SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models

0

Sign in to get full access
Overview
- This paper presents SecFormer, a novel approach for fast and accurate privacy-preserving inference with large language models.
- SecFormer aims to address the challenges of privacy and efficiency in deploying these powerful models in real-world applications.
- The proposed method leverages secure multiparty computation (MPC) techniques to enable private inference without compromising model accuracy.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have demonstrated remarkable capabilities in a wide range of natural language processing tasks. However, their deployment in real-world applications can be hindered by privacy concerns and computational inefficiency.
SecFormer tackles these issues by introducing a privacy-preserving inference framework. The key idea is to split the model computation across multiple parties, each holding a portion of the model parameters. This allows the model to be evaluated without exposing the sensitive information to any single party.
To further improve efficiency, SecFormer incorporates techniques like IceFormer and PartialFormer to accelerate the inference process. These methods leverage the unique characteristics of transformer-based models to selectively compute only the necessary parts of the model, reducing the overall computational cost.
Additionally, SecFormer integrates Ditto, a quantization-aware technique, to further optimize the model size and latency without sacrificing accuracy. This enables the deployment of large language models on resource-constrained devices, such as edge devices or mobile phones, while preserving privacy.
The combination of secure multiparty computation, selective model computation, and quantization-aware optimization in SecFormer aims to strike a balance between privacy, accuracy, and efficiency, making large language models more accessible and practical for a wide range of real-world applications.
Technical Explanation
SecFormer leverages secure multiparty computation (MPC) to enable privacy-preserving inference with large language models. The model is split across multiple parties, each holding a portion of the parameters. During inference, the parties collaborate to compute the model output without exposing the individual model components to any single party.
To improve efficiency, SecFormer employs techniques like IceFormer and PartialFormer. IceFormer accelerates the inference process for long input sequences by selectively computing only the necessary parts of the model. PartialFormer takes a similar approach, but instead of focusing on input length, it models only the relevant parts of the input, reducing the overall computation.
Additionally, SecFormer integrates Ditto, a quantization-aware technique, to optimize the model size and latency without sacrificing accuracy. This enables the deployment of large language models on resource-constrained devices while preserving privacy.
The authors evaluate SecFormer on various natural language processing tasks, including text classification, question answering, and language generation. The results demonstrate that SecFormer achieves comparable accuracy to the original, non-private models while providing significant speedups and reducing the computational resources required.
Critical Analysis
The SecFormer approach offers a promising solution for addressing the privacy and efficiency challenges in deploying large language models. By leveraging secure multiparty computation, the method ensures that sensitive model information is not exposed to any single party, thus protecting user privacy.
However, the authors acknowledge that the secure multiparty computation protocol introduces additional computational overhead, which may limit the practical deployment of SecFormer in some scenarios. The authors suggest that further optimizations or the use of specialized hardware could help mitigate this issue.
Additionally, the paper does not provide a comprehensive analysis of the potential security vulnerabilities or potential attack vectors associated with the secure multiparty computation protocol used in SecFormer. It would be valuable for the authors to address these concerns in future work to strengthen the security guarantees of the proposed approach.
Finally, while the performance results are promising, it would be beneficial to explore the scalability of SecFormer as the size and complexity of the language models continue to grow. Investigating the trade-offs between privacy, accuracy, and efficiency as the model scale increases would provide valuable insights for the long-term deployment of such privacy-preserving inference techniques.
Conclusion
SecFormer presents a novel approach for enabling fast and accurate privacy-preserving inference with large language models. By combining secure multiparty computation, selective model computation, and quantization-aware optimization, the authors have developed a framework that aims to strike a balance between privacy, accuracy, and efficiency.
