Search3D: Hierarchical Open-Vocabulary 3D Segmentation

0
🌀
Sign in to get full access
Overview
- This paper introduces Search3D, a method for open-vocabulary 3D scene segmentation.
- Existing approaches focus on object-level instance segmentation, but struggle with fine-grained entities like object parts or regions described by attributes.
- Search3D builds a hierarchical open-vocabulary 3D scene representation to enable searching for entities at varying levels of granularity.
- The authors also contribute a 3D part segmentation benchmark and fine-grained part annotations to evaluate these capabilities.
Plain English Explanation
The paper is about a new way to interact with and explore 3D digital spaces using natural language descriptions. Open-vocabulary 3D segmentation allows users to search for and identify objects, parts, and regions in 3D scenes using free-form text.
Previous methods focused mainly on recognizing entire objects in a scene. Search3D takes this a step further by building a more detailed, hierarchical representation. This allows it to understand and locate more fine-grained elements, like individual parts of an object or regions with certain material properties.
To test this, the authors created a new 3D scene dataset and annotation benchmark. This provides a way to systematically evaluate how well different approaches can handle open-vocabulary 3D segmentation, especially for these more granular scene entities.
Overall, Search3D aims to make it easier for people to explore and interact with 3D spaces using natural language, going beyond just identifying full objects to understanding the detailed components that make up a scene.
Technical Explanation
Search3D builds a hierarchical open-vocabulary representation of 3D scenes. This allows it to segment and identify entities at different levels of granularity, from entire objects to specific object parts or regions described by attributes like material.
The model takes a 3D scene and a text query as input. It first encodes the 3D data using a set of neural networks. The text query is also encoded using language models. The 3D and text encodings are then matched to identify relevant entities in the scene.
Crucially, Search3D represents the scene in a hierarchical way, with progressively finer-grained elements. This allows it to handle queries about both whole objects and their individual components or characteristics.
To evaluate this, the authors introduce a new 3D part segmentation benchmark based on the MultiScan dataset, as well as fine-grained part annotations for ScanNet++. Experiments show that Search3D outperforms baselines on these tasks, while also maintaining strong performance on more traditional object-level instance segmentation.
Critical Analysis
The paper introduces an important advance in open-vocabulary 3D segmentation. By moving beyond just object-level recognition to a more detailed, hierarchical representation, Search3D enables more expressive and flexible interactions with 3D scenes.
However, the benchmarks and evaluations are still relatively narrow. The 3D part segmentation dataset is based on a single dataset (MultiScan), and the fine-grained ScanNet++ annotations may not generalize well. Expanding the diversity and scale of evaluation datasets would help better assess the broader capabilities of the approach.
Additionally, while Search3D outperforms baselines, the absolute performance numbers are still relatively low, especially for fine-grained part segmentation. Further improvements to the core algorithms may be needed to make this technology more robust and reliable.
Overall, the paper represents an important step forward, but there is still significant room for improvement and expansion to truly enable seamless open-vocabulary exploration of 3D spaces.
Conclusion
This paper introduces Search3D, a novel approach for open-vocabulary 3D scene segmentation. By building a hierarchical representation of 3D scenes, Search3D can identify entities at varying levels of granularity, from entire objects to individual parts and regions.
This expands on previous work in open-vocabulary 3D segmentation, which focused primarily on object-level recognition. Search3D aims to enable more flexible and natural interactions with 3D spaces using free-form text descriptions.
The authors also contribute new benchmarking datasets to systematically evaluate these open-vocabulary 3D segmentation capabilities. Experiments show that Search3D outperforms baselines, though there is still room for improvement, especially for fine-grained part segmentation.
