Ditto: Quantization-aware Secure Inference of Transformers upon MPC

0
🤯
Sign in to get full access
Overview
- Privacy concerns with sensitive client data and trained models like Transformers
- Secure multi-party computation (MPC) techniques used to enable secure inference, but with overhead
- Existing works aim to reduce overhead using more MPC-friendly non-linear function approximations
- Integration of quantization used in plaintext inference into the MPC domain remains unclear
Plain English Explanation
When working with sensitive client data and large language models like Transformers, privacy is a major concern. To address this, researchers use secure multi-party computation (MPC) techniques to enable secure inference, but this process can be inefficient and introduce overhead.
Previous work has tried to reduce this overhead by using more MPC-friendly approximations of the non-linear functions used in these models. However, it's still unclear how to effectively integrate the quantization techniques that are commonly used to optimize plaintext inference into the MPC domain.
To bridge this gap, the researchers propose a framework called Ditto, which enables more efficient quantization-aware secure Transformer inference. This approach significantly decreases both the computation and communication overhead, leading to improvements in overall efficiency.
Technical Explanation
The researchers first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model's utility. They then propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference.
Through extensive experiments on BERT and GPT-2 models, the researchers demonstrate that their Ditto framework is about 3.14 to 4.40 times faster than the previous state-of-the-art approach, MPCFormer, and 1.44 to 2.35 times faster than the PUMA framework, with negligible utility degradation.
Critical Analysis
The paper provides a comprehensive solution to the challenge of efficiently integrating quantization techniques into the secure inference domain. However, the researchers acknowledge that their approach may still incur some overhead compared to plaintext inference, and they suggest further optimizations, such as attention-aware post-training mixed-precision quantization or genetic quantization-aware approximation of non-linear operations, as potential avenues for future research.
Additionally, the paper does not explore the impact of different quantization schemes or the trade-offs between model accuracy and inference speed in the secure inference setting. Further investigation into these areas could provide valuable insights for practitioners.
Conclusion
The Ditto framework proposed in this paper represents a significant step forward in enabling efficient and secure Transformer inference. By seamlessly integrating quantization techniques into the MPC-based secure inference process, the researchers have achieved substantial performance improvements while maintaining the model's utility. This work has important implications for the deployment of large language models in privacy-sensitive applications, paving the way for more widespread adoption of secure inference capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Ditto: Quantization-aware Secure Inference of Transformers upon MPC
Haoqi Wu, Wenjing Fang, Yancheng Zheng, Junming Ma, Jin Tan, Yinggui Wang, Lei Wang
Due to the rising privacy concerns on sensitive client data and trained models like Transformers, secure multi-party computation (MPC) techniques are employed to enable secure inference despite attendant overhead. Existing works attempt to reduce the overhead using more MPC-friendly non-linear function approximations. However, the integration of quantization widely used in plaintext inference into the MPC domain remains unclear. To bridge this gap, we propose the framework named Ditto to enable more efficient quantization-aware secure Transformer inference. Concretely, we first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model utility. Then, we propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference. This approach significantly decreases both computation and communication overhead, leading to improvements in overall efficiency. We conduct extensive experiments on Bert and GPT2 models to evaluate the performance of Ditto. The results demonstrate that Ditto is about $3.14sim 4.40times$ faster than MPCFormer (ICLR 2023) and $1.44sim 2.35times$ faster than the state-of-the-art work PUMA with negligible utility degradation.