The successful demonstration of SecFormer on various natural language processing tasks suggests that the proposed method has the potential to make large language models more accessible and practical for a wide range of real-world applications, where both privacy and performance are of paramount importance. As the field of large language models continues to evolve, the principles and techniques introduced in SecFormer could pave the way for more secure and efficient deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models
Jinglong Luo, Yehong Zhang, Zhuo Zhang, Jiaqi Zhang, Xin Mu, Hui Wang, Yue Yu, Zenglin Xu
With the growing use of large language models hosted on cloud platforms to offer inference services, privacy concerns are escalating, especially concerning sensitive data like investment plans and bank account details. Secure Multi-Party Computing (SMPC) emerges as a promising solution to protect the privacy of inference data and model parameters. However, the application of SMPC in Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often leads to considerable slowdowns or declines in performance. This is largely due to the multitude of nonlinear operations in the Transformer architecture, which are not well-suited to SMPC and difficult to circumvent or optimize effectively. To address this concern, we introduce an advanced optimization framework called SecFormer, to achieve fast and accurate PPI for Transformer models. By implementing model design optimization, we successfully eliminate the high-cost exponential and maximum operations in PPI without sacrificing model performance. Additionally, we have developed a suite of efficient SMPC protocols that utilize segmented polynomials, Fourier series and Goldschmidt's method to handle other complex nonlinear functions within PPI, such as GeLU, LayerNorm, and Softmax. Our extensive experiments reveal that SecFormer outperforms MPCFormer in performance, showing improvements of $5.6%$ and $24.2%$ for BERT$_{text{BASE}}$ and BERT$_{text{LARGE}}$, respectively. In terms of efficiency, SecFormer is 3.56 and 3.58 times faster than Puma for BERT$_{text{BASE}}$ and BERT$_{text{LARGE}}$, demonstrating its effectiveness and speed.
Read more6/7/2024
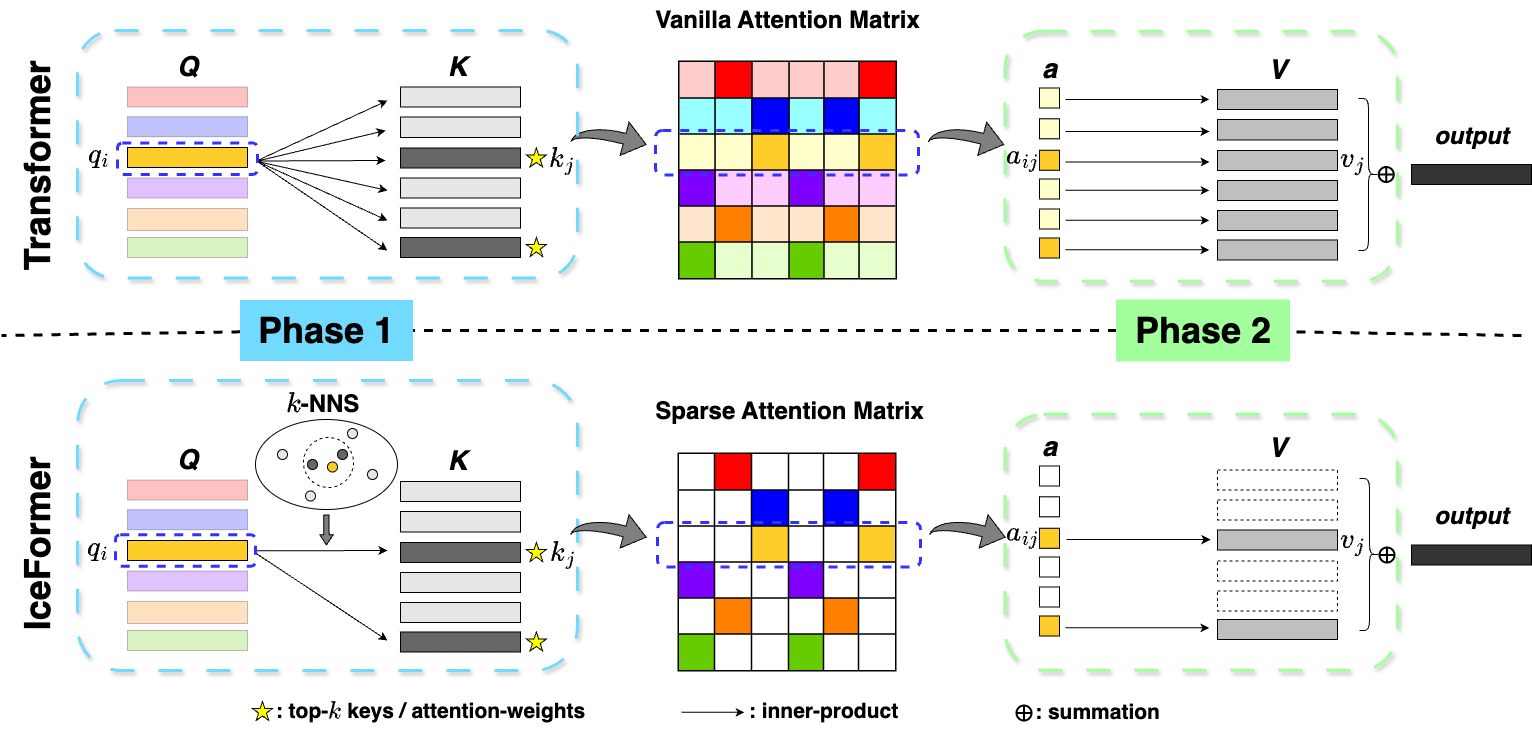
0
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Yuzhen Mao, Martin Ester, Ke Li
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
Read more5/7/2024
🛠️
0
PartialFormer: Modeling Part Instead of Whole for Machine Translation
Tong Zheng, Bei Li, Huiwen Bao, Jiale Wang, Weiqiao Shan, Tong Xiao, Jingbo Zhu
