IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
2405.02842
0
0
Abstract
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces IceFormer, a novel approach to accelerate inference of long-sequence Transformer models on CPUs.
- IceFormer employs several techniques to improve efficiency, including context-aware attention, efficient inference, and multi-level acceleration.
- The authors demonstrate that IceFormer can achieve significant speedups over traditional Transformer models on CPU-based inference, making it a practical solution for deploying large language models on resource-constrained devices.
Plain English Explanation
The paper presents IceFormer, a new way to run large language models more efficiently on regular computers (CPUs). Large language models, like the ones used for tasks like text generation and translation, can be slow and resource-intensive to run, especially on less powerful hardware. IceFormer uses several clever techniques to speed up the process of generating text with these models on CPUs.
One key idea is context-aware attention, which helps the model focus on the most important parts of the input text when making predictions, rather than considering everything equally. This saves computation and time. IceFormer also uses efficient inference methods, which optimize the way the model operations are carried out to be faster. Finally, it employs a multi-level acceleration approach, where different parts of the model are optimized in different ways to achieve the best overall performance.
The end result is that IceFormer can run large language models much faster on regular CPUs, without sacrificing too much accuracy. This makes it practical to deploy these powerful AI models on a wider range of devices, beyond just high-end hardware. The techniques used in IceFormer could also be applied to accelerate other types of large neural networks.
Technical Explanation
The paper introduces IceFormer, a novel architecture for accelerating the inference of long-sequence Transformer models on CPU-based systems. IceFormer incorporates several key innovations to improve efficiency:
-
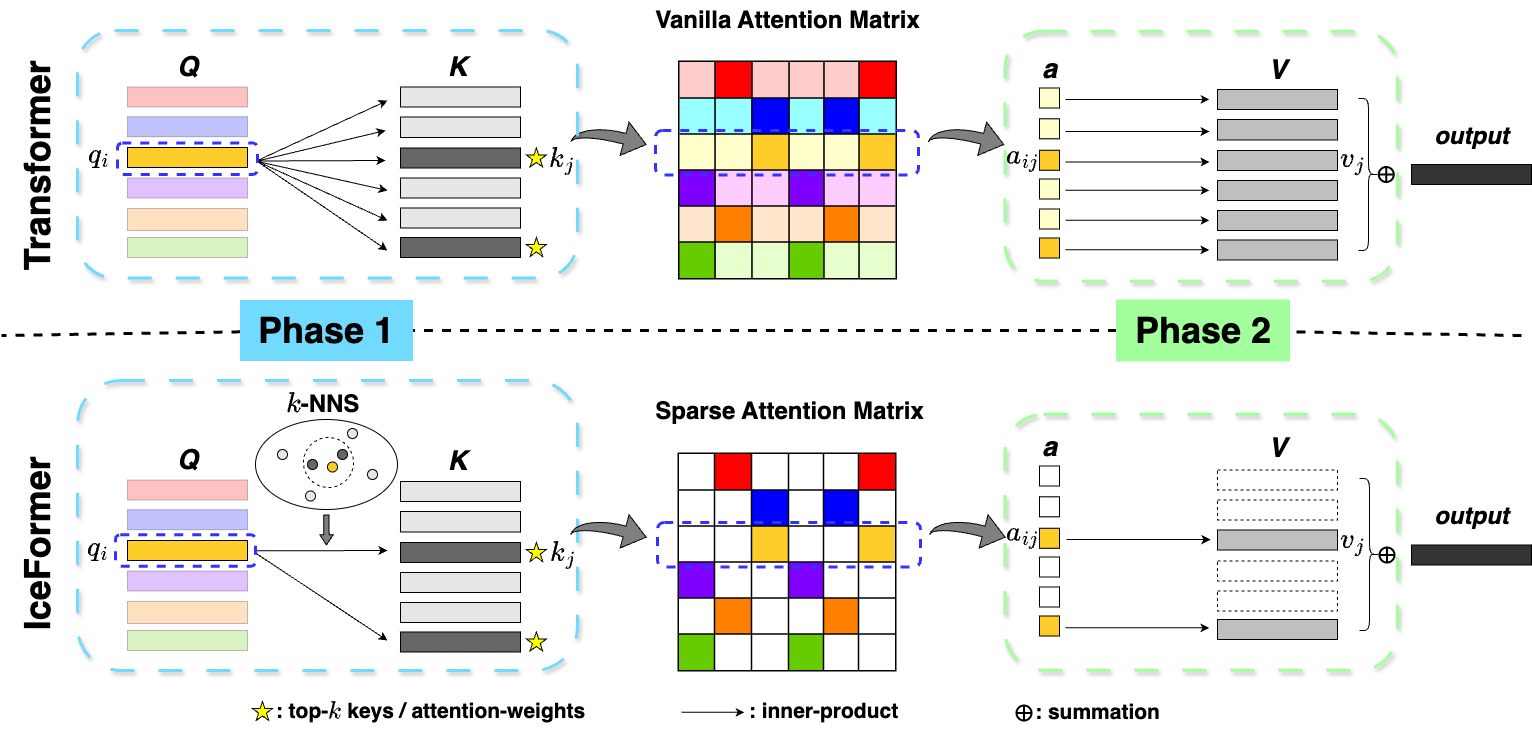
Context-Aware Attention: IceFormer employs a context-aware attention mechanism that selectively focuses on the most relevant parts of the input sequence, rather than treating all positions equally. This helps reduce the computational cost of attention computations.