Read more5/10/2024
0
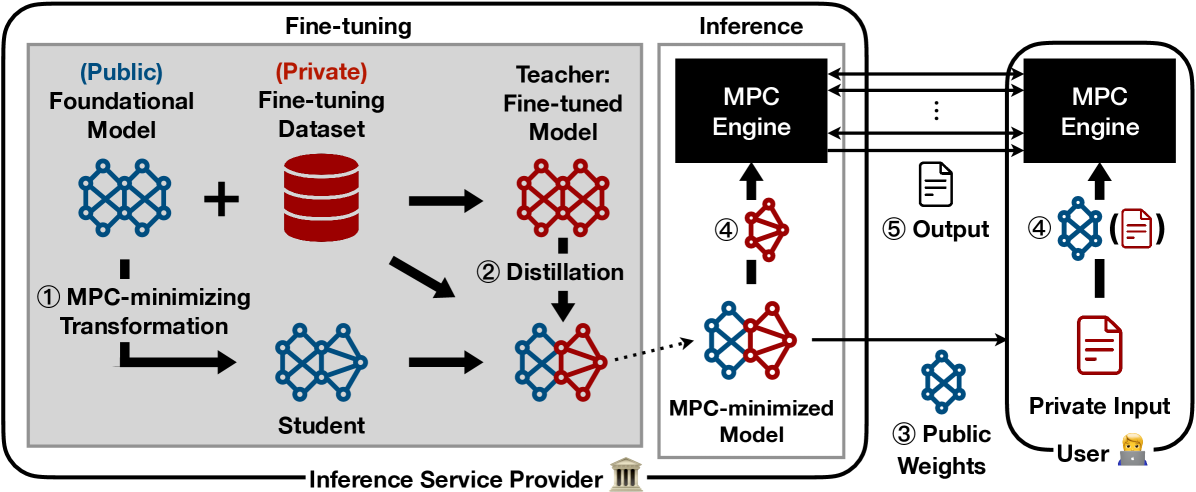
MPC-Minimized Secure LLM Inference
Deevashwer Rathee, Dacheng Li, Ion Stoica, Hao Zhang, Raluca Popa
Many inference services based on large language models (LLMs) pose a privacy concern, either revealing user prompts to the service or the proprietary weights to the user. Secure inference offers a solution to this problem through secure multi-party computation (MPC), however, it is still impractical for modern LLM workload due to the large overhead imposed by MPC. To address this overhead, we propose Marill, a framework that adapts LLM fine-tuning to minimize MPC usage during secure inference. Marill introduces high-level architectural changes during fine-tuning that significantly reduce the number of expensive operations needed within MPC during inference, by removing some and relocating others outside MPC without compromising security. As a result, Marill-generated models are more efficient across all secure inference protocols and our approach complements MPC-friendly approximations for such operations. Compared to standard fine-tuning, Marill results in 3.6-11.3x better runtime and 2.4-6.9x better communication during secure inference across various MPC settings, while typically preserving over 90% performance across downstream tasks.
Read more8/9/2024

0
CipherDM: Secure Three-Party Inference for Diffusion Model Sampling
Xin Zhao, Xiaojun Chen, Xudong Chen, He Li, Tingyu Fan, Zhendong Zhao
Diffusion Models (DMs) achieve state-of-the-art synthesis results in image generation and have been applied to various fields. However, DMs sometimes seriously violate user privacy during usage, making the protection of privacy an urgent issue. Using traditional privacy computing schemes like Secure Multi-Party Computation (MPC) directly in DMs faces significant computation and communication challenges. To address these issues, we propose CipherDM, the first novel, versatile and universal framework applying MPC technology to DMs for secure sampling, which can be widely implemented on multiple DM based tasks. We thoroughly analyze sampling latency breakdown, find time-consuming parts and design corresponding secure MPC protocols for computing nonlinear activations including SoftMax, SiLU and Mish. CipherDM is evaluated on popular architectures (DDPM, DDIM) using MNIST dataset and on SD deployed by diffusers. Compared to direct implementation on SPU, our approach improves running time by approximately 1.084times sim 2.328times, and reduces communication costs by approximately 1.212times sim 1.791times.
Read more9/10/2024
🤯
0
MPC-Pipe: an Efficient Pipeline Scheme for Secure Multi-party Machine Learning Inference
Yongqin Wang, Rachit Rajat, Murali Annavaram
Multi-party computing (MPC) has been gaining popularity as a secure computing model over the past few years. However, prior works have demonstrated that MPC protocols still pay substantial performance penalties compared to plaintext, particularly when applied to ML algorithms. The overhead is due to added computation and communication costs. Prior studies, as well as our own analysis, found that most MPC protocols today sequentially perform communication and computation. The participating parties must compute on their shares first and then perform data communication to allow the distribution of new secret shares before proceeding to the next computation step. In this work, we show that serialization is unnecessary, particularly in the context of ML computations (both in Convolutional neural networks and in Transformer-based models). We demonstrate that it is possible to carefully orchestrate the computation and communication steps to overlap. We propose MPC-Pipe, an efficient MPC system for both training and inference of ML workloads, which pipelines computations and communications in an MPC protocol during the online phase. MPC-Pipe proposes three pipeline schemes to optimize the online phase of ML in the semi-honest majority adversary setting. We implement MPC-Pipe by augmenting a modified version of CrypTen, which separates online and offline phases. We evaluate the end-to-end system performance benefits of the online phase of MPC using deep neural networks (VGG16, ResNet50) and Transformers using different network settings. We show that MPC-Pipe can improve the throughput and latency of ML workloads.
Read more8/28/2024