Near-Optimal Distributed Minimax Optimization under the Second-Order Similarity
2405.16126
0
0
Abstract
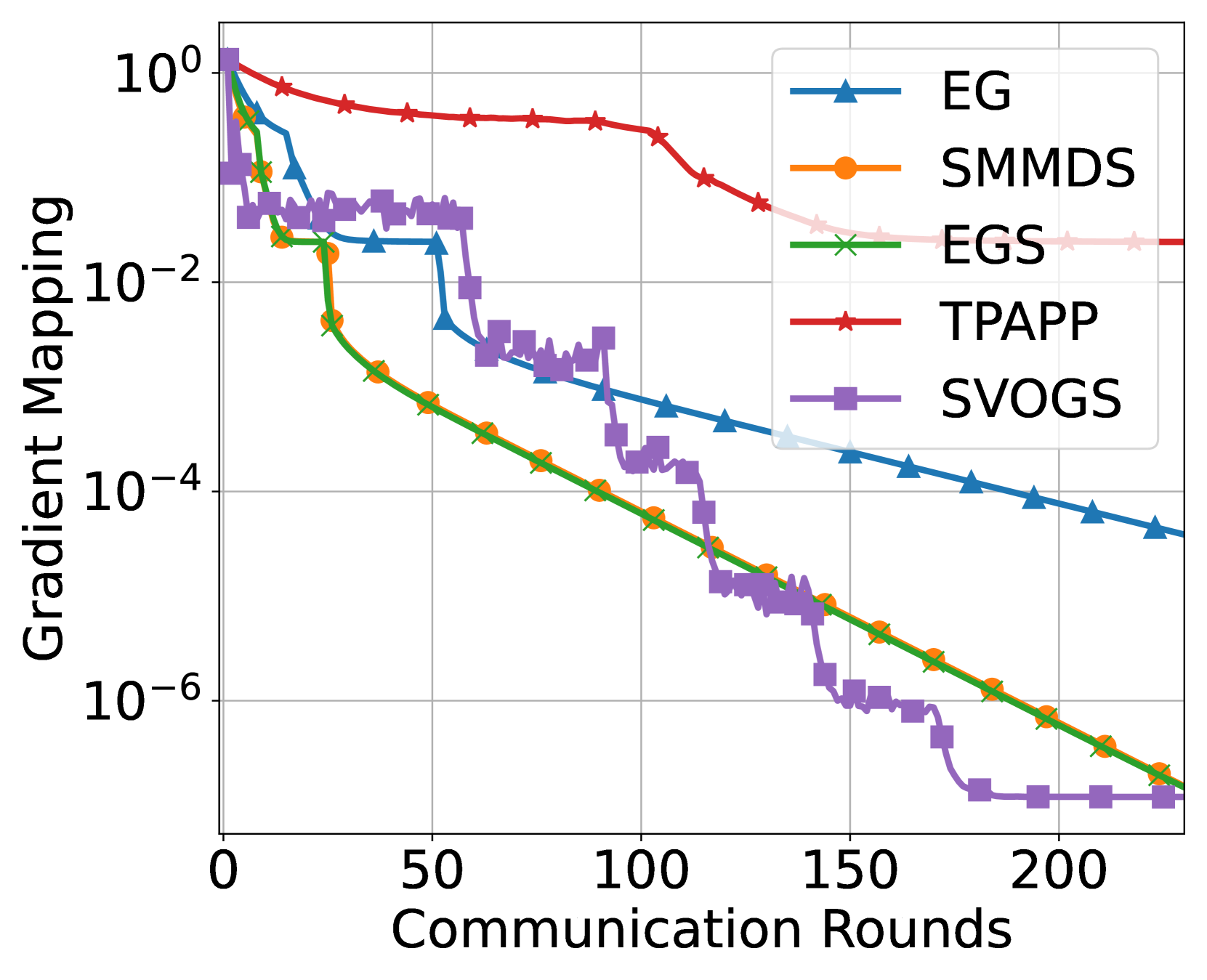
This paper considers the distributed convex-concave minimax optimization under the second-order similarity. We propose stochastic variance-reduced optimistic gradient sliding (SVOGS) method, which takes the advantage of the finite-sum structure in the objective by involving the mini-batch client sampling and variance reduction. We prove SVOGS can achieve the $varepsilon$-duality gap within communication rounds of ${mathcal O}(delta D^2/varepsilon)$, communication complexity of ${mathcal O}(n+sqrt{n}delta D^2/varepsilon)$, and local gradient calls of $tilde{mathcal O}(n+(sqrt{n}delta+L)D^2/varepsilonlog(1/varepsilon))$, where $n$ is the number of nodes, $delta$ is the degree of the second-order similarity, $L$ is the smoothness parameter and $D$ is the diameter of the constraint set. We can verify that all of above complexity (nearly) matches the corresponding lower bounds. For the specific $mu$-strongly-convex-$mu$-strongly-convex case, our algorithm has the upper bounds on communication rounds, communication complexity, and local gradient calls of $mathcal O(delta/mulog(1/varepsilon))$, ${mathcal O}((n+sqrt{n}delta/mu)log(1/varepsilon))$, and $tilde{mathcal O}(n+(sqrt{n}delta+L)/mu)log(1/varepsilon))$ respectively, which are also nearly tight. Furthermore, we conduct the numerical experiments to show the empirical advantages of proposed method.
