Segment Anything Model for Road Network Graph Extraction

0

Sign in to get full access
Overview
- This paper presents a novel approach for extracting road network graphs from satellite imagery using the Segment Anything Model (SAM), a powerful deep learning model developed by Anthropic.
- The method leverages SAM's ability to segment any object in an image, allowing it to accurately delineate road networks without the need for specialized training data or hand-crafted features.
- The researchers demonstrate the effectiveness of their approach on various real-world datasets, showcasing its potential for automating the process of road network extraction from remote sensing data.
Plain English Explanation
The paper introduces a new way to extract road networks from satellite images using a deep learning model called the Segment Anything Model (SAM). SAM is a powerful AI system that can identify and outline any object in an image, even if it hasn't been specifically trained to recognize that object before.
The researchers took advantage of SAM's versatility to accurately delineate road networks without needing specialized training data or manually engineered features. This is a significant advancement over traditional methods, which often require extensive human effort to annotate road networks in large-scale datasets.
By applying SAM to satellite imagery, the researchers were able to automatically extract road networks in a robust and efficient manner. They tested their approach on various real-world datasets, demonstrating its effectiveness and potential for automating the process of road network extraction from remote sensing data.
Technical Explanation
The paper presents a method for using the Segment Anything Model (SAM) to extract road network graphs from satellite imagery. SAM is a deep learning model developed by Anthropic that can segment any object in an image, regardless of whether it has been trained on that specific object before.
The researchers leveraged SAM's zero-shot segmentation capabilities to delineate road networks without the need for specialized training data or hand-crafted features. This is a significant advantage over traditional methods, which often require extensive manual effort to annotate road networks in large-scale datasets.
The proposed approach involves using SAM to generate segmentation masks for the road network in a given satellite image. These masks are then post-processed to extract a graph representation of the road network, which can be used for various applications, such as navigation, urban planning, and infrastructure monitoring.
The researchers evaluated their method on several real-world datasets, including road networks in both urban and rural areas. The results demonstrate the effectiveness of their approach, with the ability to accurately capture the complex geometry and connectivity of road networks without relying on prior knowledge or manual annotation.
Critical Analysis
The paper presents a compelling approach for automating the process of road network extraction from satellite imagery. The use of the Segment Anything Model (SAM) is a promising solution, as it allows for the segmentation of road networks without the need for specialized training data or hand-crafted features.
However, the paper does not extensively discuss the limitations or potential caveats of the proposed method. For example, it would be useful to understand how the approach performs in challenging conditions, such as areas with dense vegetation, complex road geometries, or poor image quality. Additionally, the paper could benefit from a more detailed analysis of the error modes and failure cases of the system.
Furthermore, while the researchers demonstrate the effectiveness of their approach on various real-world datasets, it would be valuable to see a comparison with other state-of-the-art road network extraction methods. This could help to provide a more comprehensive understanding of the relative strengths and weaknesses of the proposed technique.
Overall, the paper presents a novel and potentially impactful contribution to the field of remote sensing and geospatial analysis. However, further research and analysis would be helpful to fully assess the limitations and broader implications of the Segment Anything Model (SAM)-based approach for road network extraction.
Conclusion
This paper introduces a novel method for extracting road network graphs from satellite imagery using the Segment Anything Model (SAM), a powerful deep learning model developed by Anthropic. The key innovation of the proposed approach is its ability to delineate road networks without the need for specialized training data or hand-crafted features, thanks to SAM's zero-shot segmentation capabilities.
The researchers demonstrate the effectiveness of their method on various real-world datasets, showcasing its potential for automating the process of road network extraction from remote sensing data. This could have significant implications for a wide range of applications, including urban planning, infrastructure monitoring, and transportation optimization.
While the paper presents a compelling solution, further research and analysis would be valuable to fully understand the limitations and broader implications of the Segment Anything Model (SAM)-based approach for road network extraction. Nonetheless, this work represents an important step forward in the field of geospatial analysis and remote sensing, with the potential to significantly streamline the process of mapping and monitoring road networks at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Segment Anything Model for Road Network Graph Extraction
Congrui Hetang, Haoru Xue, Cindy Le, Tianwei Yue, Wenping Wang, Yihui He
We propose SAM-Road, an adaptation of the Segment Anything Model (SAM) for extracting large-scale, vectorized road network graphs from satellite imagery. To predict graph geometry, we formulate it as a dense semantic segmentation task, leveraging the inherent strengths of SAM. The image encoder of SAM is fine-tuned to produce probability masks for roads and intersections, from which the graph vertices are extracted via simple non-maximum suppression. To predict graph topology, we designed a lightweight transformer-based graph neural network, which leverages the SAM image embeddings to estimate the edge existence probabilities between vertices. Our approach directly predicts the graph vertices and edges for large regions without expensive and complex post-processing heuristics, and is capable of building complete road network graphs spanning multiple square kilometers in a matter of seconds. With its simple, straightforward, and minimalist design, SAM-Road achieves comparable accuracy with the state-of-the-art method RNGDet++, while being 40 times faster on the City-scale dataset. We thus demonstrate the power of a foundational vision model when applied to a graph learning task. The code is available at https://github.com/htcr/sam_road.
Read more4/16/2024
📈
0
Segment Anything Model is a Good Teacher for Local Feature Learning
Jingqian Wu, Rongtao Xu, Zach Wood-Doughty, Changwei Wang, Shibiao Xu, Edmund Y. Lam
Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in any scene and any downstream task. Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Attention-weighted Semantic Relation Distillation (ASRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
Read more6/19/2024

