Secure Traffic Sign Recognition: An Attention-Enabled Universal Image Inpainting Mechanism against Light Patch Attacks

0
Sign in to get full access
Overview
- This paper proposes a secure traffic sign recognition system that uses an attention-enabled universal image inpainting mechanism to defend against adversarial light patch attacks.
- The system aims to improve the robustness and reliability of traffic sign recognition, which is crucial for public safety applications like autonomous vehicles.
- The proposed defense mechanism leverages an inpainting model to remove or obscure adversarial light patches that could be used to fool a traffic sign recognition model.
Plain English Explanation
The paper describes a way to make traffic sign recognition systems more secure and reliable. Traffic sign recognition is an important technology for self-driving cars and other applications, as it allows computers to accurately identify road signs.
However, these systems can be fooled by adversarial attacks that use carefully crafted "light patches" to trick the recognition model. The proposed system uses an "inpainting" technique to automatically detect and remove these light patches before they can confuse the traffic sign recognition.
The inpainting model is designed to be "universal", meaning it can work with a variety of traffic sign recognition models without needing to be retrained for each one. It also uses an "attention" mechanism to focus on the most important parts of the image, helping it identify and remove the adversarial light patches more effectively.
By making traffic sign recognition more robust to these types of attacks, the system aims to improve the safety and reliability of autonomous vehicles and other applications that rely on accurate traffic sign identification.
Technical Explanation
The paper introduces a secure traffic sign recognition framework that incorporates an attention-enabled universal image inpainting mechanism to defend against adversarial light patch attacks.
The key components of the system are:
-
Attention-Enabled Inpainting Module: This module uses an attention mechanism to focus on the most important regions of the input image, allowing it to effectively identify and remove adversarial light patches. The inpainting model is designed to be "universal", meaning it can work with different traffic sign recognition models without retraining.
-
Universal Inpainting Mechanism: The inpainting model is trained on a diverse dataset of traffic sign images, both clean and with adversarial light patches. This allows the model to learn a robust inpainting strategy that can generalize to a wide range of traffic sign recognition models and attack scenarios.
-
Secure Traffic Sign Recognition Pipeline: The complete system integrates the attention-enabled inpainting module with a traffic sign recognition model. When an input image is provided, the inpainting module first analyzes the image and removes any detected adversarial light patches. The preprocessed image is then passed to the traffic sign recognition model for classification.
The authors evaluate the proposed system on several standard traffic sign recognition benchmarks and show that it can effectively defend against a variety of adversarial light patch attacks while maintaining high recognition accuracy on clean images.
Critical Analysis
The paper presents a promising approach to improving the security and reliability of traffic sign recognition systems, which is an important concern for the deployment of autonomous vehicles and other safety-critical applications.
One key strength of the proposed system is its "universality", which allows the inpainting module to work with different traffic sign recognition models without the need for retraining. This can help streamline the deployment and integration of the defense mechanism across a variety of systems.
However, the paper does not discuss the potential computational overhead or performance impact of incorporating the inpainting module into the recognition pipeline. This is an important consideration, as any added latency or processing requirements could limit the practical applicability of the system, especially in real-time applications like autonomous driving.
Additionally, the authors only evaluate the system against adversarial light patch attacks and do not consider other types of adversarial attacks, such as those that use more complex or imperceptible perturbations. Further research is needed to assess the robustness of the system against a broader range of adversarial threats.
Conclusion
The proposed secure traffic sign recognition framework, with its attention-enabled universal image inpainting mechanism, represents a promising step towards improving the security and reliability of this critical technology. By effectively defending against adversarial light patch attacks, the system can help ensure the safe and accurate operation of autonomous vehicles and other applications that rely on robust traffic sign recognition.