Create account to get full access
Overview
- This paper presents a distributed minimax optimization algorithm that can achieve near-optimal performance under the second-order similarity assumption.
- The algorithm leverages second-order information, such as the Hessian matrix, to improve the convergence rate compared to first-order methods.
- The authors analyze the theoretical properties of the proposed algorithm and demonstrate its effectiveness through numerical experiments.
Plain English Explanation
The paper discusses a new algorithm for solving a type of optimization problem called minimax optimization in a distributed setting. Minimax optimization is a game-like problem where the goal is to find a solution that minimizes the maximum value of a function.
In a distributed setting, this optimization problem is solved by multiple agents or nodes working together, rather than a single centralized system. The key innovation in this paper is the use of second-order information, such as the Hessian matrix (a measure of the curvature of the function), to improve the algorithm's performance.
Typically, optimization algorithms rely on first-order information, such as the gradient (the slope of the function), which can be limiting. By incorporating second-order information, the proposed algorithm can converge to the optimal solution more quickly, especially under the assumption that the problem exhibits a specific type of similarity between the local functions at each node.
The authors provide a rigorous mathematical analysis of their algorithm, proving that it can achieve near-optimal performance in terms of the number of iterations required to reach the solution. They also demonstrate the practical benefits of their approach through numerical experiments, showing that it outperforms other state-of-the-art distributed optimization methods.
Technical Explanation
The paper introduces a new distributed minimax optimization algorithm that leverages second-order information to achieve near-optimal convergence rates. The algorithm is designed to solve problems where multiple agents or nodes collaborate to minimize the maximum value of a function, known as the minimax optimization problem.
The key technical innovation in this work is the use of second-order information, such as the Hessian matrix, to guide the optimization process. This is in contrast to traditional first-order methods that rely solely on gradient information. The authors show that by incorporating second-order information, the algorithm can converge more quickly, especially under the assumption of second-order similarity between the local functions at each node.
The authors analyze the theoretical properties of the proposed algorithm and prove that it can achieve near-optimal convergence rates. Specifically, they show that the algorithm can match the performance of the centralized second-order minimax optimization method, which has access to global information, while only requiring local information to be shared between the nodes.
To validate the practical benefits of their approach, the authors conduct numerical experiments on various benchmark problems. The results demonstrate that the proposed algorithm outperforms other state-of-the-art distributed optimization methods, such as stochastic constrained decentralized optimization and efficient stochastic algorithms for decentralized non-convex strongly-concave minimax problems.
Critical Analysis
The paper presents a novel and promising approach to distributed minimax optimization, leveraging second-order information to achieve near-optimal convergence rates. The authors provide a rigorous theoretical analysis and comprehensive numerical experiments to support their claims.
One potential limitation of the proposed algorithm is that it relies on the assumption of second-order similarity between the local functions at each node. While this assumption is reasonable in certain scenarios, it may not hold in all practical applications. It would be valuable to explore the algorithm's performance under weaker or alternative assumptions.
Additionally, the paper focuses on the theoretical and empirical aspects of the algorithm, but does not address the potential computational and communication overhead associated with the use of second-order information. In practice, the computation and exchange of Hessian matrices can be challenging, especially in large-scale or resource-constrained distributed systems. Investigating strategies to mitigate these challenges would be an important direction for future research.
Furthermore, the paper does not consider the impact of stochastic or noisy gradients on the algorithm's performance. In real-world applications, the objective function may be subject to noise or uncertainty, which could affect the algorithm's convergence and stability. Extending the analysis to handle such scenarios would be valuable.
Conclusion
This paper presents a novel distributed minimax optimization algorithm that leverages second-order information to achieve near-optimal convergence rates. By incorporating the Hessian matrix into the optimization process, the proposed algorithm can outperform state-of-the-art first-order methods, especially under the assumption of second-order similarity between the local functions.