The design choices in Transformer feed-forward neural networks have resulted in significant computational and parameter overhead. In this work, we emphasize the importance of hidden dimensions in designing lightweight FFNs, a factor often overlooked in previous architectures. Guided by this principle, we introduce PartialFormer, a parameter-efficient Transformer architecture utilizing multiple smaller FFNs to reduce parameters and computation while maintaining essential hidden dimensions. These smaller FFNs are integrated into a multi-head attention mechanism for effective collaboration. We also propose a tailored head scaling strategy to enhance PartialFormer's capabilities. Furthermore, we present a residual-like attention calculation to improve depth scaling within PartialFormer. Extensive experiments on 9 translation tasks and 1 abstractive summarization task validate the effectiveness of our PartialFormer approach on machine translation and summarization tasks. Our code would be available at: https://github.com/zhengkid/PartialFormer.
Read more6/6/2024

0
SGFormer: Simplifying and Empowering Transformers for Large-Graph Representations
Qitian Wu, Wentao Zhao, Chenxiao Yang, Hengrui Zhang, Fan Nie, Haitian Jiang, Yatao Bian, Junchi Yan
Learning representations on large-sized graphs is a long-standing challenge due to the inter-dependence nature involved in massive data points. Transformers, as an emerging class of foundation encoders for graph-structured data, have shown promising performance on small graphs due to its global attention capable of capturing all-pair influence beyond neighboring nodes. Even so, existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated models by stacking deep multi-head attentions. In this paper, we critically demonstrate that even using a one-layer attention can bring up surprisingly competitive performance across node property prediction benchmarks where node numbers range from thousand-level to billion-level. This encourages us to rethink the design philosophy for Transformers on large graphs, where the global attention is a computation overhead hindering the scalability. We frame the proposed scheme as Simplified Graph Transformers (SGFormer), which is empowered by a simple attention model that can efficiently propagate information among arbitrary nodes in one layer. SGFormer requires none of positional encodings, feature/graph pre-processing or augmented loss. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M and yields up to 141x inference acceleration over SOTA Transformers on medium-sized graphs. Beyond current results, we believe the proposed methodology alone enlightens a new technical path of independent interest for building Transformers on large graphs.
Read more8/19/2024