Second-order Information Promotes Mini-Batch Robustness in Variance-Reduced Gradients
2404.14758
0
0
🧪
Abstract
We show that, for finite-sum minimization problems, incorporating partial second-order information of the objective function can dramatically improve the robustness to mini-batch size of variance-reduced stochastic gradient methods, making them more scalable while retaining their benefits over traditional Newton-type approaches. We demonstrate this phenomenon on a prototypical stochastic second-order algorithm, called Mini-Batch Stochastic Variance-Reduced Newton ($texttt{Mb-SVRN}$), which combines variance-reduced gradient estimates with access to an approximate Hessian oracle. In particular, we show that when the data size $n$ is sufficiently large, i.e., $ngg alpha^2kappa$, where $kappa$ is the condition number and $alpha$ is the Hessian approximation factor, then $texttt{Mb-SVRN}$ achieves a fast linear convergence rate that is independent of the gradient mini-batch size $b$, as long $b$ is in the range between $1$ and $b_{max}=O(n/(alpha log n))$. Only after increasing the mini-batch size past this critical point $b_{max}$, the method begins to transition into a standard Newton-type algorithm which is much more sensitive to the Hessian approximation quality. We demonstrate this phenomenon empirically on benchmark optimization tasks showing that, after tuning the step size, the convergence rate of $texttt{Mb-SVRN}$ remains fast for a wide range of mini-batch sizes, and the dependence of the phase transition point $b_{max}$ on the Hessian approximation factor $alpha$ aligns with our theoretical predictions.
Create account to get full access
Overview
- The paper investigates how incorporating partial second-order information of the objective function can improve the robustness and scalability of variance-reduced stochastic gradient methods for finite-sum minimization problems.
- The authors demonstrate this on a stochastic second-order algorithm called Mini-Batch Stochastic Variance-Reduced Newton (Mb-SVRN), which combines variance-reduced gradient estimates with an approximate Hessian oracle.
- They show that when the data size is sufficiently large, Mb-SVRN can achieve fast linear convergence that is independent of the gradient mini-batch size, as long as the mini-batch size is below a critical point.
- Beyond this critical point, the method transitions into a more standard Newton-type algorithm that is more sensitive to the Hessian approximation quality.
Plain English Explanation
In machine learning, we often need to minimize complex objective functions that are the sum of many smaller terms, each representing a piece of training data. Variance-reduced stochastic gradient methods are a popular approach for these "finite-sum" optimization problems, as they can converge quickly while using small batches of data at a time.
However, these methods can be sensitive to the size of the data batches (called the "mini-batch size"). The authors of this paper wanted to find a way to make these methods more robust to the mini-batch size, so that they could be used to solve even larger optimization problems.
Their key insight was to incorporate some information about the curvature of the objective function, in addition to just the gradient information that these methods normally use. Specifically, they used an approximate Hessian oracle - a way to get a rough estimate of the second derivatives of the objective.
They showed that, if the dataset is large enough compared to the condition number (a measure of how difficult the optimization problem is), then their "Mini-Batch Stochastic Variance-Reduced Newton" (Mb-SVRN) algorithm can converge quickly without being sensitive to the mini-batch size, as long as the mini-batch size is not too large. Once the mini-batch size gets too large, the method starts behaving more like a standard Newton-type algorithm, which is more affected by the quality of the Hessian approximation.
This means that Mb-SVRN can be used to solve very large optimization problems efficiently, by using small mini-batches without sacrificing convergence speed. The authors demonstrate this effect empirically on some benchmark tasks, showing that Mb-SVRN can maintain a fast convergence rate across a wide range of mini-batch sizes.
Technical Explanation
The key idea behind the Mb-SVRN algorithm is to combine variance-reduced gradient estimates with access to an approximate Hessian oracle. The variance-reduced gradients help speed up convergence, while the Hessian information helps make the method more robust to the mini-batch size.