While the paper demonstrates the effectiveness of the approach, further research is needed to address potential performance and scalability concerns, as well as to evaluate the system's resilience against a wider range of adversarial attacks. Continued advancements in this area can contribute to the realization of safer and more trustworthy computer vision systems for transportation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Secure Traffic Sign Recognition: An Attention-Enabled Universal Image Inpainting Mechanism against Light Patch Attacks
Hangcheng Cao, Longzhi Yuan, Guowen Xu, Ziyang He, Zhengru Fang, Yuguang Fang
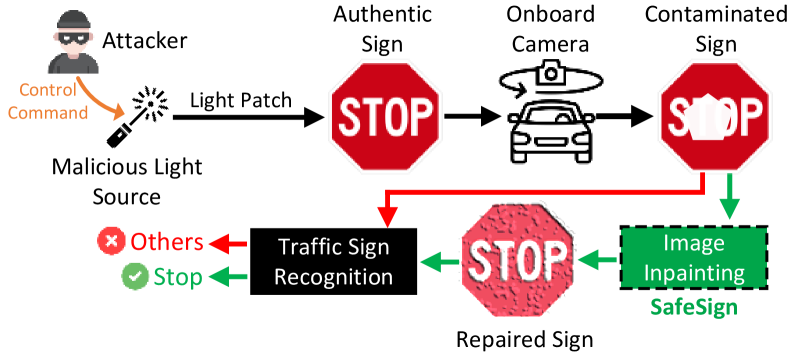
Traffic sign recognition systems play a crucial role in assisting drivers to make informed decisions while driving. However, due to the heavy reliance on deep learning technologies, particularly for future connected and autonomous driving, these systems are susceptible to adversarial attacks that pose significant safety risks to both personal and public transportation. Notably, researchers recently identified a new attack vector to deceive sign recognition systems: projecting well-designed adversarial light patches onto traffic signs. In comparison with traditional adversarial stickers or graffiti, these emerging light patches exhibit heightened aggression due to their ease of implementation and outstanding stealthiness. To effectively counter this security threat, we propose a universal image inpainting mechanism, namely, SafeSign. It relies on attention-enabled multi-view image fusion to repair traffic signs contaminated by adversarial light patches, thereby ensuring the accurate sign recognition. Here, we initially explore the fundamental impact of malicious light patches on the local and global feature spaces of authentic traffic signs. Then, we design a binary mask-based U-Net image generation pipeline outputting diverse contaminated sign patterns, to provide our image inpainting model with needed training data. Following this, we develop an attention mechanism-enabled neural network to jointly utilize the complementary information from multi-view images to repair contaminated signs. Finally, extensive experiments are conducted to evaluate SafeSign's effectiveness in resisting potential light patch-based attacks, bringing an average accuracy improvement of 54.8% in three widely-used sign recognition models
Read more9/9/2024

0
Invisible Optical Adversarial Stripes on Traffic Sign against Autonomous Vehicles
Dongfang Guo, Yuting Wu, Yimin Dai, Pengfei Zhou, Xin Lou, Rui Tan
Camera-based computer vision is essential to autonomous vehicle's perception. This paper presents an attack that uses light-emitting diodes and exploits the camera's rolling shutter effect to create adversarial stripes in the captured images to mislead traffic sign recognition. The attack is stealthy because the stripes on the traffic sign are invisible to human. For the attack to be threatening, the recognition results need to be stable over consecutive image frames. To achieve this, we design and implement GhostStripe, an attack system that controls the timing of the modulated light emission to adapt to camera operations and victim vehicle movements. Evaluated on real testbeds, GhostStripe can stably spoof the traffic sign recognition results for up to 94% of frames to a wrong class when the victim vehicle passes the road section. In reality, such attack effect may fool victim vehicles into life-threatening incidents. We discuss the countermeasures at the levels of camera sensor, perception model, and autonomous driving system.
Read more7/11/2024

0
SafePaint: Anti-forensic Image Inpainting with Domain Adaptation
Dunyun Chen, Xin Liao, Xiaoshuai Wu, Shiwei Chen
Existing image inpainting methods have achieved remarkable accomplishments in generating visually appealing results, often accompanied by a trend toward creating more intricate structural textures. However, while these models excel at creating more realistic image content, they often leave noticeable traces of tampering, posing a significant threat to security. In this work, we take the anti-forensic capabilities into consideration, firstly proposing an end-to-end training framework for anti-forensic image inpainting named SafePaint. Specifically, we innovatively formulated image inpainting as two major tasks: semantically plausible content completion and region-wise optimization. The former is similar to current inpainting methods that aim to restore the missing regions of corrupted images. The latter, through domain adaptation, endeavors to reconcile the discrepancies between the inpainted region and the unaltered area to achieve anti-forensic goals. Through comprehensive theoretical analysis, we validate the effectiveness of domain adaptation for anti-forensic performance. Furthermore, we meticulously crafted a region-wise separated attention (RWSA) module, which not only aligns with our objective of anti-forensics but also enhances the performance of the model. Extensive qualitative and quantitative evaluations show our approach achieves comparable results to existing image inpainting methods while offering anti-forensic capabilities not available in other methods.