Overall, this research represents an important step towards more intuitive and expressive ways of exploring and interacting with 3D digital environments using natural language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Search3D: Hierarchical Open-Vocabulary 3D Segmentation
Ayca Takmaz, Alexandros Delitzas, Robert W. Sumner, Francis Engelmann, Johanna Wald, Federico Tombari
Open-vocabulary 3D segmentation enables the exploration of 3D spaces using free-form text descriptions. Existing methods for open-vocabulary 3D instance segmentation primarily focus on identifying object-level instances in a scene. However, they face challenges when it comes to understanding more fine-grained scene entities such as object parts, or regions described by generic attributes. In this work, we introduce Search3D, an approach that builds a hierarchical open-vocabulary 3D scene representation, enabling the search for entities at varying levels of granularity: fine-grained object parts, entire objects, or regions described by attributes like materials. Our method aims to expand the capabilities of open vocabulary instance-level 3D segmentation by shifting towards a more flexible open-vocabulary 3D search setting less anchored to explicit object-centric queries, compared to prior work. To ensure a systematic evaluation, we also contribute a scene-scale open-vocabulary 3D part segmentation benchmark based on MultiScan, along with a set of open-vocabulary fine-grained part annotations on ScanNet++. We verify the effectiveness of Search3D across several tasks, demonstrating that our approach outperforms baselines in scene-scale open-vocabulary 3D part segmentation, while maintaining strong performance in segmenting 3D objects and materials.
Read more9/30/2024

0
Vocabulary-Free 3D Instance Segmentation with Vision and Language Assistant
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Most recent 3D instance segmentation methods are open vocabulary, offering a greater flexibility than closed-vocabulary methods. Yet, they are limited to reasoning within a specific set of concepts, ie the vocabulary, prompted by the user at test time. In essence, these models cannot reason in an open-ended fashion, i.e., answering ``List the objects in the scene.''. We introduce the first method to address 3D instance segmentation in a setting that is void of any vocabulary prior, namely a vocabulary-free setting. We leverage a large vision-language assistant and an open-vocabulary 2D instance segmenter to discover and ground semantic categories on the posed images. To form 3D instance mask, we first partition the input point cloud into dense superpoints, which are then merged into 3D instance masks. We propose a novel superpoint merging strategy via spectral clustering, accounting for both mask coherence and semantic coherence that are estimated from the 2D object instance masks. We evaluate our method using ScanNet200 and Replica, outperforming existing methods in both vocabulary-free and open-vocabulary settings. Code will be made available.