Specifically, the authors show that when the data size n is sufficiently large compared to the condition number κ and the Hessian approximation quality α, then Mb-SVRN can achieve a fast linear convergence rate that is independent of the mini-batch size b, as long as b is within a certain range (between 1 and b_max = O(n/(α log n))).
Only after increasing the mini-batch size past this critical point b_max, does the method begin to transition into a more standard Newton-type algorithm, which is much more sensitive to the quality of the Hessian approximation.
The authors demonstrate this phenomenon empirically on benchmark optimization tasks, showing that the convergence rate of Mb-SVRN remains fast for a wide range of mini-batch sizes, as long as the step size is tuned appropriately. They also observe that the dependence of the phase transition point b_max on the Hessian approximation factor α aligns with their theoretical predictions.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the Mb-SVRN algorithm, and the insights around its robustness to mini-batch size are quite interesting. However, a few potential limitations and areas for further research are worth noting:
-
The analysis assumes the data size n is sufficiently large compared to the condition number κ and Hessian approximation quality α. In practice, it may not always be feasible to have such a large dataset, especially for problems with high-dimensional or complex objective functions.
-
The paper focuses on the finite-sum minimization setting, but many real-world optimization problems involve stochastic, non-convex, or constrained objectives. Extending the analysis to these more general settings could broaden the applicability of the Mb-SVRN approach.
-
The authors use a relatively simple Hessian approximation scheme in their experiments. Exploring more sophisticated Hessian approximation techniques, and their impact on the method's performance and robustness, could be a fruitful direction for future research.
-
While the paper demonstrates the benefits of Mb-SVRN empirically, further investigation into its practical implementation, such as hyperparameter tuning and scalability to very large datasets, would help assess its real-world applicability.
Overall, this work presents an interesting and potentially impactful contribution to the field of large-scale optimization. The authors' insights on the role of second-order information in improving the robustness of variance-reduced methods are worth considering for researchers and practitioners working on challenging optimization problems.
Conclusion
This paper introduces a novel stochastic second-order algorithm called Mini-Batch Stochastic Variance-Reduced Newton (Mb-SVRN) that combines variance-reduced gradient estimates with an approximate Hessian oracle. The authors demonstrate that, under certain conditions on the data size and problem difficulty, Mb-SVRN can achieve fast linear convergence that is independent of the mini-batch size, making it more scalable than traditional Newton-type methods.
The key insight is that incorporating partial second-order information can dramatically improve the robustness of variance-reduced stochastic gradient methods, allowing them to efficiently solve large-scale optimization problems. This work contributes to the ongoing research on developing efficient and scalable optimization algorithms for machine learning, with potential implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Sign-Based Optimization: Accelerating Convergence via Variance Reduction
Wei Jiang, Sifan Yang, Wenhao Yang, Lijun Zhang
0
0
Sign stochastic gradient descent (signSGD) is a communication-efficient method that transmits only the sign of stochastic gradients for parameter updating. Existing literature has demonstrated that signSGD can achieve a convergence rate of $mathcal{O}(d^{1/2}T^{-1/4})$, where $d$ represents the dimension and $T$ is the iteration number. In this paper, we improve this convergence rate to $mathcal{O}(d^{1/2}T^{-1/3})$ by introducing the Sign-based Stochastic Variance Reduction (SSVR) method, which employs variance reduction estimators to track gradients and leverages their signs to update. For finite-sum problems, our method can be further enhanced to achieve a convergence rate of $mathcal{O}(m^{1/4}d^{1/2}T^{-1/2})$, where $m$ denotes the number of component functions. Furthermore, we investigate the heterogeneous majority vote in distributed settings and introduce two novel algorithms that attain improved convergence rates of $mathcal{O}(d^{1/2}T^{-1/2} + dn^{-1/2})$ and $mathcal{O}(d^{1/4}T^{-1/4})$ respectively, outperforming the previous results of $mathcal{O}(dT^{-1/4} + dn^{-1/2})$ and $mathcal{O}(d^{3/8}T^{-1/8})$, where $n$ represents the number of nodes. Numerical experiments across different tasks validate the effectiveness of our proposed methods.
