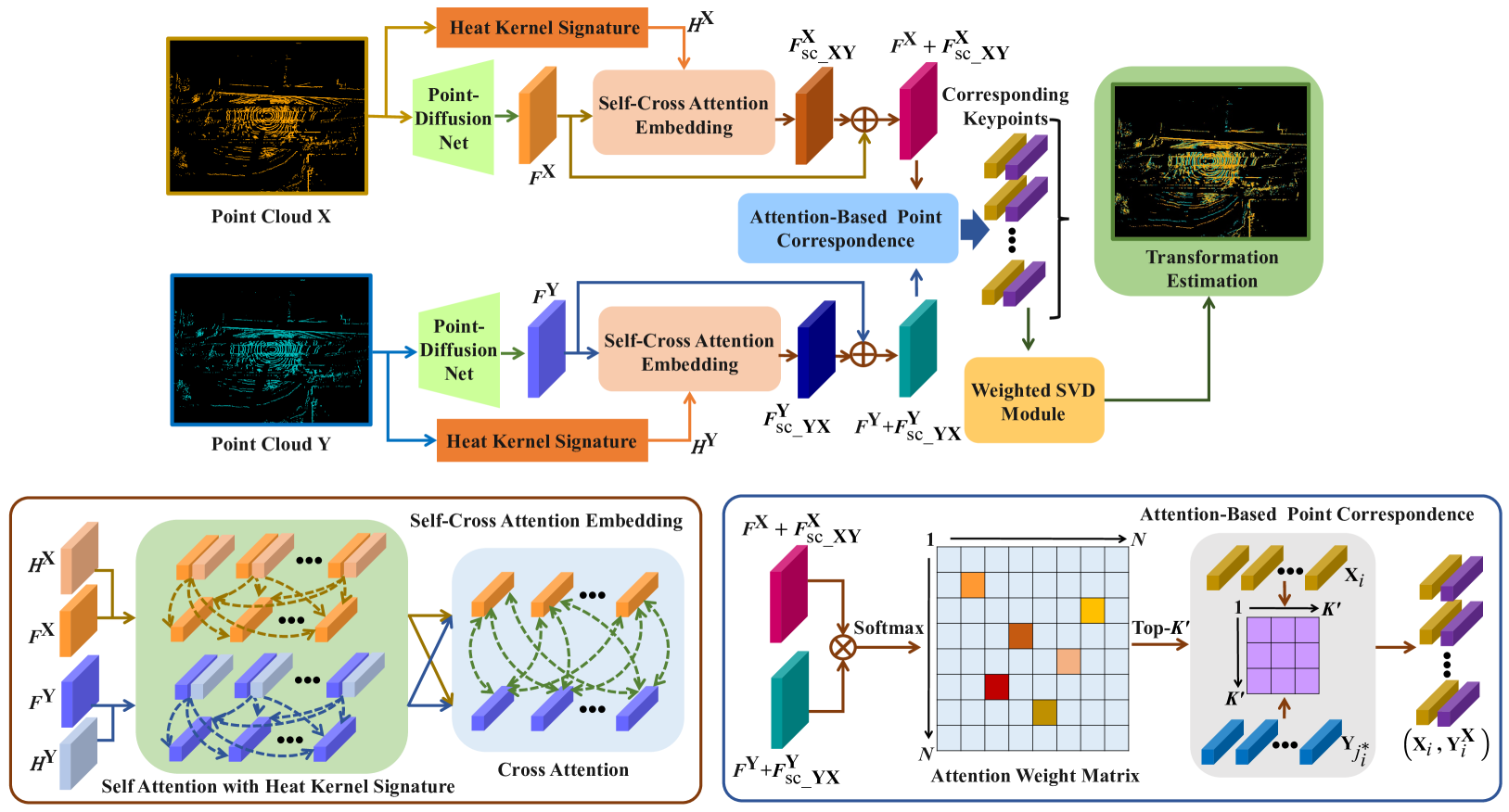
0
PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer
Rui She, Qiyu Kang, Sijie Wang, Wee Peng Tay, Kai Zhao, Yang Song, Tianyu Geng, Yi Xu, Diego Navarro Navarro, Andreas Hartmannsgruber
Point cloud registration is a fundamental technique in 3-D computer vision with applications in graphics, autonomous driving, and robotics. However, registration tasks under challenging conditions, under which noise or perturbations are prevalent, can be difficult. We propose a robust point cloud registration approach that leverages graph neural partial differential equations (PDEs) and heat kernel signatures. Our method first uses graph neural PDE modules to extract high dimensional features from point clouds by aggregating information from the 3-D point neighborhood, thereby enhancing the robustness of the feature representations. Then, we incorporate heat kernel signatures into an attention mechanism to efficiently obtain corresponding keypoints. Finally, a singular value decomposition (SVD) module with learnable weights is used to predict the transformation between two point clouds. Empirical experiments on a 3-D point cloud dataset demonstrate that our approach not only achieves state-of-the-art performance for point cloud registration but also exhibits better robustness to additive noise or 3-D shape perturbations.
Read more4/23/2024

0
Correspondence-Free SE(3) Point Cloud Registration in RKHS via Unsupervised Equivariant Learning
Ray Zhang, Zheming Zhou, Min Sun, Omid Ghasemalizadeh, Cheng-Hao Kuo, Ryan Eustice, Maani Ghaffari, Arnie Sen
This paper introduces a robust unsupervised SE(3) point cloud registration method that operates without requiring point correspondences. The method frames point clouds as functions in a reproducing kernel Hilbert space (RKHS), leveraging SE(3)-equivariant features for direct feature space registration. A novel RKHS distance metric is proposed, offering reliable performance amidst noise, outliers, and asymmetrical data. An unsupervised training approach is introduced to effectively handle limited ground truth data, facilitating adaptation to real datasets. The proposed method outperforms classical and supervised methods in terms of registration accuracy on both synthetic (ModelNet40) and real-world (ETH3D) noisy, outlier-rich datasets. To our best knowledge, this marks the first instance of successful real RGB-D odometry data registration using an equivariant method. The code is available at {https://sites.google.com/view/eccv24-equivalign}
Read more7/30/2024