Read more8/21/2024
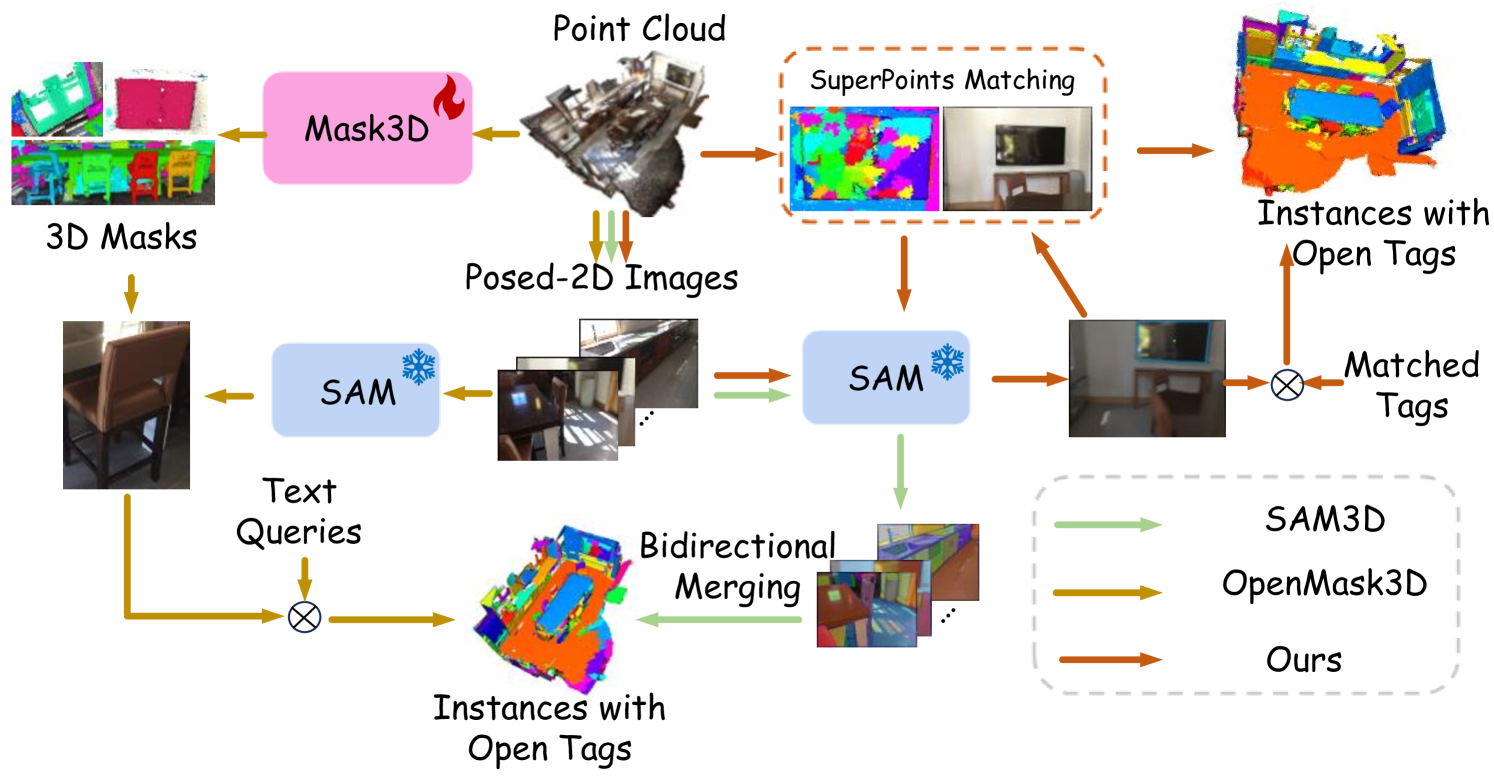
0
Open-Vocabulary SAM3D: Understand Any 3D Scene
Hanchen Tai, Qingdong He, Jiangning Zhang, Yijie Qian, Zhenyu Zhang, Xiaobin Hu, Xiangtai Li, Yabiao Wang, Yong Liu
Open-vocabulary 3D scene understanding presents a significant challenge in the field. Recent works have sought to transfer knowledge embedded in vision-language models from 2D to 3D domains. However, these approaches often require prior knowledge from specific 3D scene datasets, limiting their applicability in open-world scenarios. The Segment Anything Model (SAM) has demonstrated remarkable zero-shot segmentation capabilities, prompting us to investigate its potential for comprehending 3D scenes without training. In this paper, we introduce OV-SAM3D, a training-free method that contains a universal framework for understanding open-vocabulary 3D scenes. This framework is designed to perform understanding tasks for any 3D scene without requiring prior knowledge of the scene. Specifically, our method is composed of two key sub-modules: First, we initiate the process by generating superpoints as the initial 3D prompts and refine these prompts using segment masks derived from SAM. Moreover, we then integrate a specially designed overlapping score table with open tags from the Recognize Anything Model (RAM) to produce final 3D instances with open-world labels. Empirical evaluations on the ScanNet200 and nuScenes datasets demonstrate that our approach surpasses existing open-vocabulary methods in unknown open-world environments.
Read more9/6/2024

0
OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Youjun Zhao, Jiaying Lin, Shuquan Ye, Qianshi Pang, Rynson W. H. Lau
Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient to provide a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named OpenScan, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, material, and more. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark, and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed by simply scaling up object classes during training. We highlight the limitations of existing methodologies and explore a promising direction to overcome the identified shortcomings. Data and code are available at https://github.com/YoujunZhao/OpenScan
Read more8/21/2024