6/4/2024
Near-Optimal Distributed Minimax Optimization under the Second-Order Similarity
Qihao Zhou, Haishan Ye, Luo Luo
0
0
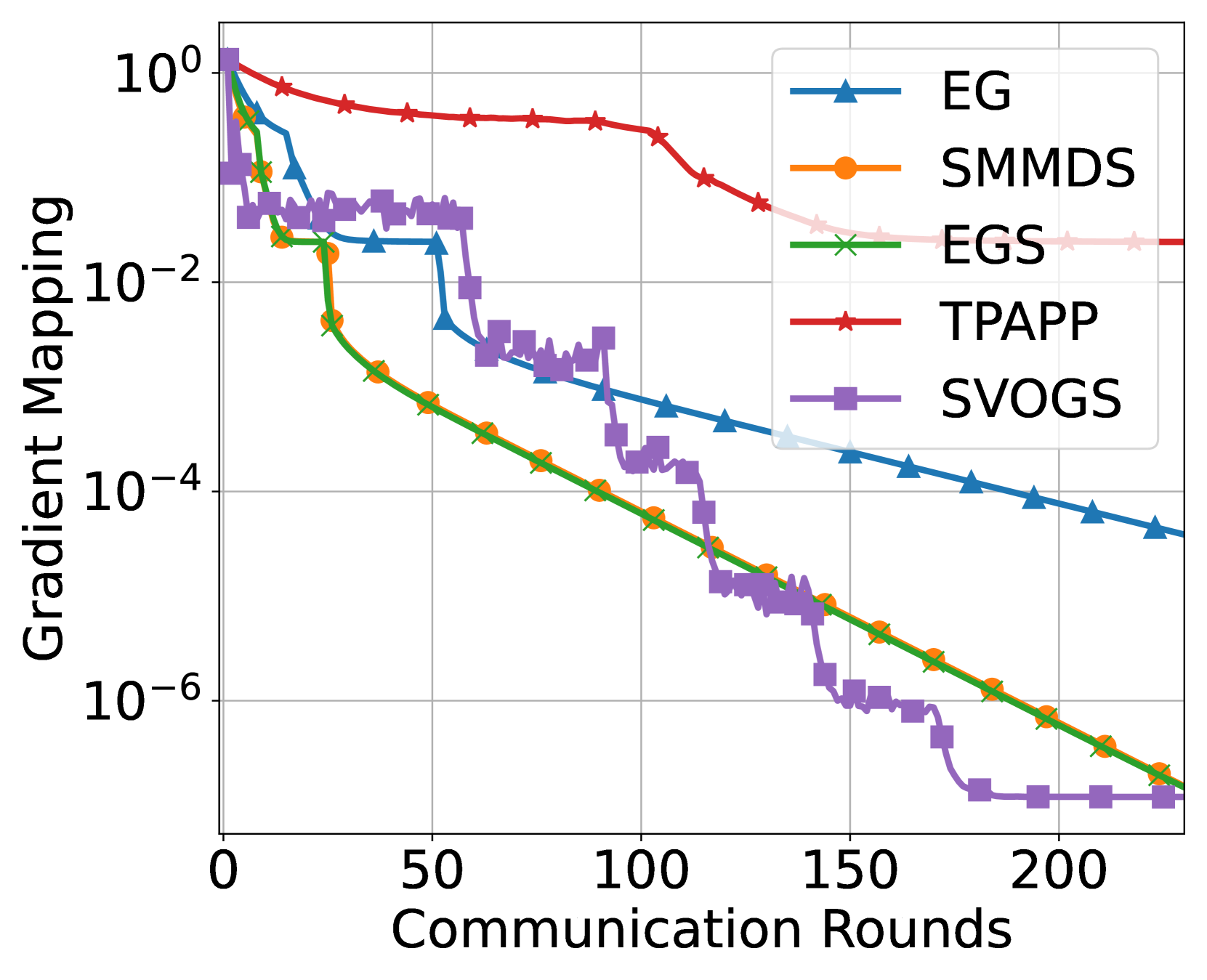
This paper considers the distributed convex-concave minimax optimization under the second-order similarity. We propose stochastic variance-reduced optimistic gradient sliding (SVOGS) method, which takes the advantage of the finite-sum structure in the objective by involving the mini-batch client sampling and variance reduction. We prove SVOGS can achieve the $varepsilon$-duality gap within communication rounds of ${mathcal O}(delta D^2/varepsilon)$, communication complexity of ${mathcal O}(n+sqrt{n}delta D^2/varepsilon)$, and local gradient calls of $tilde{mathcal O}(n+(sqrt{n}delta+L)D^2/varepsilonlog(1/varepsilon))$, where $n$ is the number of nodes, $delta$ is the degree of the second-order similarity, $L$ is the smoothness parameter and $D$ is the diameter of the constraint set. We can verify that all of above complexity (nearly) matches the corresponding lower bounds. For the specific $mu$-strongly-convex-$mu$-strongly-convex case, our algorithm has the upper bounds on communication rounds, communication complexity, and local gradient calls of $mathcal O(delta/mulog(1/varepsilon))$, ${mathcal O}((n+sqrt{n}delta/mu)log(1/varepsilon))$, and $tilde{mathcal O}(n+(sqrt{n}delta+L)/mu)log(1/varepsilon))$ respectively, which are also nearly tight. Furthermore, we conduct the numerical experiments to show the empirical advantages of proposed method.
5/28/2024
🛠️
Stochastic Zeroth-Order Optimization under Strongly Convexity and Lipschitz Hessian: Minimax Sample Complexity
Qian Yu, Yining Wang, Baihe Huang, Qi Lei, Jason D. Lee
0
0