0
Segment-Anything Models Achieve Zero-shot Robustness in Autonomous Driving
Jun Yan, Pengyu Wang, Danni Wang, Weiquan Huang, Daniel Watzenig, Huilin Yin
Semantic segmentation is a significant perception task in autonomous driving. It suffers from the risks of adversarial examples. In the past few years, deep learning has gradually transitioned from convolutional neural network (CNN) models with a relatively small number of parameters to foundation models with a huge number of parameters. The segment-anything model (SAM) is a generalized image segmentation framework that is capable of handling various types of images and is able to recognize and segment arbitrary objects in an image without the need to train on a specific object. It is a unified model that can handle diverse downstream tasks, including semantic segmentation, object detection, and tracking. In the task of semantic segmentation for autonomous driving, it is significant to study the zero-shot adversarial robustness of SAM. Therefore, we deliver a systematic empirical study on the robustness of SAM without additional training. Based on the experimental results, the zero-shot adversarial robustness of the SAM under the black-box corruptions and white-box adversarial attacks is acceptable, even without the need for additional training. The finding of this study is insightful in that the gigantic model parameters and huge amounts of training data lead to the phenomenon of emergence, which builds a guarantee of adversarial robustness. SAM is a vision foundation model that can be regarded as an early prototype of an artificial general intelligence (AGI) pipeline. In such a pipeline, a unified model can handle diverse tasks. Therefore, this research not only inspects the impact of vision foundation models on safe autonomous driving but also provides a perspective on developing trustworthy AGI. The code is available at: https://github.com/momo1986/robust_sam_iv.
Read more8/20/2024
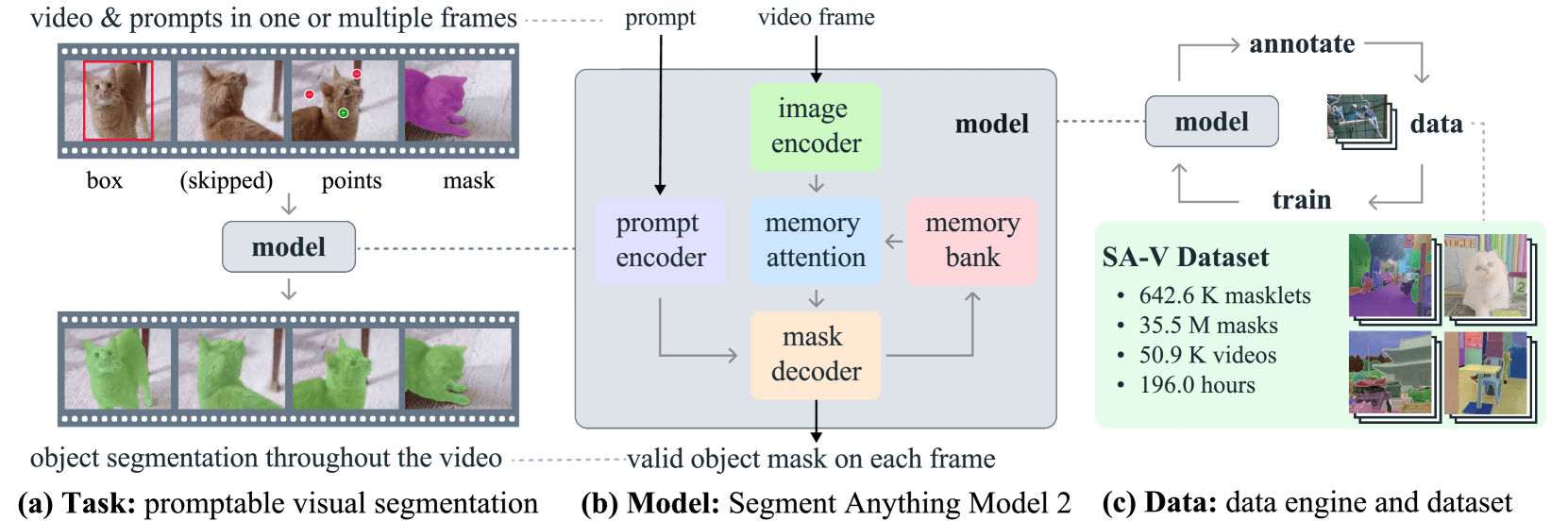
0
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Radle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll'ar, Christoph Feichtenhofer
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Read more8/2/2024