The theoretical analysis and numerical experiments provided in the paper demonstrate the potential benefits of the approach. However, further research is needed to address the limitations, such as the restrictive assumption of second-order similarity and the potential computational and communication challenges associated with second-order information.
Overall, this work contributes to the ongoing efforts in the field of distributed optimization, highlighting the advantages of utilizing higher-order information to improve the efficiency and performance of decentralized algorithms. The insights and techniques presented in this paper may inspire the development of advanced optimization methods for a wide range of distributed machine learning and optimization problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
New!Stochastic Zeroth-Order Optimization under Strongly Convexity and Lipschitz Hessian: Minimax Sample Complexity
Qian Yu, Yining Wang, Baihe Huang, Qi Lei, Jason D. Lee
0
0
Optimization of convex functions under stochastic zeroth-order feedback has been a major and challenging question in online learning. In this work, we consider the problem of optimizing second-order smooth and strongly convex functions where the algorithm is only accessible to noisy evaluations of the objective function it queries. We provide the first tight characterization for the rate of the minimax simple regret by developing matching upper and lower bounds. We propose an algorithm that features a combination of a bootstrapping stage and a mirror-descent stage. Our main technical innovation consists of a sharp characterization for the spherical-sampling gradient estimator under higher-order smoothness conditions, which allows the algorithm to optimally balance the bias-variance tradeoff, and a new iterative method for the bootstrapping stage, which maintains the performance for unbounded Hessian.
7/1/2024

Stochastic Constrained Decentralized Optimization for Machine Learning with Fewer Data Oracles: a Gradient Sliding Approach
Hoang Huy Nguyen, Yan Li, Tuo Zhao
0
0
In modern decentralized applications, ensuring communication efficiency and privacy for the users are the key challenges. In order to train machine-learning models, the algorithm has to communicate to the data center and sample data for its gradient computation, thus exposing the data and increasing the communication cost. This gives rise to the need for a decentralized optimization algorithm that is communication-efficient and minimizes the number of gradient computations. To this end, we propose the primal-dual sliding with conditional gradient sliding framework, which is communication-efficient and achieves an $varepsilon$-approximate solution with the optimal gradient complexity of $O(1/sqrt{varepsilon}+sigma^2/{varepsilon^2})$ and $O(log(1/varepsilon)+sigma^2/varepsilon)$ for the convex and strongly convex setting respectively and an LO (Linear Optimization) complexity of $O(1/varepsilon^2)$ for both settings given a stochastic gradient oracle with variance $sigma^2$. Compared with the prior work cite{wai-fw-2017}, our framework relaxes the assumption of the optimal solution being a strict interior point of the feasible set and enjoys wider applicability for large-scale training using a stochastic gradient oracle. We also demonstrate the efficiency of our algorithms with various numerical experiments.
4/4/2024
🔍
An Efficient Stochastic Algorithm for Decentralized Nonconvex-Strongly-Concave Minimax Optimization
Lesi Chen, Haishan Ye, Luo Luo
0
0
This paper studies the stochastic nonconvex-strongly-concave minimax optimization over a multi-agent network. We propose an efficient algorithm, called Decentralized Recursive gradient descEnt Ascent Method (DREAM), which achieves the best-known theoretical guarantee for finding the $epsilon$-stationary points. Concretely, it requires $mathcal{O}(min (kappa^3epsilon^{-3},kappa^2 sqrt{N} epsilon^{-2} ))$ stochastic first-order oracle (SFO) calls and $tilde{mathcal{O}}(kappa^2 epsilon^{-2})$ communication rounds, where $kappa$ is the condition number and $N$ is the total number of individual functions. Our numerical experiments also validate the superiority of DREAM over previous methods.
5/15/2024
🛠️
Adaptive and Optimal Second-order Optimistic Methods for Minimax Optimization
Ruichen Jiang, Ali Kavis, Qiujiang Jin, Sujay Sanghavi, Aryan Mokhtari
0
0
We propose adaptive, line search-free second-order methods with optimal rate of convergence for solving convex-concave min-max problems. By means of an adaptive step size, our algorithms feature a simple update rule that requires solving only one linear system per iteration, eliminating the need for line search or backtracking mechanisms. Specifically, we base our algorithms on the optimistic method and appropriately combine it with second-order information. Moreover, distinct from common adaptive schemes, we define the step size recursively as a function of the gradient norm and the prediction error in the optimistic update. We first analyze a variant where the step size requires knowledge of the Lipschitz constant of the Hessian. Under the additional assumption of Lipschitz continuous gradients, we further design a parameter-free version by tracking the Hessian Lipschitz constant locally and ensuring the iterates remain bounded. We also evaluate the practical performance of our algorithm by comparing it to existing second-order algorithms for minimax optimization.
6/5/2024