-
Efficient Inference: The authors develop efficient inference techniques that optimize the underlying matrix operations to achieve faster CPU-based inference, including efficient economic attention.
-
Multi-Level Acceleration: IceFormer uses a multi-level acceleration framework that applies different optimization strategies to different components of the Transformer model, tailoring the acceleration techniques to the specific computational characteristics of each part.
The authors evaluate IceFormer on a range of long-sequence tasks, including language modeling and machine translation, and demonstrate significant speedups over traditional Transformer models on CPU-based inference, with only minor accuracy degradation. These results suggest that IceFormer can make large language models more accessible on resource-constrained devices.
Critical Analysis
The paper provides a comprehensive and well-designed approach to accelerating Transformer-based models on CPUs. The authors have carefully considered the various bottlenecks in traditional Transformer architectures and developed targeted solutions to address them.
One potential caveat is that the performance gains of IceFormer may be task-dependent, as the effectiveness of the proposed techniques could vary based on the specific characteristics of the input sequences and the target application. Additionally, the authors acknowledge that there is a trade-off between inference speed and model accuracy, and further research may be needed to find the optimal balance for different use cases.
Another area for potential exploration is the applicability of IceFormer to other types of large neural networks beyond Transformers. The core principles of context-aware attention, efficient inference, and multi-level acceleration could potentially be extended to accelerate the inference of other complex models on resource-constrained hardware.
Overall, the IceFormer approach represents a valuable contribution to the field of efficient large-scale language model deployment, and the techniques introduced in this paper could have significant implications for making powerful AI models more accessible and practical for a wider range of applications and platforms.
Conclusion
The IceFormer paper presents a novel and effective approach to accelerating the inference of long-sequence Transformer models on CPU-based systems. By employing techniques like context-aware attention, efficient inference, and multi-level acceleration, the authors have demonstrated significant speedups over traditional Transformer models without sacrificing too much accuracy.
These innovations have the potential to make large language models more practical to deploy on a wider range of devices, including resource-constrained edge devices. The principles and methods introduced in this paper could also be applied to accelerate other types of complex neural networks, potentially unlocking new possibilities for the real-world application of powerful AI models.