Optimization of convex functions under stochastic zeroth-order feedback has been a major and challenging question in online learning. In this work, we consider the problem of optimizing second-order smooth and strongly convex functions where the algorithm is only accessible to noisy evaluations of the objective function it queries. We provide the first tight characterization for the rate of the minimax simple regret by developing matching upper and lower bounds. We propose an algorithm that features a combination of a bootstrapping stage and a mirror-descent stage. Our main technical innovation consists of a sharp characterization for the spherical-sampling gradient estimator under higher-order smoothness conditions, which allows the algorithm to optimally balance the bias-variance tradeoff, and a new iterative method for the bootstrapping stage, which maintains the performance for unbounded Hessian.
7/1/2024
🛠️
Adaptive and Optimal Second-order Optimistic Methods for Minimax Optimization
Ruichen Jiang, Ali Kavis, Qiujiang Jin, Sujay Sanghavi, Aryan Mokhtari
0
0
We propose adaptive, line search-free second-order methods with optimal rate of convergence for solving convex-concave min-max problems. By means of an adaptive step size, our algorithms feature a simple update rule that requires solving only one linear system per iteration, eliminating the need for line search or backtracking mechanisms. Specifically, we base our algorithms on the optimistic method and appropriately combine it with second-order information. Moreover, distinct from common adaptive schemes, we define the step size recursively as a function of the gradient norm and the prediction error in the optimistic update. We first analyze a variant where the step size requires knowledge of the Lipschitz constant of the Hessian. Under the additional assumption of Lipschitz continuous gradients, we further design a parameter-free version by tracking the Hessian Lipschitz constant locally and ensuring the iterates remain bounded. We also evaluate the practical performance of our algorithm by comparing it to existing second-order algorithms for minimax optimization.
6/5/2024