Vocabulary-Free 3D Instance Segmentation with Vision and Language Assistant

0

Sign in to get full access
Overview
- This paper presents a vocabulary-free 3D instance segmentation approach that leverages vision and language models.
- The method can identify and segment 3D objects without relying on predefined object categories or labels.
- It aims to enable more flexible and generalizable 3D scene understanding.
Plain English Explanation
This research paper describes a new way to automatically identify and segment individual 3D objects in a scene, without needing to know the specific names or categories of the objects ahead of time. Traditional 3D object segmentation approaches require pre-defined object classes or vocabularies, which limits their flexibility and ability to handle novel or unexpected objects.
The vocabulary-free 3D instance segmentation method proposed in this paper overcomes this limitation by combining computer vision and natural language processing techniques. It can recognize and segment 3D objects using just a text description, rather than relying on predefined object labels. This allows the system to work with a wide range of objects, including those it has not been explicitly trained on before.
By freeing the 3D segmentation process from the constraints of a fixed vocabulary, this approach aims to enable more flexible and generalizable 3D scene understanding that can adapt to diverse environments and applications.
Technical Explanation
The key innovation of this work is the vocabulary-free 3D instance segmentation approach, which combines a 3D segmentation network with a vision-language model.
The 3D segmentation network takes in 3D point cloud data and generates per-point instance segmentation, without any predefined object classes. The vision-language model, on the other hand, can map natural language descriptions to visual embeddings.
By aligning the outputs of these two models, the system can segment 3D objects based solely on text descriptions, rather than requiring pre-defined object labels. This allows the method to handle a much broader range of objects compared to traditional 3D segmentation techniques.
The authors evaluate their approach on several 3D object segmentation benchmarks, demonstrating its effectiveness in identifying and segmenting a variety of 3D objects without relying on a fixed vocabulary. The vocabulary-free 3D instance segmentation method outperforms prior state-of-the-art techniques that require predefined object classes.
Critical Analysis
The vocabulary-free 3D instance segmentation approach addresses an important limitation of traditional 3D object segmentation methods, which are constrained by the need for predefined object categories or vocabularies. By integrating vision and language models, this work enables more flexible and generalizable 3D scene understanding.
However, the paper does not fully explore the limitations of this approach. For example, it's unclear how the method would perform on highly cluttered or occluded scenes, where accurately associating text descriptions with specific 3D objects might be challenging. Additionally, the paper does not discuss the computational complexity or real-time performance of the proposed system, which could be important considerations for practical applications.
Further research could investigate ways to improve the robustness and efficiency of the vocabulary-free 3D instance segmentation approach, as well as exploring its potential applications in areas like robotics, augmented reality, and autonomous vehicles.
Conclusion
This paper presents a novel vocabulary-free 3D instance segmentation method that combines computer vision and natural language processing techniques. By aligning 3D segmentation with vision-language models, the approach can identify and segment 3D objects without relying on predefined object categories or labels.
This flexibility and generalizability could have significant implications for 3D scene understanding in a wide range of applications, enabling more adaptive and responsive systems that can handle diverse and unstructured environments. While the paper raises some questions about the approach's limitations, it represents an important step towards more advanced and versatile 3D perception capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vocabulary-Free 3D Instance Segmentation with Vision and Language Assistant
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Most recent 3D instance segmentation methods are open vocabulary, offering a greater flexibility than closed-vocabulary methods. Yet, they are limited to reasoning within a specific set of concepts, ie the vocabulary, prompted by the user at test time. In essence, these models cannot reason in an open-ended fashion, i.e., answering ``List the objects in the scene.''. We introduce the first method to address 3D instance segmentation in a setting that is void of any vocabulary prior, namely a vocabulary-free setting. We leverage a large vision-language assistant and an open-vocabulary 2D instance segmenter to discover and ground semantic categories on the posed images. To form 3D instance mask, we first partition the input point cloud into dense superpoints, which are then merged into 3D instance masks. We propose a novel superpoint merging strategy via spectral clustering, accounting for both mask coherence and semantic coherence that are estimated from the 2D object instance masks. We evaluate our method using ScanNet200 and Replica, outperforming existing methods in both vocabulary-free and open-vocabulary settings. Code will be made available.
Read more8/21/2024
💬
0
Segment Any 3D Object with Language
Seungjun Lee, Yuyang Zhao, Gim Hee Lee
In this paper, we investigate Open-Vocabulary 3D Instance Segmentation (OV-3DIS) with free-form language instructions. Earlier works that rely on only annotated base categories for training suffer from limited generalization to unseen novel categories. Recent works mitigate poor generalizability to novel categories by generating class-agnostic masks or projecting generalized masks from 2D to 3D, but disregard semantic or geometry information, leading to sub-optimal performance. Instead, generating generalizable but semantic-related masks directly from 3D point clouds would result in superior outcomes. In this paper, we introduce Segment any 3D Object with LanguagE (SOLE), which is a semantic and geometric-aware visual-language learning framework with strong generalizability by generating semantic-related masks directly from 3D point clouds. Specifically, we propose a multimodal fusion network to incorporate multimodal semantics in both backbone and decoder. In addition, to align the 3D segmentation model with various language instructions and enhance the mask quality, we introduce three types of multimodal associations as supervision. Our SOLE outperforms previous methods by a large margin on ScanNetv2, ScanNet200, and Replica benchmarks, and the results are even close to the fully-supervised counterpart despite the absence of class annotations in the training. Furthermore, extensive qualitative results demonstrate the versatility of our SOLE to language instructions.
Read more4/3/2024