Read more8/7/2024
0
Revolutionizing Traffic Sign Recognition: Unveiling the Potential of Vision Transformers
Susano Mingwin, Yulong Shisu, Yongshuai Wanwag, Sunshin Huing
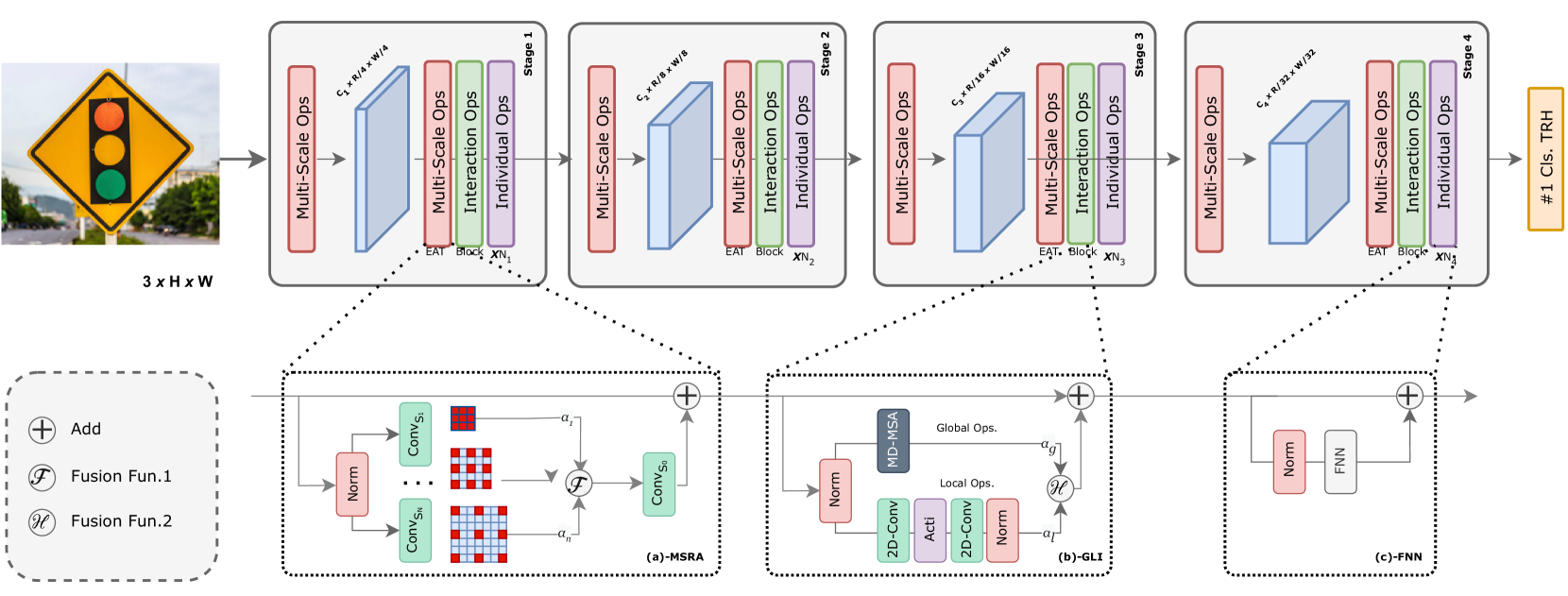
This research introduces an innovative method for Traffic Sign Recognition (TSR) by leveraging deep learning techniques, with a particular emphasis on Vision Transformers. TSR holds a vital role in advancing driver assistance systems and autonomous vehicles. Traditional TSR approaches, reliant on manual feature extraction, have proven to be labor-intensive and costly. Moreover, methods based on shape and color have inherent limitations, including susceptibility to various factors and changes in lighting conditions. This study explores three variants of Vision Transformers (PVT, TNT, LNL) and six convolutional neural networks (AlexNet, ResNet, VGG16, MobileNet, EfficientNet, GoogleNet) as baseline models. To address the shortcomings of traditional methods, a novel pyramid EATFormer backbone is proposed, amalgamating Evolutionary Algorithms (EAs) with the Transformer architecture. The introduced EA-based Transformer block captures multi-scale, interactive, and individual information through its components: Feed-Forward Network, Global and Local Interaction, and Multi-Scale Region Aggregation modules. Furthermore, a Modulated Deformable MSA module is introduced to dynamically model irregular locations. Experimental evaluations on the GTSRB and BelgiumTS datasets demonstrate the efficacy of the proposed approach in enhancing both prediction speed and accuracy. This study concludes that Vision Transformers hold significant promise in traffic sign classification and contributes a fresh algorithmic framework for TSR. These findings set the stage for the development of precise and dependable TSR algorithms, benefiting driver assistance systems and autonomous vehicles.
Read more5/1/2024