As the demand for efficient and accessible AI solutions continues to grow, research like this, which focuses on bridging the gap between model complexity and hardware capabilities, will become increasingly important. The IceFormer paper represents a valuable contribution to this ongoing effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
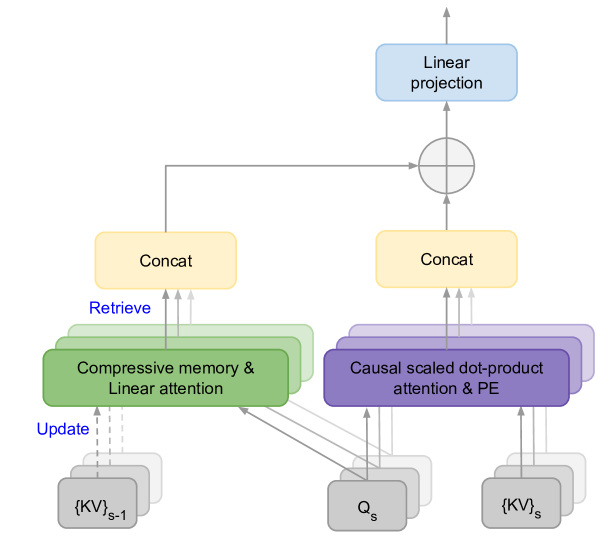
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
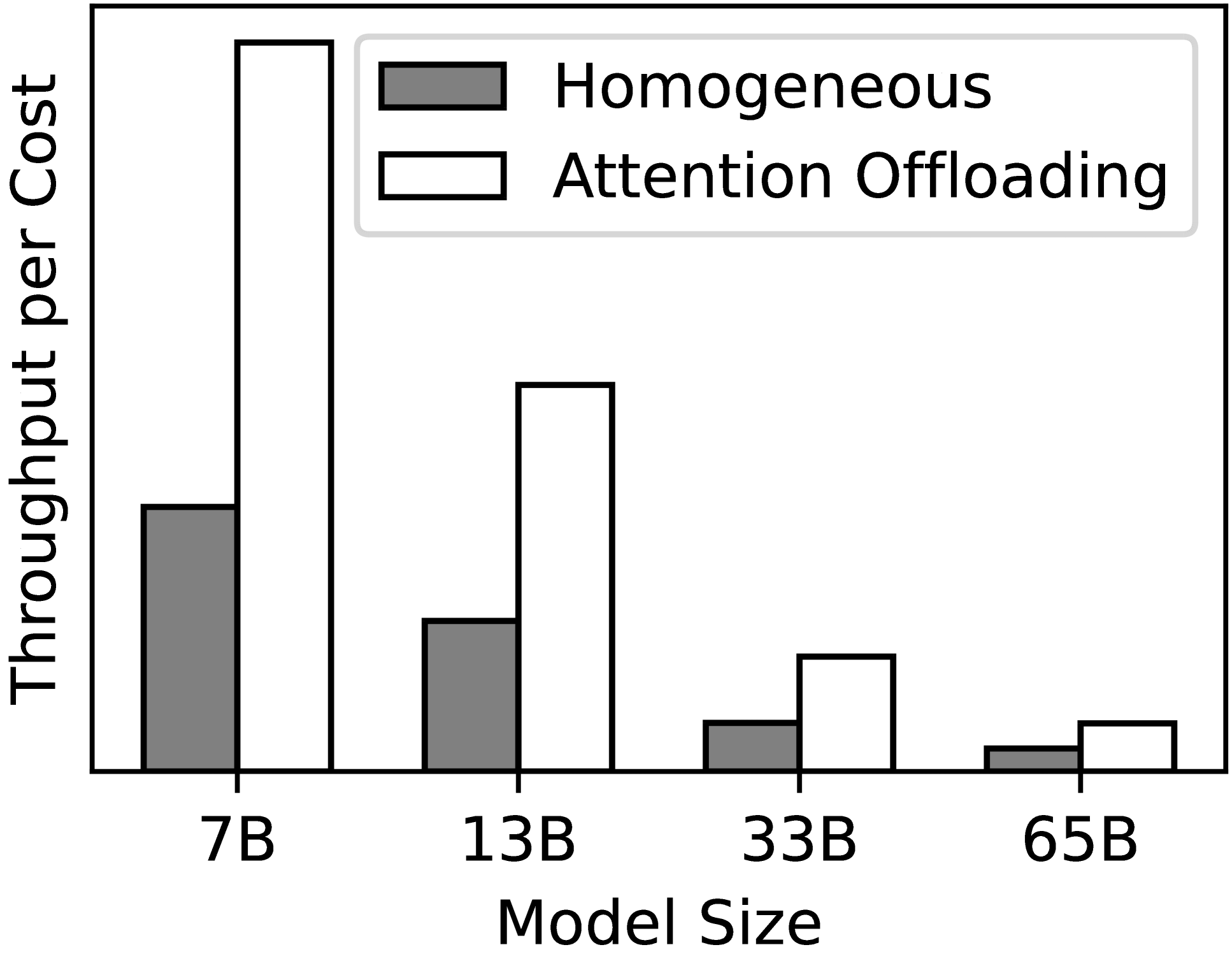
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
A Multi-Level Framework for Accelerating Training Transformer Models
Longwei Zou, Han Zhang, Yangdong Deng
0
0
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
4/15/2024