0
Auto-Vocabulary Segmentation for LiDAR Points
Weijie Wei, Osman Ulger, Fatemeh Karimi Nejadasl, Theo Gevers, Martin R. Oswald
Existing perception methods for autonomous driving fall short of recognizing unknown entities not covered in the training data. Open-vocabulary methods offer promising capabilities in detecting any object but are limited by user-specified queries representing target classes. We propose AutoVoc3D, a framework for automatic object class recognition and open-ended segmentation. Evaluation on nuScenes showcases AutoVoc3D's ability to generate precise semantic classes and accurate point-wise segmentation. Moreover, we introduce Text-Point Semantic Similarity, a new metric to assess the semantic similarity between text and point cloud without eliminating novel classes.
Read more7/26/2024
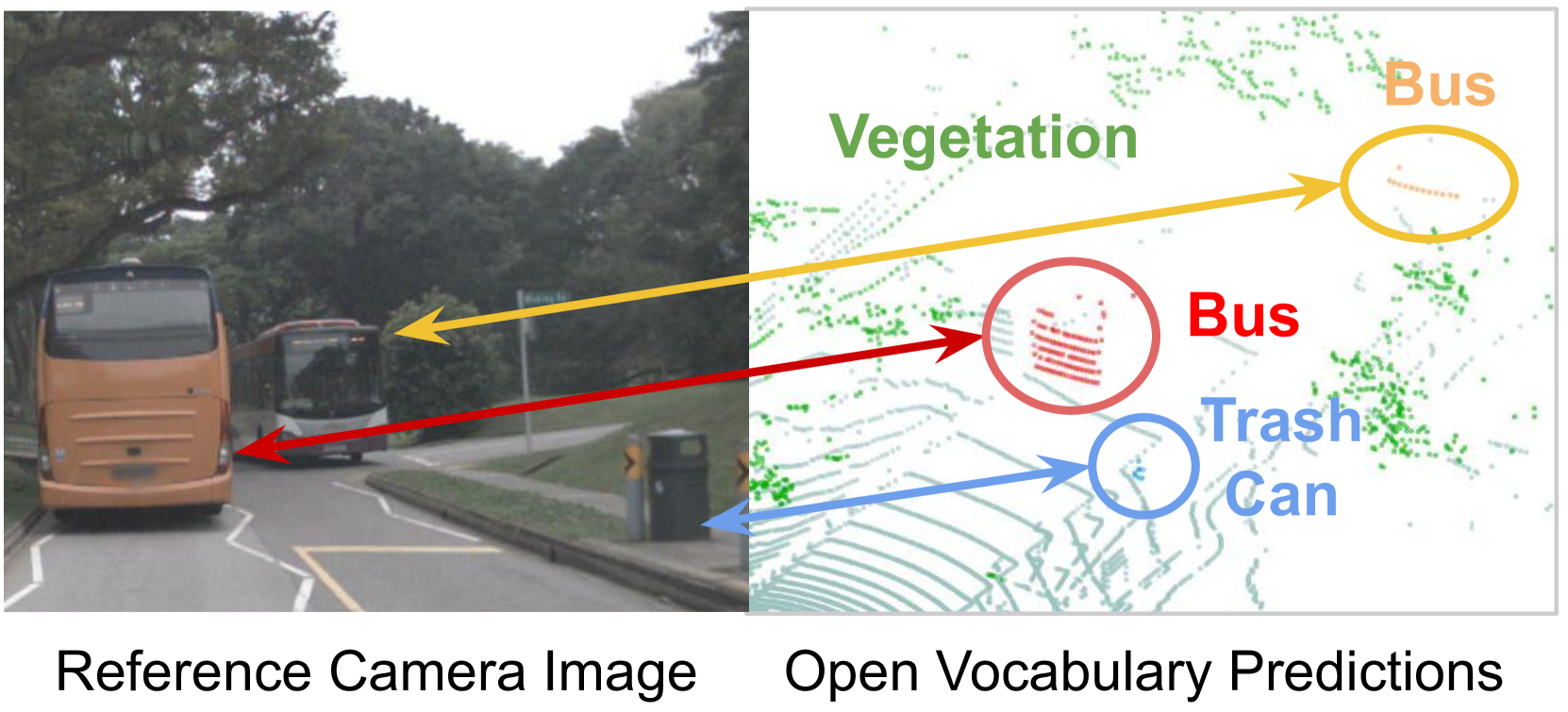
0
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Read more4/4/2024